
ML Case-study Interview Question: Classification Guardrails for Fair Housing Compliance in Real Estate LLMs.


Browse all the ML Case-Studies here.
Case-Study question
A major real-estate platform wants to build a conversational Large Language Model tool that advises home-seekers and sellers. Fair housing regulations mandate that protected attributes such as race, religion, disability, and familial status must not influence property recommendations. You need to design and implement a solution that ensures the model never steers users based on protected classes or outputs content that violates fair housing laws. Propose a step-by-step approach. Explain how you would gather training data, design the classifier or guardrails, integrate pre- and post-processing strategies, and keep precision and recall at acceptable levels.
Proposed Solution
A robust approach combines prompt engineering, a stop list, and a separate classification model. Each piece can work together to ensure the model adheres to fair housing laws and avoids non-compliant answers.
Prompt engineering forces the LLM to avoid harmful content by instructing it to never respond in a way that discriminates. This alone might cause excessive refusals of valid queries, so we add other layers.
A stop list handles extremely offensive terms. The system checks input or output text. If it hits certain taboo phrases, the system refuses, no matter what the LLM tries. This rigid approach is too coarse for nuanced contexts, so we still need a classifier.
A trained classifier is more context-aware. A suitable model (like a fine-tuned BERT) checks input and output text for potential violations before final display. Labeling training data requires manual curation of both compliant and non-compliant examples. Additional generation of synthetic data broadens coverage. Experts label queries and responses at the sentence level to avoid throwing out an entire response if only one sentence is discriminatory.
When combining these strategies, the guardrails service calls the classifier and stop list on user input and on the LLM’s answer. If flagged, it returns a refusal or an alternative safe response. This approach balances user experience with strict fairness regulations.
Key Mathematical Expressions
Precision and recall matter for minimizing false positives and false negatives. The classifier must maintain high recall to block all violations, yet not be so aggressive that it refuses legitimate queries.


The training loss often uses binary cross entropy to distinguish compliant from non-compliant classes.
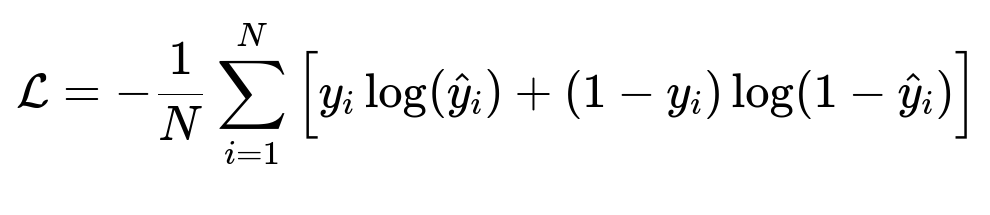
Where y_i is the true label and hat{y}_i is the predicted probability for the positive label.
Example Code Snippet
import torch
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
def classify_text(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=128)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
predicted_class = torch.argmax(logits, dim=1).item()
return predicted_class # 1 for non-compliant, 0 for compliant
sample_query = "Find a neighborhood with no families with young kids"
result = classify_text(sample_query)
if result == 1:
print("Potential violation. Refuse or revise.")
else:
print("Safe to proceed with LLM answer.")
Potential Follow-Up Questions
1) How do you handle ambiguous queries mentioning protected attributes without malicious intent?
Context disambiguation is key. The classifier should look for negative or discriminatory context around protected terms. A mention of “disabilities” in seeking an accessible home is allowed, but “avoid people with disabilities” is not. The classifier learns from labeled examples, capturing actual usage patterns around sensitive words.
2) Why not rely on a stop list alone?
A stop list can catch obvious slurs but fails for phrases that are contextually discriminatory. It can also flag harmless references, blocking useful content. Over-reliance on stop lists can degrade user experience by producing incorrect refusals.
3) How do you maintain strong recall without hurting user experience?
You tune the classifier threshold. Aim for near-100% recall on illegal queries but monitor false positives to reduce unnecessary refusals. You can incorporate a second review path if the classifier is uncertain, or else unify signals from prompt instructions and the classifier to refine decisions.
4) What if the LLM tries to respond with disguised or coded language?
Training data must include examples of indirect references or slang. You can manually create or discover examples of coded racist or discriminatory language. The classifier sees these patterns during training. You also keep iterating: new slang or phrase usage flagged by user feedback is fed back into the labeled dataset.
5) How do you address performance and scaling concerns for real-time chat?
Use a lightweight BERT variant or a distilled Transformer for fast inference. Maintain a separate inference server with GPU or optimized CPU. Cache partial results on repeated queries. The layered approach (stop list + fast classifier) ensures minimal overhead per request.
6) How do you confirm the classifier is correct?
Regular offline evaluations with a test set capturing real user queries. Keep track of precision and recall. Conduct manual audits of flagged queries. Maintain a pipeline for experts to examine borderline cases. If a failure pattern emerges, retrain with additional data.
7) How do you decide what to do if a query is flagged?
Refuse to comply or provide a generic explanation referencing fair housing rules. Optionally, offer a general resource or direct the user to official guidelines. Always ensure the user is not left confused about why their query was refused.
8) How does the system adapt over time?
You collect user feedback. You sample a small subset of queries and the LLM’s final answers. Humans label borderline content, refining the classifier or adjusting prompt instructions. This feedback loop gradually reduces both over-flagging and under-flagging.