
ML Case-study Interview Question: Architecting High-Scale Social Feeds: Neural Ranking, Embeddings & Candidate Sourcing


Browse all the ML Case-Studies here.
Case-Study question
Your large-scale social media platform processes over 500 million short posts daily. You need to build and maintain a recommendation system that selects the top posts for each user's feed. You must retrieve relevant posts from both the user's followed network and from users they do not follow. Then you must rank those posts using robust models, apply filters and heuristics, and blend them into a final feed. Propose a complete end-to-end solution architecture to accomplish this. Describe in detail how you would:
Collect posts and generate a pool of likely candidates for each user from both their network and beyond.
Rank these candidates to maximize engagement.
Apply filtering, diversification, and balancing rules.
Handle high traffic and strict latency requirements.
Measure system performance and iterate on the models over time.
Detailed solution
A modern system uses these stages: candidate sourcing, ranking, heuristics/filters, and final blending. A backend service (written in a language suited for high concurrency) orchestrates interactions among these stages.
Candidate Sourcing
Candidate sourcing pulls a manageable set of posts (often around 1500) from an enormous daily flow. One category comes from authors the user follows (in-network). Another category comes from authors the user does not follow (out-of-network).
In-network sourcing often uses a logistic regression model to pick recent posts from followed users. A core component is a user-user relationship score. A separate service scores each possible author-user pair. A high score indicates a strong connection. The in-network candidate selector uses that score to prioritize relevant posts.
Out-of-network sourcing uses two key approaches. One approach is graph-based: it looks at the posts that users (similar to you or those you already follow) have recently liked or reposted. Another approach uses embeddings. A matrix factorization or neural embedding engine assigns vectors to users and posts, then measures similarity. A well-known matrix factorization concept factors a user-item matrix M into two low-dimensional matrices U and V such that each element M_{ij} ~ U_i dot V_j. This can cluster similar content and recommend posts that align with the user’s embedding.
A matrix factorization example:
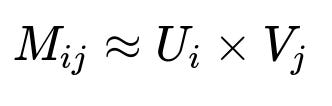
M_{ij} represents how user i interacts with post j. U_{i} is the embedding vector for user i. V_{j} is the embedding vector for post j. Larger dot products indicate stronger affinity. The platform updates these embeddings periodically or in real time.
Ranking
The ranking model assigns a relevance score to each candidate. A neural network with tens of millions of parameters can estimate the probability of different user engagement outcomes. Logistic regression is still used in simpler submodules. For instance, an inline logistic function is:
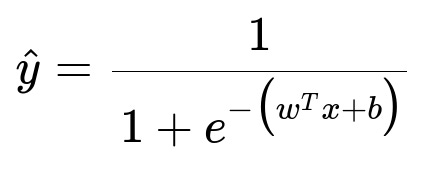
w is the learned weight vector, x is the feature vector (e.g. user-post features), b is the bias term, and e is the base of the natural logarithm. This function outputs the probability of a positive engagement event. A larger neural network might predict multiple events (like, comment, share) at once. After computing the probabilities, the system ranks posts by a weighted combination (e.g. predicted like probability + some weight * predicted reply probability).
A simple Python snippet (illustrative) for a logistic regression model training step:
import numpy as np
from sklearn.linear_model import LogisticRegression
X = np.array([[0.1, 1.2], [1.1, 3.2], [2.0, 1.5]]) # feature vectors
y = np.array([0, 1, 1]) # engagement labels
model = LogisticRegression()
model.fit(X, y)
predicted_prob = model.predict_proba([[1.0, 2.5]])
print(predicted_prob)
This snippet trains a basic logistic regression on small synthetic data. Real systems incorporate high-dimensional features describing user behavior, post content, user-user relationships, timing, etc.
Heuristics and Filters
After computing scores, the system discards undesirable or redundant posts. It removes blocked users’ content and categories the user chose to avoid. It also applies constraints so that posts from the same author do not appear consecutively too many times. It balances the feed with around half in-network and half out-of-network content, adjusted by user engagement patterns. It downgrades posts that received negative feedback from the viewer. It also ensures some form of second-degree connection if out-of-network posts are shown.
Blending and Serving
A single aggregator service merges the final set of posts with ads, recommendations to follow new people, or prompts. That feed is sent to the user in real time. The service must handle billions of daily feed-generation requests, so it must optimize concurrency, caching, and minimal data transfer. Latency targets often require the entire recommendation pipeline (candidate retrieval, model scoring, filtering) to complete in under a couple of seconds.
Follow-up questions and answers
How would you handle users with few or no existing connections?
