
ML Case-study Interview Question: Proactively Flagging Abusive Threads Using Transformers and Behavioral Signals


Browse all the ML Case-Studies here.
Case-Study question
A neighborhood-based platform seeks to reduce harmful and hurtful user comments. Many of these comments cluster in specific conversation threads, triggering negative feedback loops. The platform wants to build a model that predicts the likelihood a conversation thread will become abusive. They plan to use text embeddings from multilingual transformer models and user behavioral signals. They want you to propose a comprehensive end-to-end solution, including data labeling, sampling strategy, model architecture, and deployment approach. How would you design this solution, what interventions would you build, and how would you measure impact?
Detailed Solution
This platform wants a way to identify conversation threads that may turn abusive and prevent escalation. The system should flag high-risk threads early, so product features can remind users to reconsider their tone. Below is a thorough explanation of how to structure such a solution.
Defining “Abusive” Content
Abusive content includes personal attacks, discriminatory language, fraud, or misinformation. User reports serve as a proxy label indicating potentially abusive content. Even if the platform moderators do not remove the content, a report means someone found it problematic.
Data and Labeling
User reports mark comments as suspicious. Label a thread as “high risk” if it eventually contains reported comments. This approach helps model early signs of incivility. Data is highly imbalanced since fewer than 1% of all comments are typically reported. Oversample threads with reported content. Include an appropriate sample of non-reported threads for negative labels.
Sampling Strategy
Threads with many reported comments can dominate the data. Random sampling risks missing smaller or less active threads. One method: sample entire posts, then sample threads within those posts. Oversample threads with reported comments to ensure adequate representation of positive labels. This preserves the thread distribution in realistic proportions.
Model Architecture
Represent text using embeddings from a multilingual transformer model. Each comment’s text is converted into a dense vector. Augment these vectors with user-level signals such as report history or comment velocity. Concatenate embeddings of the conversation context (including mentions, replies, and sequential order). Pass this concatenation into a dense layer that outputs a risk score for the thread.
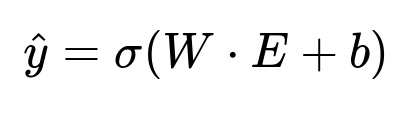
Here:
E is the concatenated embedding of all relevant comment vectors in the thread.
W and b are trainable parameters in the dense layer.
sigma is a sigmoid activation giving a probability (risk score) for whether the thread may turn abusive.
The training target is whether a subsequent comment in that thread becomes reported. The system does not know the new comment text in advance, so the model learns early signals of potential escalation.
Implementation Flow
Extract raw comment data. Map each comment to an embedding vector using a multilingual transformer library. Construct a thread-level representation that captures mention tags, hierarchical replies, and comment order. Feed this into a dense layer for classification. Store the thread risk scores in a feature store or cache so the application can access them.
Intervention Mechanisms
When the thread risk score exceeds a threshold, the platform can slow down or discourage aggressive replies. Examples:
Turn off notifications for subsequent replies in the high-risk thread.
Prompt the user with a reminder to keep the conversation constructive.
Notify the post author that they can close the thread or moderate content.
Measuring Impact
Compare metrics such as the volume of newly reported comments, the fraction of incivility across flagged threads, and user engagement after warnings. Also measure precision and recall for detection. Investigate user sentiment and satisfaction with content. Evaluate how many potential abusive incidents were diffused or prevented.
Internationalization
Leverage multilingual transformer embeddings. Fine-tune on data from one country if that is most abundant. Test it in other languages. If performance is acceptable, deploy the same model. Track local differences in user reporting behavior. If certain languages see lower precision or recall, consider partial retraining or domain adaptation.
Example Python Snippet Explanation
You can build and score the model with a pipeline like this:
import torch
from sentence_transformers import SentenceTransformer
import torch.nn as nn
transformer_model = SentenceTransformer('sentence-transformers/****-multilingual-model')
classifier = nn.Sequential(
nn.Linear(768, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def compute_thread_embedding(comments):
# comments is a list of strings
# transform them to embeddings, then aggregate
embeddings = transformer_model.encode(comments, convert_to_tensor=True)
# in practice, gather conversation structure signals and combine
thread_representation = torch.mean(embeddings, dim=0)
return thread_representation
def forward_pass(thread_representation):
score = classifier(thread_representation)
return score
# Example usage:
sample_comments = ["I disagree with your point", "This is untrue and misleading", "You are clueless"]
rep = compute_thread_embedding(sample_comments)
risk_score = forward_pass(rep)
This code runs inference for a single thread. It aggregates comment embeddings by averaging them, then feeds them into a small feed-forward network. Production deployments will likely cache embeddings and run the risk scoring asynchronously.
Possible Follow-up Questions
How would you handle imbalanced data more effectively?
Use a combination of oversampling or undersampling on the minority/majority classes. Consider generating synthetic samples if appropriate. Keep the distribution of thread sizes intact and ensure variety in the data. Monitor precision and recall on a validation set. Use methods like ROC curves or Precision-Recall curves to select the optimal threshold.
Why not remove the reported content instead of nudging users?
Immediate removal can backfire if moderators remove borderline content or if removing content is perceived as censorship. The goal is to preserve constructive discourse while minimizing harm. Nudges let people self-correct and remain in the conversation. Also, reported content might not violate guidelines, so warnings encourage gentler engagement without automatically deleting content.
How do you address computational cost at scale?
Generate embeddings in real time only if needed, or precompute them in scheduled batches. Cache thread embeddings to serve multiple downstream systems. Since many threads never escalate, only refresh the cache on threads that cross certain interaction thresholds.
How do you measure success when not all abusive content is reported?
Define multiple metrics. Use user reports as one signal, plus random sampling with human reviewers for ground truth. Track how the intervention changes the volume of overall toxicity. Evaluate user satisfaction or retention. Correlate the model’s score distribution with external measurements of incivility from manual review.
What if your model flags many conversations that do not get reported?
False positives can still be beneficial if they intercept borderline cases. People might have toned down their replies after seeing a reminder, so the conversation never escalated. Confirm with periodic checks and user feedback to ensure the tool is not overly restrictive.
How would you adapt the model for new languages or emerging local issues?
Keep the transformer approach to leverage multilingual alignment. Continuously update the embeddings. Retrain or fine-tune with region-specific data to capture local slang or cultural references. Partner with local experts or moderators to label new data. Monitor country-specific performance to see if a specialized model is needed.
How do you ensure real-time updates?
Use asynchronous pipelines. Ingest new comments into a queue. Trigger a job that updates the thread-level score. Store results for the product services to consume. Real-time might not be needed if the user interface only requires the updated score when someone starts to reply.
How do you handle privacy and ethical considerations?
Anonymize text wherever possible. Use minimal personal data. Provide transparency about why certain interventions appear. Let users control how they participate or close their threads. Continually audit the model for potential biases. Ensure fairness across demographic groups and language communities.