
ML Case-study Interview Question: Unifying E-commerce Notifications with Contextual Bandits for Optimal Engagement


Browse all the ML Case-Studies here.
Case-Study question
An e-commerce platform sends millions of emails and push messages to promote products and engage customers. They currently rely on separate models for each type of notification channel (daily batch emails vs behavior-triggered emails, daily push vs behavior-triggered push). They want a unified system to coordinate notifications across all channels, optimize user engagement, reduce unsubscribes, and learn continuously without manual retraining or frequent A/B tests. Design a machine learning solution to address these goals, explain how you would evaluate it, and discuss how you would deploy it in production at scale.
Detailed Solution
Overall Approach
Build a Reinforcement Learning system with a Contextual Bandit framework. Include exploration, so the model occasionally tries actions that differ from its current policy. Collect user interactions such as clicks and unsubscribes as reward signals. Update the policy automatically using these feedback loops.
Key Mathematical Formula
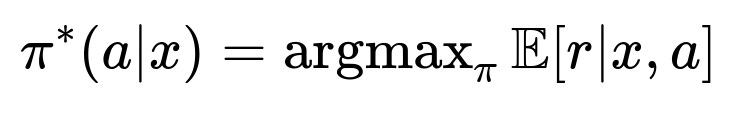
This formula represents the optimal policy pi*(a|x) that, for a given context x (user attributes or notification context), chooses action a (send or not send a notification) to maximize the expected reward r (user engagement).
Decision Granularity
Send decisions must happen at the individual notification level. Context includes user history, recent activity, and campaign type. Model states combine both batch features (like aggregated user engagement over past 30 days) and real-time features (like emails sent in the past hour).
Reward Signal
Track clicks as positive feedback and unsubscribes as negative. Model seeks to increase clicks and reduce unsubscribes. These actions correlate strongly with longer-term metrics (conversions and retention) while providing quick feedback for faster model updates.
Architecture and Data Flow
Pre-compute batch features with a daily pipeline. Store them for real-time scoring. Gather real-time features (recent notifications, last open time) from a streaming system. Serve features to the Reinforcement Learning agent at notification decision time. Log all decisions, contexts, and rewards to a central store for continuous training updates.
Offline Policy Evaluation
Use historical logs from the existing system. Compare expected performance of the new policy vs the old policy without running a live experiment. This reduces repeated A/B tests. Interpolate how the new policy would behave on past data. If the offline tests show improved performance, deploy the updated policy.
Exploration and Continuous Learning
Set a small fraction of decisions to be randomly flipped. Use these random actions to explore new policies. Incorporate user responses to refine the policy. This keeps the system fresh and robust to changing user preferences.
Implementation Details
Below is a Python snippet illustrating a simple contextual bandit structure. It uses a linear reward model as an example:
import numpy as np
class ContextualBandit:
def __init__(self, context_dim, num_actions, alpha=0.1):
self.context_dim = context_dim
self.num_actions = num_actions
self.alpha = alpha
self.weights = np.zeros((num_actions, context_dim))
def choose_action(self, context):
# context is a 1D np.array of size context_dim
estimates = [np.dot(self.weights[a], context) for a in range(self.num_actions)]
return int(np.argmax(estimates))
def update(self, context, action, reward):
prediction = np.dot(self.weights[action], context)
error = reward - prediction
self.weights[action] += self.alpha * error * context
Initialize the class with the number of actions (send vs no-send, or possibly multiple message types), dimension of the context vector, and a learning rate alpha. At inference, choose_action computes estimated reward for each action. The update step adjusts the chosen action’s weight vector toward the true reward signal.
Production Deployment
Schedule daily feature aggregation with a workflow manager (for example, Airflow). Supply these batch features to an online store for low-latency read. Ensure real-time logs capture open rates, click-through rates, and unsubscribes. Continuously update the model parameters based on fresh data. Keep latency in check by scaling with horizontally distributed inference servers.
Follow-up Question 1
How would you ensure that the model remains stable during rapid environmental changes, such as a seasonal spike in shopping activity?
A stable solution must maintain some fraction of exploration while quickly adapting to new feedback. Constant randomization helps capture new trends. One approach is to adjust exploration rates dynamically. If user responses deviate significantly from the current policy’s predictions, raise exploration. If system performance is consistent, lower it. Monitoring key performance indicators (send rate, unsubscribe rate, engagement) in near real-time helps detect abrupt shifts.
Follow-up Question 2
What are the main differences between a classical supervised learning approach and this Reinforcement Learning approach for notification governance?
Classical supervised learning predicts a probability of engagement or churn for each message. It does not automatically gather new training data through exploration. It also requires periodic retraining and manual A/B tests after each model update. Reinforcement Learning uses continuous exploration, so the model collects new signals without fully relying on offline retraining. The RL approach updates itself in near real-time using reward signals derived from user behavior.
Follow-up Question 3
How do you handle negative user feedback, like unsubscribes, in the reward function?
Unsubscribes serve as strong negative rewards. A typical numerical reward assignment uses positive value for clicks and negative value for unsubscribes. The RL agent learns to avoid actions leading to a higher probability of unsubscribes. Balancing click gains and unsubscribe penalties guides the model to reduce spam-like behavior and preserve user trust.
Follow-up Question 4
How would you extend this approach to unify email and push notifications into one framework?
Use the same core RL structure but expand the action space to include multiple channels or skip sending entirely. Include additional context features capturing user preferences for each channel and past response patterns. Let the policy decide channel type at each opportunity. This approach creates a single RL agent that weighs the best channel to send or decides to send none at all, maximizing user engagement and minimizing user fatigue.
Follow-up Question 5
What are the key considerations to avoid overwhelming users with too many messages in a single day?
The model must track recent send frequency in real time. One way is to inject a feature that counts notifications in the past hour or day. If the context shows a high frequency, the RL agent may learn that sending more leads to unsubscribes or lack of engagement. A rule-based cap can also be introduced if the business requires a strict daily send limit, overriding the RL decision when the threshold is reached.
Follow-up Question 6
How do you ensure you measure the real contribution of the notification system to sales or other long-term metrics when your reward function is based on short-term user engagement?
Long-term metrics are tracked outside the immediate reward loop. Correlate short-term signals like clicks and unsubscribes with eventual sales or retention. Regularly compare offline data of customers receiving messages vs a holdout group that receives minimal notifications. Ongoing observational analyses confirm that engagement-based rewards align with final metrics such as revenue per user or conversion rates.