
ML Case-study Interview Question: Deep Learning Recommendation Engine for Optimizing User Engagement at Scale.


Browse all the ML Case-Studies here.
Case-Study question
You are presented with a large-scale recommendation platform problem. A major online service has millions of users and a vast content catalog. They want to improve user engagement by offering personalized recommendations. The data includes user-item interaction logs, rich item metadata, and real-time behavioral signals. The goal is to design and deploy a production-grade recommendation engine that optimizes click-through and watch-time metrics. Provide a comprehensive strategy, including data pipeline, model design, training, validation, deployment, and performance monitoring. Explain your solution in detail, including architectures, optimization approaches, and how you would handle engineering at scale.
Detailed Solution
Data Collection and Preparation
Raw logs come from user actions such as clicks, partial views, completions, or skips. They are stored in a distributed file system. A batch pipeline (e.g. Spark jobs) aggregates these events and generates training examples. A real-time service captures immediate interactions, enabling faster updates in near-real-time.
Feature Engineering
All relevant features are engineered. Examples: User history includes items watched and dwell times. Item attributes include textual metadata, category labels, and user ratings. Context signals include time of day, device type, and session length. Categorical features are converted to embeddings or one-hot vectors. Continuous features are normalized.
Model Architecture
A deep learning model combines user embedding and item embedding with feed-forward layers. Training uses cross-entropy if the objective is to predict item clicks. Alternatively, a ranking loss such as pairwise loss can be used to prioritize positive samples over random negatives.
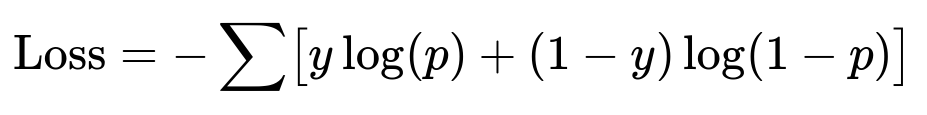
Here y is the binary label (1 if the user clicked, 0 if not). p is the predicted click probability. This formula is the cross-entropy loss for a single example. The summation is over all training examples.
Training Process
A large training set is sampled from historical interactions. GPUs or specialized hardware handle batches. We test different hyperparameters. Early stopping is triggered by validation performance. Techniques like dropout or batch normalization prevent overfitting.
Example Python code snippet:
import torch
import torch.nn as nn
import torch.optim as optim
class RecModel(nn.Module):
def __init__(self, user_dim, item_dim):
super().__init__()
self.user_embedding = nn.Embedding(num_embeddings=100000, embedding_dim=user_dim)
self.item_embedding = nn.Embedding(num_embeddings=50000, embedding_dim=item_dim)
self.fc = nn.Sequential(
nn.Linear(user_dim + item_dim, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, user_ids, item_ids):
user_vec = self.user_embedding(user_ids)
item_vec = self.item_embedding(item_ids)
x = torch.cat([user_vec, item_vec], dim=1)
return self.fc(x)
model = RecModel(user_dim=64, item_dim=64)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# Example training step
for batch in data_loader:
user_ids, item_ids, labels = batch
preds = model(user_ids, item_ids).squeeze()
loss = criterion(preds, labels.float())
optimizer.zero_grad()
loss.backward()
optimizer.step()
Offline Evaluation
A separate validation set and ranking metrics (e.g. Mean Average Precision) are used. We measure top-N recommendation accuracy, coverage, and diversity. A/B testing with holdout data can estimate if the model generalizes.
Serving and Online Inference
A dedicated inference service handles user requests. The system caches user embeddings to reduce latency. Item embeddings are loaded from a model store. The recommendation service fetches the top items and re-ranks them in real-time based on session context.
Monitoring and Iteration
A live A/B experiment measures improvements in click-through rates, session length, or watch-time. Important operational metrics like latency and throughput are tracked. The pipeline repeats data updates and retraining in a regular cadence.
Potential Follow-Up Question 1
How would you handle cold-start items and cold-start users in this recommendation system?
Answer and Explanation For cold-start items, gather item features such as textual description or category. Initialize item embeddings by converting textual metadata into embeddings via a pre-trained language model or by using average word vectors. For cold-start users, rely on contextual signals (device type, region, time) or use ephemeral session-based collaborative filtering. When the user interacts with enough items, a personalized vector is created. If there is minimal data, a fallback logic suggests trending or popular items.
