
ML Case-study Interview Question: Automating Product Metadata Extraction with Cloud-Scale OCR and Fuzzy Matching


Browse all the ML Case-Studies here.
Case-Study question
A large multinational marketing organization manages an enormous repository of digital assets. They want to automate the extraction of key product information from these files using Computer Vision and Optical Character Recognition techniques. They have a petabyte-scale media library containing diverse image, video, and design files lacking consistent metadata. They also need to update their product taxonomy in the metadata for efficient retrieval. Assume they use a major cloud provider with available AI services, containerized DevOps practices, and advanced pipeline orchestration. Propose an end-to-end solution that performs OCR at scale, integrates fuzzy matching with a product taxonomy, handles various file types (including large movie files), and ensures reliability of extracted metadata. How would you design the system, confirm its scalability, and measure reliability?
Please walk through the system architecture, your proposed pipeline, and the technical underpinnings in detail. Include proposed data structures, sampling methods for quality checks, and potential optimizations for cost savings.
Detailed solution
OCR Pipeline and Preprocessing
Construct a pipeline that retrieves asset files from a shared location and converts them into formats suitable for OCR. Use container-based microservices for modular tasks. Let one container handle the conversion of each file into a standardized image format (for example jpeg). Store those converted images in a staging area.
Scale horizontally by distributing many assets across Kubernetes pods. Attach an event-driven framework so each new file triggers a job for preprocessing before being routed to the OCR stage. For images and design files (like psd or svg), convert them into jpegs. For video, sample frames with an interframe analysis step to avoid redundant processing of similar frames.
Handling Large Movie Files
Decompose video files into frames. Compute differences between consecutive frames by measuring pixel-level changes. Keep only frames that exceed a threshold of difference. Assemble these sampled frames into storyboards, which are single images containing multiple frames. Pass these images through the OCR service. This approach reduces cost because each storyboard is submitted once instead of many identical or near-identical frames.
Fuzzy Matching and Product Taxonomy
Apply fuzzy logic to OCR text outputs for matching product names. Process extracted text with standard NLP techniques. Tokenize words, remove punctuation or extraneous symbols. Compute text similarity using edit distance.

Set thresholds after examining actual brand names. For partial matches, see if the differences are within an acceptable distance. For instance, “Emergen” is close to “Emergen-C” by a small number of character edits, so treat them as equivalent if they meet the threshold.
Incorporating EXIF Data
Extract embedded metadata for certain file types. Many jpegs or mov files contain creation date, device type, or geotags. Parse these fields if they exist. Skip or downplay them if they produce inaccurate or incomplete data. Sort older assets into lower-cost storage if the workflow demands it.
Sample Proportion Analysis
Evaluate performance by sampling. Collect a random subset of assets (images, videos, designs) and verify the pipeline’s coverage and accuracy. Coverage measures how many assets contain extracted metadata. Accuracy measures if the extracted metadata is correct for known assets.
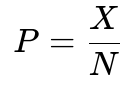
X is the count of successful matches in the sample. N is the total sample size. Use repeated sampling with replacement (bootstrapping) to get an estimate of pipeline performance on the overall population.
DevOps and Scalability
Dockerize each stage. Use Kubernetes to orchestrate multiple container replicas. Implement an event-driven approach with a service bus or event grid. Monitor logs with an observability tool (like Application Insights) to spot bottlenecks.
A possible stack:
Docker images hold the OCR logic and image/video processing code.
Kubernetes scales up containers to handle large numbers of parallel tasks.
Cloud AI APIs perform OCR.
Terraform templates replicate or modify infrastructure on demand.
Code Example for Fuzzy Matching
import re
from difflib import SequenceMatcher
def normalize_text(text):
text = re.sub(r'[^a-zA-Z0-9\- ]', '', text.lower())
return text.strip()
def similarity_score(a, b):
return SequenceMatcher(None, a, b).ratio()
extracted_text = "Emergen"
taxonomy = ["Emergen-C", "VitaGummy", "SomeOtherBrand"]
normalized_extracted = normalize_text(extracted_text)
best_match = None
best_score = 0
for brand in taxonomy:
brand_normalized = normalize_text(brand)
score = similarity_score(normalized_extracted, brand_normalized)
if score > best_score:
best_score = score
best_match = brand if score > 0.75 else None
print("Match:", best_match)
print("Score:", best_score)
This approach normalizes strings and computes a similarity score. Adjust the threshold after sampling real data to minimize false matches.
