
ML Case-study Interview Question: Optimizing Personalized Mobile Notification Timing with Deep Reinforcement Learning


Browse all the ML Case-Studies here.
Case-Study question
A major mobile gaming platform seeks to optimize the timing of daily user notifications. Each user has a distinct schedule and attention pattern. The platform must decide the optimal hour of the day to send each notification to maximize long-term engagement. Your task is to propose a reinforcement learning solution that learns from user response data and continuously improves the notification delivery policy over time. Provide a robust plan detailing how you would design the states, actions, rewards, training loop, and deployment pipeline for this problem. Then explain how you would measure success and handle potential pitfalls.
Detailed Solution
Problem Overview
A popular mobile game sends daily push notifications to remind users to return. People have different time preferences and schedules, making a single fixed time suboptimal. The goal is to personalize the time slot for each user to maximize click-through rate and long-term engagement.
Core Reinforcement Learning Concepts
In reinforcement learning, an agent learns a policy that maximizes cumulative rewards through repeated interaction with an environment. Here, the environment is user behavior, and the actions are the chosen notification hours. The agent observes states representing user history and obtains rewards based on engagement outcomes.
State
For each user, gather features from the recent 14-day history. Include:
Past notification send times
Whether user clicked or ignored the notifications
Time-series data of daily user activity
Action
There are 24 possible actions: the hour of the day to send the notification. The agent must pick the best hour for each user.
Reward
Positive reward when the user clicks the notification. Zero reward otherwise. The agent then learns which hours yield the highest engagement for each user. It also captures long-term effects, because repeated engagement influences future user behavior.
Training Loop
A daily batch training process updates the agent:
Collect the previous day’s actions (which hour was chosen).
Collect the resulting rewards (click or no click).
Build transitions of (state, action, next state, reward).
Update the deep RL model with these transitions.
Generate new action recommendations for the upcoming day.
Model Choice
Deep Q-Network (DQN) often works well for discrete action spaces:
A neural network approximates the Q-function that estimates long-term return for each action.
Exploratory actions are chosen with an epsilon-greedy strategy.
Key DQN Formula
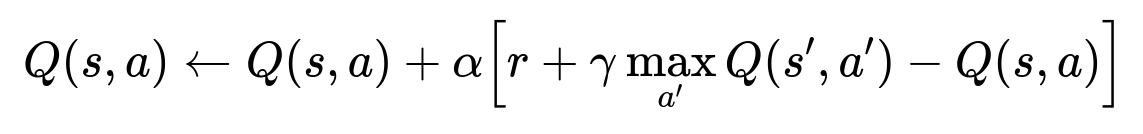
Where:
Q(s,a) is the value of taking action a in state s.
alpha is the learning rate that controls the update step size.
r is the immediate reward from sending the notification.
gamma is the discount factor for future rewards.
s' is the next state after action a is taken.
a' ranges over all possible actions in state s'.
Implementation Details
Use an off-the-shelf framework like TensorFlow Agents to leverage well-tested RL implementations:
Define a neural network that inputs the user’s 14-day interaction history and outputs Q-values for each hour (24 Q-values total).
Train with standard deep learning optimizers (for example, Adam) and tune hyperparameters (learning rate, batch size, epsilon decay).
Maintain an offline data store of user interactions for incremental retraining.
Below is a small illustrative Python snippet for a daily batch workflow:
import tensorflow as tf
import pandas as pd
# Assume we have states_df and actions_df from the previous day
# We also have rewards_df for user click events
def train_dqn_model(states_df, actions_df, rewards_df, model, optimizer):
# Combine data into (state, action, reward) format
# Convert to appropriate TF Tensors
state_tensor = tf.convert_to_tensor(states_df.values, dtype=tf.float32)
action_tensor = tf.convert_to_tensor(actions_df.values, dtype=tf.int32)
reward_tensor = tf.convert_to_tensor(rewards_df.values, dtype=tf.float32)
with tf.GradientTape() as tape:
# Predict Q for all actions
q_values = model(state_tensor)
# Gather Q for the chosen actions
one_hot_actions = tf.one_hot(action_tensor, depth=24)
predicted_q_for_chosen_actions = tf.reduce_sum(q_values * one_hot_actions, axis=1)
# Compute target
# In practice, you would incorporate next state and Q(s', a') for a full DQN update
# This snippet is simplified
loss = tf.reduce_mean((reward_tensor - predicted_q_for_chosen_actions)**2)
grads = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
return loss.numpy()
# Each day, run something like:
# model = your_pretrained_dqn_model
# optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
# daily_loss = train_dqn_model(states_df, actions_df, rewards_df, model, optimizer)
# updated_model = model
Evaluation
Compare click-through rates with a control group that continues using a simple approach (such as sending notifications at a fixed local time). Monitor:
Daily or weekly CTR improvements
Long-term retention metrics
Stability of chosen hours
Practical Pitfalls
Cold-start users with limited data. Consider random exploration or default times until sufficient data is gathered.
Data quality issues (inaccurate time zones or partial logs).
Overfitting to short-term rewards. Careful design of discount factor gamma to account for future user engagement.
Potential Follow-Up Questions
1) How would you handle the exploration-exploitation trade-off in a production environment?
A reinforcement learning agent must try new actions (exploration) but also exploit known best actions. In production, random actions might annoy users if hours are poorly chosen. A typical solution is an epsilon-greedy approach with decaying epsilon:
Start with a higher epsilon to sample a variety of hours for each user.
Gradually reduce epsilon once the agent finds good patterns.
Practical tip: Add constraints for certain hours if domain knowledge suggests they are invalid (such as late nights for a family-friendly game).
2) How do you address delayed rewards, such as user engagement over a week, instead of immediate clicks?
In many scenarios, user re-engagement might manifest several days later. One solution is to incorporate future returns with a discount factor gamma. The Q-learning formula accumulates these future rewards. If we only observe daily click-through, the agent uses that immediate feedback to bootstrap estimates of longer-term engagement. Another approach is to define a custom reward function that includes user activity beyond a single day. This requires carefully engineered data pipelines to track multi-day outcomes.
3) How would you run A/B tests to prove that your RL model is better than the existing approach?
Split the user base randomly:
Control: Retain the old approach (simple segmentation).
Treatment: Use the RL-driven schedule. Measure engagement differences. If the RL group shows significantly higher click-through or retention over a defined test window, that proves efficacy. Statistical significance can be determined with standard A/B testing techniques.
4) Why might a simpler supervised model fail in this scenario?
A supervised model might only predict the immediate click probability at each hour. It would not inherently decide how to act on that prediction to optimize overall engagement. It also fails to learn from repeated trials in a feedback loop. RL directly optimizes the action policy to maximize a long-term metric, making it more adaptive when user behavior shifts.
5) How do you scale the solution to millions of users?
Use a high-throughput pipeline that processes daily logs:
Distributed storage (for example, a data lake) to store interaction data.
Batch or streaming solutions (Spark, Flink, etc.) to transform logs into (state, action, reward) tuples.
Distributed training frameworks (TF-Agents with GPU or TPU acceleration) to handle large datasets.
Model-serving infrastructure that can handle daily updates and compute new notification schedules efficiently.