
ML Case-study Interview Question: Scaling Multi-Vertical Search using Federated Architecture and Learning-to-Rank.


Browse all the ML Case-Studies here.
Case-Study question
A large on-demand platform started with a single domain (food). They now want to expand search capabilities across groceries, convenience items, alcohol, and more. Their old system was tightly coupled to a single domain and struggled to index large numbers of new SKUs. They also lacked mechanisms to fuse results from multiple domains into a single relevant result set. They need to introduce new taxonomies to handle evolving data and must adopt machine learning to rank those results effectively for each user. Assume you are leading a Data Science team asked to:
Design a new end-to-end search infrastructure capable of handling constant real-time updates for millions of new SKUs.
Retrieve and blend results from distinct “verticals” (for example, groceries vs. restaurants) in a unified search pipeline.
Devise a plan for flexible data labeling and annotation to handle new product categories while ensuring data quality.
Implement a learning-to-rank pipeline that goes beyond naive string matching, incorporating business-specific relevance signals (popularity, user context, etc.) and user personalization.
Propose a technical solution architecture. Outline your indexing pipeline for real-time and batch updates. Explain how you will blend results across verticals. Show how you will integrate new taxonomies and annotated data. Describe your learning-to-rank approach and how you will evaluate relevance.
Detailed Solution
Indexing pipeline with real-time and batch updates
Set up a materialized view of all search documents. This view unifies data from real-time change-capture flows and daily batch extracts. Implement two types of indexing flows: one for high-priority or “hot” updates (for example, item pricing or store availability changes) and another for low-priority or “cold” updates (for example, entire category or large-scale product additions). Maintain incremental index builds for hot updates to avoid blocking the system. Store different index versions and automate index switching through a controller service to reduce human error.
Build a state machine with an orchestration layer that manages which index is currently “active” and triggers reindexing tasks based on triggers (for example, new data or partial index corruption). Keep a uniform set of logs and metrics to monitor index build times and retrieval latencies in production.
Federated retrieval for multiple verticals
Construct a federated search layer that issues queries in parallel to separate domain-specific indexes (food, groceries, alcohol, etc.). Each domain might apply its own unique retrieval logic or specialized features (for example, brand signals for retail). Collect the partial results and then pass them to a blending component that merges them into a single ranked list.
Allow each vertical to have domain-specific relevance rules. For example, a grocery vertical might weigh brand matches higher, whereas a restaurant vertical might emphasize dish-level textual matches. Impose separate latency budgets or SLAs per vertical so that a single slow domain does not degrade the entire query. Adopt timeouts and fallbacks to gracefully degrade if certain verticals fail.
New taxonomies and labeled data for query and document understanding
Define a flexible taxonomy that can accommodate expansions in new product categories. Include brand, store name, product variations, dietary attributes, and any other relevant metadata. Treat these categories as the “source of truth” for the internal representation of each item in the catalog. Build human annotation pipelines for large-scale data labeling. Provide clear guidelines and instructions to annotation vendors. Collect multiple labels per item to reduce bias. Perform random audits to ensure consistency across annotators.
Use a standard operating procedure in which a small subset is manually labeled to validate initial assumptions. Scale to thousands of items with semi-automated or partially manual workflows. Move toward machine learning classification once enough labeled data is available. Maintain separate QA checks on annotation outputs to detect vendor-specific biases. Store final labels in a structured data store (for example, CockroachDB or a relational warehouse) that the indexing layer can consume in real time.
Learning-to-rank approach
After retrieving candidates from each domain, apply a machine learning ranker that scores how likely each item is to meet user needs. Start with pointwise ranking to predict the probability of user conversion or satisfaction for each (query, item) pair. Train the model on user engagement data. Incorporate textual similarity (BM25 or other lexical features), store popularity, user signals (previous orders, cuisines preferred), and time features (day of week, hour). Use gradient boosted trees or a tree-based ensemble model for interpretability and fast inference.
Personalize results by capturing user context, such as historical orders or known dietary preferences. Use these features as inputs into the ranker. For example, a user who frequently orders vegetarian items might see vegetarian options boosted relative to generic results.
Search metrics and evaluation
Measure business metrics like click-through rate, conversion rate, or position of the first clicked item. Measure information retrieval metrics like mean reciprocal rank and normalized discounted cumulative gain. Collect both implicit feedback (clicks, purchases) and explicit feedback (human-labeled relevance). Maintain a separate offline pipeline that compares predicted rank against actual user behavior and produces daily or weekly dashboards.
