
ML Case-study Interview Question: Self-Supervised Geocoding for Real-Time Correction of Inaccurate Delivery GPS Locations.


Browse all the ML Case-Studies here.
Case-Study question
A Q-commerce platform requires real-time correction of customer-provided GPS locations for fast deliveries. Many customer GPS locations are inaccurate, causing significant delays. Design a system to identify these inaccurate locations and accurately predict corrected coordinates. Explain how you would handle data collection, model training (without manual labels), and post-processing. Also address the core challenges in ensuring high accuracy across diverse areas (apartment complexes, independent houses, office parks) under strict operational constraints.
Detailed Solution
The system needs three major components: a classifier for inaccuracy detection, a geocoder for location correction, and a post-processor to certify the final output. The absence of manual labels makes it necessary to rely on self-supervised signals from delivery personnel (DP) or customer events. The small error budget in Q-commerce adds complexity. The following sections describe each component, referencing three candidate geocoder architectures.
Location Inaccuracy Classifier
A supervised or self-supervised model identifies whether a customer GPS coordinate needs correction. The classifier uses features like:
Textual features from the address.
Historic delivery coordinates if available.
Distance-based or map-based signals.
Only flagged addresses proceed to the geocoder.
Geocoder Architectures
1. Seq2Seq Geocoder (based on a transformer or language model encoder and an LSTM decoder)
Captures contextual patterns in textual addresses. Merges the address text and a partial geohash from the existing captured location. For training, it relies on negative samples that pair an address with a known coordinate from previous orders. No manual annotations are used.
Internally, it splits an L8 geohash into two segments:
The first three characters come from the inaccurate location.
The last five characters are predicted by the Seq2Seq model.
Teacher forcing is used during training. Greedy decoding is applied at inference. The model tries to handle addresses that may be off by hundreds of meters.
2. Unsupervised Address Matching (UAM)
Retrieves a best-matched address from a database of addresses with trusted coordinates. Works in two stages:
Coarse retrieval: Focuses on the H8 cell that contains the customer-captured location.
Fine retrieval: Applies fuzzy string matching (via metrics like Jaro-Winkler and token ratios) on address pairs to identify the best candidate H11 cell inside the H8 cell. The centroid of that H11 cell is the predicted coordinate.
Uses purely text-based matching across a set of negative samples. Restricts corrections to a roughly 500-600 m radius since each H8 cell is not very large.
3. Self-Supervised Address Matching (SAM)
Encodes addresses via a pretrained RoBERTa-based embedding model trained with triplet loss. This model positions similar addresses close in embedding space, while pushing dissimilar ones apart. Geocoding then becomes a nearest-neighbor search among addresses within the same H8 cell. The final coordinate is that of the best address match.
Post-Processing for Q-commerce
Raw model outputs are often off by a few hundred meters. Q-commerce demands a smaller error margin, often tens of meters. Post-processing harnesses historic delivery locations for each address:
If all historic delivery coordinates lie close to the model prediction, it is declared usable.
Otherwise, the prediction is discarded.
This ensures only highly confident corrections survive.
Key Metrics
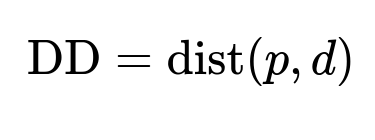
p is the predicted location, d is the actual delivery location. The distance function is typically the Haversine distance. Lower DD is better.
RDD=dist(c,d)−dist(p,d)
c is the captured (inaccurate) location, p is the predicted location, d is the delivery location. This measures how much closer the prediction is relative to the captured location. Higher RDD is better.
Relative delivery precision (RDP) tracks how often predictions improve over captured locations. A higher RDP indicates more successful corrections.
Examples of DBSCAN Post-Processing
A DBSCAN algorithm can cluster multiple historic delivery coordinates. If a cluster has enough points (say min_points=4, epsilon=20 m), it derives a reliable centroid. This method does not use address text but often achieves highly accurate clusters in dense areas. The geocoder’s coordinate is declared valid if it matches the DBSCAN cluster within a small threshold.
