
ML Case-study Interview Question: Hierarchical ML Predicts Real-Time Store Item Availability at Scale


Browse all the ML Case-Studies here.
Case-Study question
A large scale marketplace platform faces unpredictably changing inventory in physical stores, affecting millions of items. Users see real-time availability indicators when building their carts, and personal shoppers rely on updated signals. Many items have sparse usage data, while frequently purchased items generate abundant data. Propose a machine learning solution that predicts real-time availability for each item in each store, incorporating a reliable, interpretable, and cost-effective approach for both head and tail items. Explain your modeling strategy, the infrastructure pipeline to handle hundreds of millions of items, and how you would adapt this system for different user contexts like immediate fulfillment versus scheduled future delivery.
Detailed solution
Model Structure and Reasoning
A hierarchical structure works well. One component captures a long-term availability baseline, a second component captures deviations from that baseline, and a third component handles the most recent signals. This design provides interpretability and handles sparse data.
General Availability (G)
General availability captures the typical pattern. It is computed by aggregating item signals over a sufficiently large scope. If an item has enough local, recent shopper events, using that local window is more representative. When data is sparse, expanding geographically or temporally ensures enough samples. The output is a reliable base probability for finding an item.
Trending (T)
Trending adjusts the baseline. A gradient-boosted tree model can generate a correction factor that accounts for shifts from the typical availability, like sudden shortages. This captures recent store-level disruptions, seasonality, or supply chain issues. The trending model takes the general score as a core input and outputs a corrective component.
Real-Time (R)
Real-time handles the most recent signals. Shopper-reported out-of-stock events, retailer inventory feeds, or fresh sensor data have stronger short-term impact. This component detects if the item was just found or not found. It also learns the expected time to restock. When only a few hours have passed since the last out-of-stock event, the likelihood is still low. As time passes, restocking likelihood increases.
Combining the Three Components
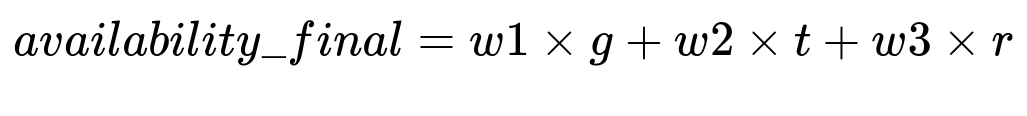
Where g is the general availability score, t is the trending deviation, and r is the real-time correction factor. The weights w1, w2, and w3 determine how much each component contributes. They are learned or tuned based on historical performance.
g is computed from aggregated found rates over various spatiotemporal scopes, chosen to meet a data sufficiency threshold. t is the output from a learned model (like XGBoost) that predicts short-term deviations based on recent signals, events, or store-level patterns. r is derived from the latest shopper scan or retailer feed and accounts for time since the last update, letting the model incorporate short-term restocking behavior.
Infrastructure and Pipeline
A tiered serving strategy lowers costs. Head items are scored more frequently because they generate many real-time events. Torso items get updated periodically. Tail items get occasional updates and rely more on the general component. A streaming pipeline ingests events in near real time and updates scores for items recently observed. A daily batch pipeline handles broader coverage for low-traffic items. The system can serve multiple versions of availability scores depending on the user context, such as scheduled next-day delivery or immediate pickup.
Engineering and Implementation Details
The pipeline can run on a modern MLOps platform. A feature store centralizes snapshot features for trending and real-time signals. Real-time processing uses a streaming platform that updates item-level features immediately after a shopper scan. A daily batch job runs for all items and writes new general scores. Cost optimizations include storing subsets of items with fresh signals in memory for frequent real-time scoring and storing long-tail items with a more static schedule.
A sample Python outline for the trending model:
import xgboost as xgb
import pandas as pd
data = pd.read_csv("training_data.csv")
features = data.drop(columns=["availability_score"])
labels = data["availability_score"]
params = {
"objective": "reg:squarederror",
"max_depth": 6,
"eta": 0.1,
"subsample": 0.8,
"colsample_bytree": 0.8
}
xg_reg = xgb.XGBRegressor(**params)
xg_reg.fit(features, labels)
# Use xg_reg.predict() to get the trending correction factor
Context Adaptation
A real-time API allows different use cases to specify which model version or time horizon to use. Immediate fulfillment uses the real-time pipeline. Scheduled orders use a model that projects forward with known restocking patterns. This ensures the predicted availability aligns with the relevant time window.
Follow-up question 1
How would you manage interpretability in a multi-component system?
Answer Explanation
Each component’s contribution is visible in the final score. Auditing the general score alone shows the baseline. The trending factor indicates whether recent disruptions lowered or raised availability. The real-time component reflects the most recent signal. Investigating each component reveals why the final prediction is high or low. This allows corrective actions such as contacting a store manager if the model indicates low availability despite frequent user demand.
Follow-up question 2
How do you handle items with insufficient data in any component?
Answer Explanation
When data is too sparse for a hyper-local window, the scope expands regionally or nationally over a longer period to collect enough observations. A hierarchical fallback strategy ensures coverage for tail items. The trending model still applies, though with limited weighting when few recent signals exist. The real-time component is only active if new signals arrive within a short window. Otherwise, the model reverts to a more conservative baseline.
Follow-up question 3
How do you scale infrastructure for hundreds of millions of items while managing costs?
Answer Explanation
Partition items by frequency. Head items get real-time updates and frequent trending runs. Torso items get moderately frequent updates. Tail items rely mostly on daily or weekly batch jobs. Real-time scoring only processes items with active signals, cutting down on unneeded compute. A robust streaming setup ingests fresh events at high throughput, and a batch pipeline still covers the entire catalog in scheduled intervals.
Follow-up question 4
What if a new external event dramatically disrupts stock levels, such as a sudden shortage or weather event?
Answer Explanation
The trending model detects sharp changes when the short-term signal deviates significantly from the baseline. Real-time scans confirm the shortage by increasing the weight on out-of-stock observations. Retraining intervals can be shortened to incorporate the sudden shift. If an extreme event persists, the general score gradually lowers as the model accumulates out-of-stock observations. The system can also incorporate external signals, such as a known weather alert or supply chain feed, to accelerate recognition of a disruptive event.