
ML Case-study Interview Question: De-duplicating E-commerce Catalogs at Scale with Text/Image Embeddings and FAISS


Browse all the ML Case-Studies here.
Case-Study question
You are leading a data science team at a major e-commerce marketplace that faces issues with duplicate items cluttering the product catalog. Each duplicate item degrades user experience and distorts the catalog quality. You must design a solution that identifies and merges these duplicates using text and image information at scale. How would you approach this problem from end to end, including candidate retrieval, similarity computations, and system deployment?
Detailed Solution
Overview
This marketplace must handle millions of items. A naive item-to-item comparison approach has a time complexity of
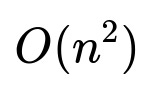
which is infeasible at large scale. Transforming item titles and images into vector representations (embeddings) is more efficient and captures nuanced similarity signals. These embeddings feed into an approximate nearest neighbor system to narrow search candidates.
Text and Image Embeddings
Deep neural networks generate embedding vectors for item titles and product images. The core idea: similar items end up with vectors that are close in Euclidean space. Text embeddings capture brand, product name, and specifications. Image embeddings capture visual identity. Training such deep embeddings usually requires a labeled dataset of matched and non-matched items, but assume these models are already trained.
Candidate Retrieval
Combining text and image embeddings yields a more complete matching signal. Each item’s title embedding and image embedding are stored in an indexing system. FAISS (Facebook AI Similarity Search) supports efficient approximate nearest neighbor lookups even for tens of millions of embeddings. These lookups return top candidates most similar to a given item.
Complementary Value of Multiple Embeddings
Text embeddings often catch duplicates with similar language. Image embeddings often catch duplicates with similar visual patterns. Merging the candidate sets from both embeddings and then filtering via a classifier or thresholding increases overall recall significantly.
To quantify that:
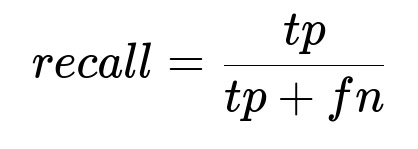
where tp is the count of true positive matches found, and fn is the count of matches missed. Checking multiple embedding sources (text and image) reduces missed matches.
Elasticsearch Baseline
Before deep embeddings, many e-commerce systems rely on Elasticsearch or similar keyword-based engines. These solutions create inverted indexes of words. They can miss duplicates with inconsistent text. The new embedding approach often finds more duplicates because it encodes semantic meaning and visual similarity.
Production Architecture
Indexing pipeline extracts title text and images for each item, computes embeddings, and stores them in a FAISS index. A separate text-based baseline still exists for additional recall. A backend service merges candidate sets and then runs a final match decision model.
Search pipeline handles real-time matching calls. Given an item ID, it fetches its embedding, queries FAISS for the top similar embeddings, and merges them with the baseline system’s candidates. The final step is a binary classifier or rules engine that decides which candidates are duplicates.
Example Python Snippet for FAISS Indexing
Suppose we have precomputed vectors in a NumPy array called vectors of shape (num_items, embedding_dim). We can build a FAISS index like this:
import faiss
import numpy as np
vectors = np.load("your_vectors.npy").astype(np.float32)
dimension = vectors.shape[1]
index = faiss.IndexFlatL2(dimension)
index.add(vectors)
This code builds an index for L2 distance. In a real system, one would use GPU-based indexes or advanced FAISS structures (like IVF or HNSW) for better scalability.
Follow-up Question 1
Why do we combine both text and image embeddings instead of just using one or the other?
Answer Certain products can have very similar text but different images, or nearly identical images but vague text. Text embeddings capture semantic details like brand and model, while image embeddings capture visual identity. Combining them fixes blind spots in either modality alone and returns more true matches (increases recall).
Follow-up Question 2
How would you handle items where the text is incomplete or the images are low resolution?
Answer A fallback strategy is crucial. If the image is low resolution, emphasize text embeddings. If the text is incomplete, rely on image embeddings. You can also consider auxiliary attributes (color, size, brand) to enrich matches. A final model merges all available signals.
Follow-up Question 3
What if the approximate search returns many false positives?
Answer Approximate search retrieves candidates with some error. A secondary classifier or threshold-based filter helps weed out false matches. The classifier can incorporate additional features (price range, product category) before making a final decision.
Follow-up Question 4
How do you maintain performance as the catalog grows to hundreds of millions of items?
Answer Sharding the FAISS index and distributing it across multiple machines is essential. You can also use hierarchical indexing (IVF, HNSW) for faster lookups. Periodic rebalancing and incremental indexing ensure queries remain within acceptable latency bounds.
Follow-up Question 5
How would you measure success beyond recall?
Answer Precision is also important, to avoid merging non-duplicates. You can track the fraction of merged pairs that are actually duplicates. Another key metric is the customer experience feedback, such as search satisfaction or user click-through rates. A holistic view balances high recall with acceptable precision.
Follow-up Question 6
Can this system be extended to other use cases?
Answer Yes. The same text-and-image embedding pipeline can handle similarity-based product recommendations, visual-based product discovery, or even competitor price matching. The underlying methods remain the same: convert items into feature vectors and retrieve similar vectors with an approximate index.
Follow-up Question 7
How would you handle model updates over time?
Answer As new training data arrives or new architectures emerge, a model management system re-trains and deploys updated embedding generators. You can keep multiple model versions in production temporarily and run A/B tests. When you confirm superior performance, migrate items to the newer index.
Follow-up Question 8
If time complexity becomes too high, what strategies can you use?
Answer Approximate nearest neighbor search drastically reduces complexity. Instead of a full pairwise scan, it narrows candidates to a small subset. You might also cache frequently queried embeddings. Another approach is offline batch matching for items that change less often, or employing distributed GPU clusters to parallelize computations.
Follow-up Question 9
Explain the final classifier’s role in ensuring correctness.
Answer The final classifier checks if two items flagged by the approximate search are truly duplicates. It might use text similarity scores, image similarity scores, brand match, and other metadata. By combining multiple features, it filters out near-duplicates that share partial attributes but are not the same product.
Follow-up Question 10
How would you convince leadership of the value in deploying such a system?
Answer Show metrics like improved search precision (less clutter), increased sales (higher trust in search results), and user satisfaction (fewer redundant listings). Also highlight efficiency gains for content management teams. A working prototype that demonstrates recall lift and user experience improvement can further validate ROI.
Use these explanations and approaches to handle tough real-world interviews.