
ML Case-study Interview Question: Real-Time Rideshare ID Verification Using On-Device ML, OCR & Fraud Detection


Browse all the ML Case-Studies here.
Case-Study question
A major global ridesharing platform operates in regions with high crime rates and frequent incidents involving anonymity. The organization wants to implement a real-time identity verification system that ensures riders submit a legitimate, government-issued ID before requesting rides or restricted deliveries. The system must handle massive global traffic, work under strict data privacy regulations, detect fraudulent IDs in real time, handle latency-sensitive scenarios (like on-demand deliveries), and support multiple ID formats (from national IDs to region-specific driver’s licenses). How would you, as a Senior Data Scientist, design and implement this identity verification solution, ensuring high accuracy, minimal user friction, and scalability across different device capabilities and operating environments?
Detailed Solution
Real-time identity verification requires three main steps: collecting ID images, analyzing these images to check authenticity, and deciding acceptance or rejection in near-real-time. End-to-end, the system must also meet data privacy standards and provide a smooth user experience.
Document Image Collection
Users take a photo of their ID using a mobile device. The application runs an on-device machine learning image-quality check. This step identifies blur, glare, or ID misalignment and guides the user to capture a clear image. A multi-task learning approach handles multiple subtasks (detecting blur, glare, and ID location) with a single shared feature extractor.
To ensure fast inference, the model is quantized and runs in the mobile application’s native environment. If auto-capture fails, users can fall back on manual capture.
Document Image Processing
The captured photo is sent to a backend pipeline. A classification module identifies the ID type. An Optical Character Recognition (OCR) component transcribes key fields such as name, document number, and date of birth. A fraud detection module checks for tampered fonts, mismatched layouts, or suspicious edits.
In some regions, the organization may build in-house document processing for specific ID types. Combining detection models with OCR extracts relevant data and applies post-processing (like removing punctuation or verifying state-level license patterns).
Result Evaluation
The system checks if the ID type is supported. A duplicate-check process compares hashed user data to existing entries. If results are suspicious or confidence is low, the system queues the document for human review. Human agents can verify borderline cases and swiftly determine final acceptance or rejection. Latency is minimized by limiting how often borderline cases occur.
Result Output
A final verification status is pushed to the user through a server-side notification. The platform stores relevant outcomes in an encrypted database with restricted access. Regional retention policies are applied to remove data once it no longer needs to be stored.
Image Quality Improvement
Real-time feedback during the capture step helps users correct issues. Automatic captures decrease the chance of incomplete or blurry images. This approach also reduces the frequency of repeated re-submissions and eliminates user frustration.
Scalability
Different countries have a range of ID types. Some countries use hand-written IDs on paper cards; others have glossy plastic IDs that introduce glare. A modular pipeline and vendor partnerships let the system adapt. On-device models are trained to handle localized variations. Extending to new markets requires additional training data, local testing, and expansions of classification modules.
Data Privacy and Governance
All personally identifiable information is encrypted at rest. Role-based access ensures only authorized investigations can retrieve data. Retention policies differ by jurisdiction. The system flags suspicious activities, but data must comply with each region’s privacy regulations.
Example Code Snippet
Below is a minimal Python example of loading a TFLite model for blur/glare classification. In practice, model loading and input processing would happen in the mobile app environment, but this snippet illustrates a typical flow:
import tensorflow as tf
import numpy as np
from PIL import Image
# Load TFLite model
interpreter = tf.lite.Interpreter(model_path="image_quality_model.tflite")
interpreter.allocate_tensors()
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
def run_inference(image_path):
img = Image.open(image_path).resize((224, 224))
input_data = np.array(img, dtype=np.float32)
input_data = np.expand_dims(input_data, axis=0)
interpreter.set_tensor(input_details[0]['index'], input_data)
interpreter.invoke()
output_data = interpreter.get_tensor(output_details[0]['index'])
return output_data
# Example usage
scores = run_inference("id_photo_example.jpg")
print("Blur score:", scores[0][0], "Glare score:", scores[0][1], "ID-detection score:", scores[0][2])
Potential Follow-up Questions
How does multi-task learning improve efficiency compared to training separate models?
Multiple tasks share a feature extractor, so the network learns a unified representation. Training separate models would require duplicating feature-extraction layers. Sharing a backbone reduces computation and memory consumption. This improves inference speed on mobile devices, where resources are limited.
How do you handle a multi-task loss function during training?
One approach weights each subtask’s loss and sums them to form an overall objective.
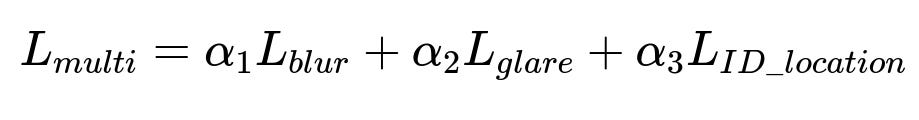
L_{blur}, L_{glare}, L_{ID_location} might be cross-entropy losses for classification tasks. alpha_i are hyperparameters controlling the relative importance of each subtask.
alpha_i can be tuned by validating performance across different tasks. Lower alpha_i for tasks that are simpler or less critical. The training pipeline periodically evaluates metrics for each subtask to refine alpha_i.
How would you deal with extremely low-quality images that pass the client-side check?
Default logic reattempts capture or asks for manual capture. If repeated tries fail, route the document to human review. In data-poor scenarios (low-resolution devices, older hardware), the system might adapt thresholds for blur/glare detection or provide more user guidance.
How does the system detect altered ID fonts or pictures substituted in the ID region?
A fraud detection module checks for mismatched fonts, background artifacts, or layered images. Classifiers can learn to spot unnatural edges, compression artifacts, or visual anomalies. Traditional CV techniques (like edges or text alignment) or advanced neural networks (like domain-specific CNN or Vision Transformers) help identify tampering. If the fraud detection confidence is low, the system triggers human intervention.
How do you ensure that adding more countries and ID types will not degrade system performance?
A domain adaptation pipeline keeps a separate dataset for each region. A standard set of pre-processing steps normalizes images. A robust classification model or a hierarchical classification approach handles major ID families, then specialized submodels handle region-specific versions. Continuous evaluation monitors performance. Poor performance triggers region-specific fine-tuning or model updates.
How do you comply with local data privacy and regulations?
Data encryption at rest and in transit is used. Roles define who can read or export PII. A retention engine automatically deletes data after deadlines set by legal teams. Region-specific tokens may mask sensitive fields (like partial ID numbers). Logs and event streams only store hashed or tokenized data for analytics.
How do you approach model monitoring and drift detection over time?
All predictions and confidence scores are logged. Aggregate metrics (confidence distributions, acceptance rates) and feedback from human reviewers detect drift. A consistent increase in manual-review volume or false-accept rates signals distribution changes in ID documents. Scheduled re-training with fresh data corrects drift. Shadow models or A/B tests compare new solutions against the current production model to ensure stable performance.