Reliability and Future Extensions
Observe logs to identify systematically failing file types. If certain assets consistently produce no text, confirm if they actually contain text or if the pipeline’s OCR is failing. Use more advanced techniques (like Video Indexer) for video content involving speech or scene detection. Always keep track of compute costs, especially if the pipeline runs on millions of assets.
Possible Follow-Up Questions and In-Depth Answers
How can you ensure minimal processing on frames that contain nearly identical content?
Use interframe similarity. Calculate a difference metric between consecutive frames. If the difference is below a threshold, skip processing. This threshold is determined experimentally by measuring how many frames are truly distinct. If large segments are identical, only one frame gets processed. Storyboards further compress multiple frames into a single image, reducing API calls.
What if the fuzzy matching still produces many false positives for brand names?
Increase the similarity threshold or enrich the pipeline with domain-specific lexicons, synonyms, or brand-specific text patterns. In some cases, assign partial matches a penalty. If “Emergen” and “Emergen-C” differ slightly, treat them as an acceptable match. If “Emergene” is far off, discard it as noise. Always refine thresholds with real data and gather feedback from subject-matter experts.
How would you handle language-specific OCR challenges?
Use localized OCR services or libraries that support language detection. Run a pre-check on text snippet patterns or known glyph sets. If the pipeline encounters an unexpected language, route it to the correct language model. For multi-language assets, segment them by region if possible.
How do you handle large-scale throughput while controlling costs?
Implement parallelism with Kubernetes for horizontal scalability. Use serverless event triggers for dynamic resource allocation, so containers spin down when idle. Build aggregated calls for images whenever possible. For instance, process multiple frames in a single storyboard call. Watch real-time logs for concurrency usage to ensure you do not exceed resource quotas.
Why is sampling important when you have so many assets?
Manual checking of all assets is infeasible at petabyte scale. Sampling lets you measure coverage and accuracy in a subset. Extrapolate these results to the entire dataset with confidence intervals. If coverage or accuracy is too low, refine the pipeline. If results are satisfactory, proceed with full deployment.
What if you must integrate text data from the folder path or file name into the final metadata?
Parse folder paths with the same NLP and fuzzy-matching logic used on OCR outputs. Merge these two text sources. If the folder name includes the campaign or brand, you can confirm it against the OCR text. This redundancy helps fill gaps in missing data. For example, if the folder path states “Campaign_EmergenC_Q3,” you can cross-check the OCR result.
How do you manage versioning and incremental improvements without disrupting ongoing operations?
Adopt infrastructure as code with Terraform for reproducible environments. Tag each pipeline version with explicit release notes. Deploy new versions of the pipeline in a canary deployment model. Run the new version side-by-side with the old one on a small subset of assets. If the new pipeline’s performance meets or exceeds the baseline, roll it out more widely.
How do you apply robust monitoring and logging?
Send logs to a central service. Collect container logs, application logs, and OCR results. Add correlation IDs that track each asset across the pipeline. Use dashboards to identify assets that repeatedly fail or require fallback measures. This helps debug sporadic issues with large video files or legacy formats. Use alerts when error rates exceed normal thresholds.
How can you handle advanced metadata extraction from specialized file types (like layered PSD or vector EPS)?
Use specialized image processing libraries to open layered files. If there are embedded text layers, extract them directly. Vector files often have text elements definable in XML or proprietary structures. Extend the pipeline to parse these structures. Convert them into standard image snapshots if text extraction fails or if a fallback approach is simpler.
What if you want to evolve beyond text extraction to detect brand logos or product shapes in images?
Incorporate advanced object detection or brand logo detection models. Host these models in the same Kubernetes environment. When needed, run them on each asset or storyboard to capture brand visuals. Complement text-based recognition with image-based brand detection, especially when brand names appear in stylized forms.
If certain brand text is stylized or partially obscured, how do you improve detection accuracy?
Retrain or fine-tune OCR models on brand images to handle stylized fonts. Introduce additional data augmentation with known brand packaging images. Combine standard OCR with specialized brand detection networks. For partially obscured text, use advanced approaches like morphological operations or image inpainting to highlight partial text regions.
Could you automate the entire content flow from ingestion to final tagging?
Automate ingestion with a listener that responds to new uploads. Once a file arrives, route it to the pipeline. After successful OCR and fuzzy matching, update the metadata in the asset management system. Include a final validation step for flagged exceptions. This ensures continuous integration and minimal human intervention.