
ML Case-study Interview Question: Fine-Tuning Transformers for Safe, Persona-Based Accounting Query Generation.


Browse all the ML Case-Studies here.
Case-Study question
A growing accounting software provider wants to incorporate a generative machine learning model to automatically draft client queries about ambiguous financial transactions. They want to fine-tune a large pre-trained text generation model to produce concise and professional or casual and friendly questions, depending on the accountant’s needs. They also want robust safety checks so no toxic or nonsensical content ever reaches the client. How would you design, train, evaluate, and deploy such a solution in a scalable production environment?
Requirements:
Use domain-specific data to fine-tune a generative model. Ensure the model can handle different personas (formal vs informal). Implement strong filters or guards to prevent hallucinations and toxic outputs. Preserve user privacy at all steps. Integrate seamlessly into the company’s existing workflow and data pipelines. Describe the model training pipeline from data preprocessing to production deployment.
Detailed Solution
Overview
Generative machine learning can transform user interactions by drafting transaction-related questions that save time. The core idea is to adapt a large Transformer model (for example, a T5-based model or similar) for domain-specific question generation. Accountants can confirm or edit these auto-generated questions. Short answer time accumulates into large time-savings.
Data Preparation
Collect historical transaction data, including descriptions and context. Pair each transaction with question examples in different tones. Store them in text format: transaction text plus a question label. Include persona tags (formal, casual, etc.) to let the model learn multiple styles. Use a consistent dataset schema so each record has transaction_description, persona, question. Generate enough examples with human-curated questions to guide the model.
Preprocessing
Tokenize text into subword tokens. Organize everything into key-value structures that match the model’s encoder-decoder format. Map persona tags into textual prompts (for instance, “formal: transaction=... question=...”). Convert data into batched tensors that feed into the model. Store transformation logic to avoid mismatches between training and inference.
Model Architecture
A Transformer-based encoder-decoder structure encodes transaction data and persona context into embeddings. The decoder produces word tokens step by step. The model uses a standard sequence-to-sequence loss to optimize likelihood of correct tokens.
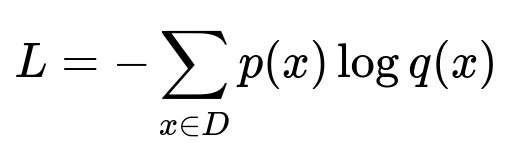
Where p(x) is the true distribution of tokens in the training set, and q(x) is the model’s predicted distribution.
This function measures how well the model’s generated text matches the reference questions in the training set. Minimizing this loss aligns the model’s outputs with the curated questions.
Model Training
Fine-tune on top of a large base model for better generalization with limited data. Freeze some layers if needed to reduce overfitting or to speed training. Track loss and validation performance across epochs. Stop once the model converges or shows no further improvement on reference metrics.
Safety Checks
Use an automated text screening system to filter harmful or nonsensical outputs. One check scans for toxic language. Another check monitors repeated or nonsense words. If anything is flagged, block or regenerate the text. Show final results only after these checks pass. A final human review ensures no flawed output reaches clients.
Evaluation
Gather a validation set of real transactions and reference questions. Generate model output. Compare with curated references. Measure text quality with Levenshtein distance, semantic similarity, and ROUGE. Higher distance with high semantic alignment indicates diverse yet relevant results. Require a baseline threshold for toxic words and nonsense. Validate persona style consistency.
Deployment
Export the entire model pipeline (tokenization, transformation, inference) into a single package or a standard serving service. Scale using a robust serving platform that can handle concurrent inference requests. Log results to monitor the percentage of flagged or re-generated outputs. Periodically retrain with new data to maintain accuracy.
In-Depth Example of Training Code
In Python, read raw transaction data from distributed storage. Convert records into input-output text pairs. Tokenize them into integer IDs. Package them into a training dataset. Instantiate a Transformer-based model. Compile with cross-entropy loss. Train until metrics plateau. Save the final model as a TensorFlow Serving artifact (or similar). Here is a small illustration of the approach:
all_data = load_transaction_records()
training_pairs = []
for item in all_data:
transaction_text = item["transaction_description"]
persona_style = item["persona"] # e.g., "formal" or "casual"
question_label = item["question"]
combined_input = persona_style + ": " + transaction_text
training_pairs.append((combined_input, question_label))
# Convert text to tokens
train_ids = tokenize(training_pairs)
# Build a tf.data.Dataset for efficient batching
train_dataset = tf.data.Dataset.from_tensor_slices((train_ids)).batch(32)
model = TransformerModel() # Some T5-like architecture
model.compile(optimizer="adam", loss="sparse_categorical_crossentropy")
model.fit(train_dataset, epochs=5, verbose=2)
# Export the model
tf.saved_model.save(model, export_dir="/my_generator_model")
Each transaction record gets a persona prefix. The model uses this to shape the tone of generated text.