Implementation Example: DBSCAN
import numpy as np
from sklearn.cluster import DBSCAN
def get_dbscan_location(delivery_points, eps=20, min_samples=4):
coords = np.array(delivery_points)
db = DBSCAN(eps=eps/6371000.0, min_samples=min_samples,
metric='haversine').fit(np.radians(coords))
cluster_labels = db.labels_
if len(set(cluster_labels)) == 1 and -1 in cluster_labels:
return None # no cluster found
# find cluster with max number of points
best_cluster = np.argmax(np.bincount(cluster_labels[cluster_labels!=-1]))
best_points = coords[cluster_labels == best_cluster]
# median or mean can be used
centroid = np.median(best_points, axis=0)
return centroid.tolist()
In a production setup, convert eps from meters to radians for haversine-based distance. This snippet clusters location points and returns the cluster centroid if found.
Overall Flow
The classifier flags addresses needing correction. The geocoder predicts a raw coordinate. The post-processor checks consistency of that raw prediction with known delivery coordinates. The final predictions typically outperform raw geocoder outputs alone and help correct addresses not handled by a simpler clustering approach.
Possible Follow-up Questions
How would you validate the model without reliable ground truth?
Compare each new model’s corrections against a DBSCAN centroid. Track deviation metrics (DD) and compute if the model’s predictions are on par or better. Also measure coverage. Even if DBSCAN is more accurate, its coverage might be low for addresses with limited delivery data. A union or ensemble approach can combine multiple geocoder outputs to maximize coverage without compromising accuracy.
Why not rely solely on DBSCAN?
DBSCAN needs enough delivery points to form dense clusters. Many new addresses have fewer deliveries. The geocoder can correct from the first or second delivery itself. DBSCAN might fail when limited data prevents cluster formation. The geocoder’s text-driven matching handles new addresses better.
How do you handle language variations and mixed text addresses?
A multilingual or large language model such as RoBERTa pre-trained on diverse text can handle multilingual addresses. Tokenizing non-English text effectively is key. Maintaining separate region-specific models can also help. If each region has unique textual patterns, separate models can outperform a single global model.
How would you address the risk of overcorrecting?
The classifier is crucial. Only addresses flagged as inaccurate should be corrected. If the user’s GPS location is already accurate, no correction is done. A post-processor also discards any low-confidence correction. Combining location-based checks (distance from known delivery points) with the textual pattern ensures minimal overcorrection.
What if the delivery personnel location is itself wrong?
Occasional noisy DP inputs can happen. Spatial clustering across multiple deliveries filters out outliers. If some deliveries are far from the real address, they do not form a dense cluster. The median or centroid of the largest cluster remains a robust estimate. Marking single outlier events as noise mitigates erroneous signals.
Why combine multiple geocoder approaches?
Each approach has trade-offs. A Seq2Seq model might correct large misplacements. An address similarity model might handle smaller distance corrections more reliably. A union of predictions can boost coverage and accuracy. Orders that fail with one approach might pass post-processing with another. An ensemble also taps different data signals and offsets weaknesses.
How would you scale this pan-country?
Partition the country by regions or states. Train separate or specialized models. This accommodates regional address formats, language differences, and place names. Ensure training sets across regions are large enough for robust embeddings. The post-processing logic remains identical, because the DBSCAN threshold is chosen based on Q-commerce delivery constraints rather than language or region.
How to handle edge cases like partial or minimal text addresses?
Short or incomplete addresses limit text-based matching. The geocoder might rely more on coarse H8 location. Post-processing with any partial historic deliveries helps. If the address never had valid deliveries, a fallback mechanism or prompting for more user input might be necessary. Combining multiple data signals (like known building polygons if available) also helps.
How does restricting the search area to an H8 cell help?
Restricting the search space forces the model to look for better matches in a smaller radius. This speeds up retrieval and lowers the chance of spurious matches. Most real errors are within a few hundred meters, so confining the search area is practical. If the address is drastically outside that cell, the classifier might detect an extreme anomaly and skip such constraints.
How do you ensure real-time performance?
Caching embeddings for frequently queried addresses prevents repeated encoding. Indexing addresses by H8 or H11 cells speeds up lookups. Reducing model size or using quantized embeddings can make retrieval faster. Precomputing embeddings for the entire address database off-line is crucial for prompt nearest-neighbor searches at runtime.
How can you fine-tune the system after deployment?
Capture user or DP feedback on corrected addresses. If a predicted location fails in actual delivery, flag the sample as inaccurate and retrain or adjust the model. Maintain a running log of error patterns to refine classification thresholds or geocoder architecture. Monitor performance metrics such as DD, RDD, and coverage at scale, then iterate with incremental improvements.