
ML Case-study Interview Question: Predicting Churn with ML: Addressing Poor Playback from Outdated Browsers.


Browse all the ML Case-Studies here.
Case-Study question
A large video platform faced user churn when users accessed the service through outdated web browsers. The company collected logs, device metadata, and engagement metrics to understand patterns of latency, playback interruptions, and other experience issues. The task is to design a machine learning solution that pinpoints segments of users at risk of leaving due to poor playback experiences related to outdated browsers. Propose a data-driven approach to identify these users, recommend targeted interventions (such as prompts to update the browser), and measure the effectiveness of these interventions in a production environment. Suggest how you would handle model training, scalability, real-time inference, and ongoing performance monitoring. Provide as many technical details as possible, and discuss any potential challenges.
Detailed solution
A user churn problem arises when a subset of users stops engaging with a service. The platform has logs with playback buffering events, time-to-first-frame, browser version, and session duration. Training a model requires labeling user sessions for churn. Labeling can be done by defining churn as a user who does not return within a fixed time period after an unsatisfactory playback session.
Data ingestion merges historical logs of watch sessions with metadata about browsers. A row can contain user_id, browser_type, browser_version, video_id, start_time, end_time, buffer_count, and playback_error_rate. The target variable is churn_indicator, derived by checking if a user returns within T days.
Feature engineering
Focus on aggregate buffering frequency, average session duration, peak-hour usage, and browser update recency. A rolling average captures how the playback performance changes over time. Engineer a time-since-last-update feature to reflect the gap between the browser’s last known update and current usage. A binary outdated_browser indicator can also be included.
Model selection and training
A classifier can predict the likelihood that a user session leads to eventual churn. Training uses supervised learning. Logistic regression can be effective for interpretability. A deeper model (like a DNN) can capture non-linear relationships.
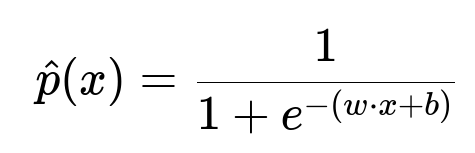
This formula computes the predicted probability of churn for a feature vector x, weight vector w, and bias term b. x represents the feature values (browser version, buffering statistics, session durations). w and b are learnable parameters. The logistic function outputs a probability between 0 and 1.
Hyperparameter tuning involves adjusting regularization strength if using logistic regression or number of layers and units if using neural networks. Use cross-validation to find an optimal configuration. Evaluate with accuracy, precision, recall, and area under the ROC curve. Observe misclassification costs because false negatives (users at risk not flagged) can be serious for retention.
Deployment strategy
A pipeline in a microservices architecture can perform real-time inference. The service receives session data, transforms features, and queries the model for a churn probability. For users with high churn probability, the system triggers an update prompt urging them to install a newer browser version. This pipeline uses a streaming approach with event-based triggers for minimal latency.
A shadow deployment can test the model’s performance on live traffic without affecting users. The system can measure real-time metrics, including how many users seeing the update prompt actually update. A subsequent A/B test compares cohorts of users receiving targeted prompts vs. control groups with no prompt, evaluating changes in churn rate.
Monitoring and maintenance
Monitor drift by regularly checking if the distribution of browser_version and user engagement has changed. A significant shift could mean the model’s weights need recalibration. Automate pipeline retraining at fixed intervals or upon detecting data drift. Keep a robust logging system that captures predictions, user feedback, and actual outcomes to refine future iterations.
Code snippet
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
data = pd.read_csv("user_sessions.csv")
X = data[["buffer_count","avg_session_duration","browser_recency","outdated_browser"]]
y = data["churn_indicator"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred_prob = model.predict_proba(X_test)[:,1]
auc = roc_auc_score(y_test, y_pred_prob)
print("AUC:", auc)
This script trains a logistic regression model on partial features. The code can be extended to include richer features and hyperparameter tuning. The final pipeline can be containerized and exposed through an endpoint for real-time queries.
How would you handle extremely imbalanced data?
Label distribution might be skewed if only a small fraction of users churn. Oversampling methods (e.g., SMOTE) or undersampling can help. Adjusting class weights in the loss function is another strategy. Evaluate metrics beyond simple accuracy. Precision-recall curves are relevant because high precision reduces false positives, and strong recall reduces false negatives.
What if you needed to incorporate sequential patterns?
A user’s watch history, including time-series aspects of buffering and usage frequency, may matter. Recurrent neural networks or Transformers can capture sequential relationships better than a basic regression. Training would require shaping the data into sequences so that the model learns from the ordering of events. A specialized network can handle session-level features and output a churn probability.
How would you personalize the update prompts?
Use the model output to tailor message timing and content. A threshold on churn probability can trigger different intervention intensities. Higher risk might prompt a full-page notice. Lower risk might show a mild in-app banner. Personalization can factor in user’s region, device type, or watch preferences. The system can run an experiment on which prompt style boosts updates and reduces churn. Adjust your model or strategy based on engagement feedback.