Possible Follow-up Questions and Detailed Answers
1) How would you handle model hallucinations at scale?
Hallucinations happen when the decoder shifts off-track and generates incorrect or repeated words. Production systems should run multi-step filtering. First, automatically discard outputs containing repeated words or sequences. Then, check for suspicious patterns. Finally, have a fallback mode (like a simpler template-based question) if generation fails repeatedly. Monitor the system with logs. Gather flagged outputs, review them, and retrain or adjust hyperparameters to reduce future errors.
2) How would you ensure user privacy while fine-tuning on sensitive accounting data?
Keep all training data anonymized. Strip personal identifiers from text or replace them with placeholder tokens. Train the model in a secure environment where only authorized services can access the data. Encrypt at rest and in transit. Restrict logs. Ensure any external generative service calls do not send raw transaction details. Always maintain user consent for data usage.
3) Why is it advantageous to fine-tune on your own domain data instead of using an off-the-shelf generative model?
Using a general model often produces generic or irrelevant text. Fine-tuning on domain data helps the model learn the specific style and context of financial transactions. This yields more accurate outputs for your use case, like referencing expenses or reimbursements in a language that clients and accountants prefer. In-house fine-tuning also preserves unique business logic and brand tone without exposing private data outside the organization.
4) How do you compare different model versions to pick the best for production?
Keep a curated evaluation set with representative transactions and reference questions. Generate text with the old model and the candidate new model. Evaluate both on textual metrics (like ROUGE, semantic similarity, must-have token match rate). Compare results for each metric. Confirm that toxic/hallucination rates do not rise. If the new model consistently surpasses the old on these metrics and meets safety thresholds, promote it to production.
5) Could you explain how you might optimize inference speed while serving large volumes of requests?
Use model optimization techniques (quantization or distillation) to reduce computational load. Serve on GPUs or specialized accelerators for parallel processing of tokens. Batch requests so the model processes multiple queries in one pass. Maintain a pool of instances behind a load balancer. Cache frequent transactions if relevant, though generative tasks benefit less from caching than classification tasks. Profile system performance and scale horizontally to handle peak traffic.
6) How do you handle persona-based outputs without training multiple separate models?
Use persona tags embedded as a prefix or as a special token in the model’s input. For example, prefix the input with “formal:” or “casual:” before the transaction text. During training, ensure each persona style is well-represented. At inference, specify the persona token in the input. The single model learns to adjust tone. It is more cost-effective and simpler to maintain than many persona-specific models.
7) What metrics do you find most valuable for generative text models in this accounting context?
Precision metrics like semantic similarity and ROUGE measure alignment with reference texts. Distance-based metrics like Levenshtein evaluate text diversity. Toxicity detection rates measure safety. Hallucination checks track nonsense repetition or big off-topic shifts. Achieving high semantic alignment with moderate or high textual diversity is ideal. The combination of these metrics ensures relevant and stylistically varied output without undesirable or risky words.
8) How would you integrate user feedback loops to improve the model over time?
Log which auto-generated questions accountants edit or discard. Collect these edits in a feedback store. Regularly retrain the model with the updated examples so it learns from actual usage. This iterative approach refines style, correctness, and user preferences. Track a feedback acceptance ratio to see if improvements are holding in real-world conditions.
9) What if the accounting software experiences domain drift? For example, new categories appear or transaction styles change significantly.
Periodically sample new data, identify shifts in vocabulary, style, or new patterns. Retrain or refresh the model. If new transaction formats are drastically different, gather enough data to represent those cases. Retraining the model ensures it stays current with emerging transaction types or updated account codes. Automate this where possible and schedule regular retraining cycles.
10) How do you scale the entire pipeline for large enterprise clients?
Distribute data processing steps using robust orchestration platforms. Store transformations and metadata in a centralized database. Use modern serving platforms that auto-scale model instances based on inbound load. Containerize the inference service for portability. Archive older model versions for rollback if something fails in production. Keep continuous integration and continuous deployment pipelines so updates can roll out smoothly.