Train on historical logs of user searches. Split queries into head, torso, tail based on frequency. For head queries, use large-scale user engagement signals. For tail queries, rely more on synonyms, partial matches, and domain-level expansions from the new taxonomy. Use the same system to measure gains or regressions in search performance.
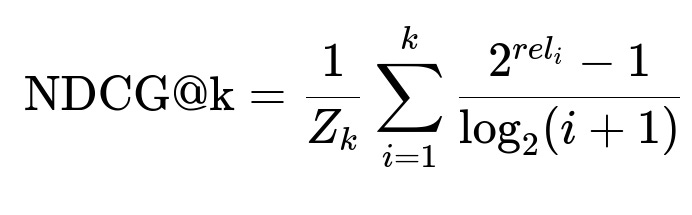
Where rel_i is the ground-truth relevance of the item at position i and Z_k is a normalization factor ensuring the perfect ranking has a value of 1. NDCG measures the ranking quality in terms of how highly relevant items appear nearer the top.
Example Python snippet
# This pseudocode trains a pointwise LTR model using XGBoost:
import xgboost as xgb
train_data = xgb.DMatrix(data=train_features, label=train_labels)
params = {
"objective": "reg:squarederror",
"max_depth": 8,
"eta": 0.1
}
model = xgb.train(params, train_data, num_boost_round=100)
# Example inference for a single query's candidates
candidates = fetch_candidates(query)
scores = []
for candidate in candidates:
feat_vector = extract_features(query, candidate)
pred = model.predict(xgb.DMatrix(feat_vector))
scores.append((candidate, pred))
sorted_candidates = sorted(scores, key=lambda x: x[1], reverse=True)
Train the model with query features, candidate features, and user signals. Evaluate in offline tests with NDCG. Then use an A/B test in production to compare engagement vs. the baseline ranker.
Potential Follow-up Questions
1) How can you handle a sudden influx of new verticals or categories without major code changes?
Maintain a microservice-based approach that lets each vertical own its retrieval logic. Expose an interface for searching new verticals. The federated layer orchestrates calls to each domain. Maintain consistent indexing pipelines that feed a single centralized store or multiple domain-specific indexes. Ensure the orchestration can dynamically discover new vertical endpoints and that the blending layer can incorporate them in a flexible pipeline without rewriting core search code.
2) How do you ensure data quality in the annotation process, especially for niche categories?
Create standard operating procedures with unambiguous definitions for each label. Provide repeated training and examples to the annotation workforce. Perform double or triple labeling on a certain fraction of items to compute inter-annotator agreement. Monitor vendor performance over time. Spot-check random samples and measure error rates. Give clear and frequent feedback to vendors when quality drops. Adjust guidelines if you detect systematically misunderstood instructions.
3) How do you select and tune the ranking objective?
Choose an objective aligned with your primary business goal. For immediate results, train a regression model predicting the probability of conversion. For purely relevance-focused tasks, optimize a ranking metric like NDCG. If you want a classification approach, use cross-entropy to predict a binary label (converted vs. not converted). Tune hyperparameters by splitting the dataset into training, validation, and testing sets. Perform a grid or Bayesian search to discover the best trade-offs between model complexity and generalization. Evaluate using offline metrics. Validate your chosen objective with online A/B tests for final performance checks.
4) How do you approach latency constraints for real-time inference in your microservices?
Implement caching for frequent or popular queries, either by storing full results or partial feature vectors. Precompute advanced NLP features for frequent queries. Limit the complexity of models for online inference or use an approximation method. Keep your ranking server close to your storage layer to minimize network round trips. Scale the system horizontally by adding containers with the model loaded in memory. Profile the model’s runtime. Investigate more efficient modeling frameworks such as TensorRT or ONNX Runtime if using deep neural networks.
5) Why consider building a custom Lucene-based engine instead of relying on a managed ElasticSearch solution?
Needing tight control over retrieval logic or advanced ranker integration can require embedding custom code in the storage layer. Avoiding multiple network hops reduces latency if your approach does two-stage retrieval. ElasticSearch can be costly at scale if you have massive volumes of data. Lucene’s low-level APIs provide more flexibility for advanced searching and indexing optimizations, including specialized ranking experiments or textual feature engineering. A custom solution can also integrate with your continuous integration and deployment processes more seamlessly, while letting you tune resource usage more precisely.