For cold-start users, the system has limited historical behavior. A fallback is to rely on general popularity signals, trending topics, or broad embedding clusters. Once the user starts interacting, each engagement refines their embedding vector. Another approach is to rely on user demographics or inferred interests from the sign-up flow. Early data helps seed an initial preference vector.
How do you maintain up-to-date embeddings while handling huge volumes of posts?
Matrix factorization or neural embedding systems typically run on distributed infrastructures. Incremental updates happen through minibatch training on streaming data. The system schedules periodic large-scale retraining, but also performs micro-updates on hot events. Real-time or near-real-time engines store a rolling window of interactions to adjust user or post vectors quickly. Consistency is managed by versioning the model and gradually rolling out updates to keep the pipeline stable.
What if the logistic regression model is outdated or not capturing complex interactions?
A multi-task neural network is a stronger alternative. It can learn complex patterns across user features, post features, and historical data. The model can predict multiple engagement probabilities in a single forward pass, capturing correlations among these events. It can also incorporate deep embeddings for user or post data to learn non-linear mappings.
How can you ensure you respect user preferences and moderation?
A visibility filtering service is placed at the end of the pipeline. It removes blocked content, explicit media if the user opts out, repeated spam posts, and other restricted topics. The aggregator enforces the user’s block or mute lists. It also checks for content that triggers trust and safety policies or must be flagged for review.
How would you handle negative feedback on recommended posts?
The ranking model can use implicit negative signals (fast scrolling past the post, hitting “Not Interested”) and explicit negative signals (user blocking or muting an account). The system captures this feedback and lowers relevance for related content. The feed aggregator might treat repeated negative signals as a strong penalty and filter out similar future posts. Model training includes examples of these negative interactions to better predict which posts are less likely to appeal to the user.
What is your approach to real-time performance when scaling?
Caching is essential. The aggregator caches the results of expensive operations, such as user embeddings, hot post features, or partial model inferences. It also parallelizes candidate retrieval from multiple sources. The ranking service runs on robust hardware accelerators (GPUs or specialized chips) for neural network inference. Strict timeouts ensure no single stage blocks the request too long. The system logs latencies at each stage and triggers alerts if they exceed thresholds.
How do you verify that recommendations improve user satisfaction?
Online metrics can track engagement rate, time spent, return visits, and user surveys. Offline, you compare new models against baseline models in controlled A/B tests. The platform might define an objective metric like “weighted engagement” combining likes, shares, or replies. If the new model outperforms the baseline and maintains user retention, it can be deployed widely. Monitoring ensures no regression in diversity, fairness, or other constraints.
How do you handle large-scale data ingestion and training?
Data pipelines ingest continuous streams of user actions. A message queue system handles the massive throughput. A feature store merges raw logs, user features, and post features. Distributed training frameworks ingest minibatches for gradient-based updates on cluster nodes. Model artifacts are versioned and kept in a centralized repository for seamless rollout.
What if you must adapt quickly to sudden trends or events?
A real-time indexing service flags high-velocity posts (e.g., live sports or breaking news). Embedding-based similarity captures emerging interests among active users. The aggregator recognizes fast-rising interactions and surfaces those posts more. A short sliding window model can pick up on ephemeral trends. On the user side, measuring dwell time or repeated visits can confirm if they are interested in the emerging topic. The system weights those signals promptly in the ranking stage.
How would you keep your system maintainable as features expand?
Modular design is critical. Each pipeline stage has a well-defined role. The aggregator service simply orchestrates candidate sources, ranking modules, and filters. New features or additional signals can be plugged in with minimal disruption. A separate configuration layer can specify how each candidate source or ranking model is combined. Continuous integration and testing ensure each pipeline update does not break the end-to-end feed generation.
How do you mitigate biased or misleading content in user feeds?
A fairness or safety submodule reviews content for sensitive or harmful topics. The ranking model can penalize or filter content flagged by certain keywords, user reports, or third-party fact-checks. The platform can incorporate fairness constraints ensuring diverse viewpoints or authors. Continuous analysis of model outputs is important to detect unintended biases. Periodic audits track performance across user demographics and refine features or weighting if certain groups are under-served or over-penalized.
How do you manage user satisfaction if you keep showing them out-of-network content?
A balance is enforced between in-network and out-of-network posts. The aggregator aims for roughly a 50-50 split, but user feedback can tilt this ratio. If out-of-network content sees low engagement, the model gradually reduces its portion. The model also ensures that out-of-network posts have some second-degree link (e.g., liked or followed by someone the user trusts), unless strong global signals justify showing them. This keeps the feed relevant while still discovering new interests.