Potential Follow-Up Question 2
How do you ensure that the model does not overly favor popular items and ignores niche content?
Answer and Explanation Introduce weighting schemes that reduce the influence of popular items in the training process. Sample negative examples proportionally and track coverage metrics. If a popular item appears too often, the sampling process includes less frequent items more aggressively. Post-ranking diversification steps re-rank top results to ensure wide coverage. This keeps less popular items visible to users with matching preferences.
Potential Follow-Up Question 3
How would you design an online A/B test and ensure statistical rigor?
Answer and Explanation Randomly split live traffic between the old recommendation model and the new model. Collect metrics such as clicks, watch-time, or conversions for both groups. Use confidence intervals around each metric difference. For significance testing, run a standard test such as a two-sided z-test or t-test, depending on sample size and assumptions about distribution. Predetermine a test duration or stopping criterion to avoid peeking bias. Confirm with a holdout period if needed.
Potential Follow-Up Question 4
How would you handle latency constraints in a large-scale recommendation environment?
Answer and Explanation Precompute user and item embeddings. Store embeddings in a high-speed key-value store for low-latency lookups. Implement an approximate nearest neighbor approach for candidate retrieval. Then apply a fine-tuned re-ranker on a smaller set of candidates. Cache frequently requested data. Monitor response times with distributed tracing. If the model is large, use quantization or model distillation to reduce inference time without sacrificing too much accuracy.
Potential Follow-Up Question 5
How do you mitigate bias or unintended side effects in the recommendation system?
Answer and Explanation Bias might occur if certain groups or items get systematically lower exposure. Collect fairness metrics. Introduce rebalancing in your training pipeline so the model sees balanced data. Evaluate results by demographic breakdown or content category. If severe skew is found, adjust the training set or the final re-ranking logic to correct it. Implement explainability modules to understand why the model prioritized certain items.
Potential Follow-Up Question 6
How would you scale the training pipeline when the dataset size and request volume grow?
Answer and Explanation Distribute training across multiple machines using a framework that supports data parallelism. If the dataset is huge, adopt mini-batch gradient updates on streaming data subsets. Automatically scale your cluster (for example with Kubernetes or specialized cluster managers) and monitor resource usage. Employ advanced partitioning or sharding of embeddings to keep them in memory. If the model grows too large, apply model parallelism or factorization to reduce complexity.
Potential Follow-Up Question 7
What if real-time data distribution changes, causing performance degradation?
Answer and Explanation Monitor real-time metrics for drift detection. Periodically compare distribution of new data against training distributions. If severe drift is observed, trigger faster retraining or more robust domain-adaptation steps. Use incremental learning methods that integrate new data on the fly. This maintains alignment with user behavior shifts.
Potential Follow-Up Question 8
How would you interpret the model’s results and share insights with stakeholders?
Answer and Explanation Offer partial explainability by showing top factors contributing to item ranking (e.g. similarity in user taste or metadata match). Use embeddings visualization to highlight clusters. Demonstrate how certain user features and content attributes influence predictions. Provide clear reports with metrics that show performance gains or losses. Emphasize the direct impact on user retention, growth, or revenue.
Potential Follow-Up Question 9
What techniques would you use to prevent overfitting or underfitting?
Answer and Explanation Use regularization such as L2 weight decay. Apply dropout in deeper layers. Regularly tune hyperparameters. Track both training and validation losses to identify potential overfitting. Evaluate on multiple validation sets from different time periods. If the model underfits, increase capacity or incorporate more features. If it overfits, reduce complexity, add dropout, or gather more data.
Potential Follow-Up Question 10
Explain the difference between offline evaluation metrics and online success metrics?
Answer and Explanation Offline evaluation uses historical data in a controlled environment. Typical metrics include Mean Reciprocal Rank, Normalized Discounted Cumulative Gain, or cross-entropy loss. These do not always predict real-world user engagement. Online success metrics are measured with live user interactions and can reflect subtle shifts in user behavior, satisfaction, or retention. A system must succeed both offline and online for robust success.