
ML Case-study Interview Question: Building a RAG System for Fast, Accurate Support Answers from Proprietary Knowledge


Browse all the ML Case-Studies here.
Case-Study question
Your company provides specialized knowledge services for professional clients worldwide. Many of these clients deal with complex regulations and frequently seek fast, accurate answers from your customer support team. The volume of new issues and inquiries has grown rapidly, creating higher resolution times and risking client dissatisfaction.
The current support workflow relies on a large repository of technical knowledge base articles, CRM tickets, and anecdotal experiences of individual support agents. The team struggles to find relevant solutions quickly. Your task: design and implement an AI-based system that empowers agents to locate and generate accurate answers to client questions, referencing proprietary knowledge in real-time. Propose a scalable solution and explain how you would handle new or updated knowledge. Demonstrate how your system ensures minimal hallucination errors and accurate citations. Illustrate how you would measure success and drive continuous improvement.
Provide a complete solution architecture, including retrieval components, text-embedding approaches, and language models. Describe how to keep the system reliable and maintainable. Suggest how you would handle growing data volumes. Outline a proof-of-concept plan, then show how you would optimize speed, accuracy, and domain relevance. Finally, recommend best practices for preventing misleading outputs while giving helpful contextual answers.
Proposed In-Depth Solution
The goal is to build a Retrieval-Augmented Generation (RAG) solution to tackle the growing complexity of support queries. This strategy fuses dense retrieval mechanisms with sequence-to-sequence (seq-to-seq) Large Language Models (LLMs). The retrieval component fetches domain-relevant articles, while the LLM synthesizes clear responses, citing the retrieved material.
Data Processing and Indexing
Start by collecting text from the knowledge base, CRM logs, and other repositories. Break the text into smaller chunks (for example, 200-500 tokens each). Generate dense embeddings for each chunk using a suitable transformer-based encoder such as a pre-trained sentence transformer. Store these embeddings in a vector database (for instance, Milvus or a similar system).
Dense Retrieval System
Queries from support agents are also embedded into the same vector space, generating a query vector. Perform a similarity search against the stored embeddings to identify the top relevant chunks. Cosine similarity is common for measuring closeness between query vectors and database vectors.
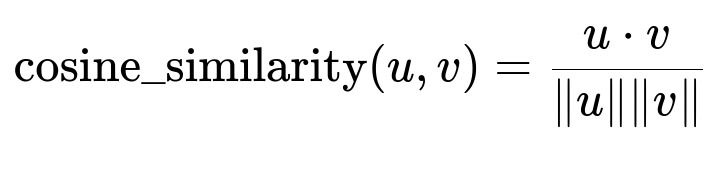
Above formula computes the dot product of two vectors u and v, then normalizes by their magnitudes. Higher values indicate greater similarity.
Seq-to-Seq Language Model
Feed the retrieved textual chunks into a seq-to-seq LLM, such as GPT-4 or an open-source alternative. Concatenate the chunks and user query into the LLM prompt. Instruct the LLM to produce an answer grounded in these chunks. This direct grounding step reduces hallucinations and ensures the LLM references real source text.
Handling Updated Knowledge
Update your vector database frequently to incorporate new or modified knowledge base content. As soon as a new article or customer resolution is available, generate embeddings and insert them into the database. This keeps retrieval accurate without fully retraining the LLM.
Ensuring Reliability
Employ a system-level approach to monitoring. Record each query, the top retrieved chunks, and the final answer. Periodically audit for errors or incorrect sources. Consider fallback strategies (e.g., returning multiple potential solutions) when confidence scores are low. Maintain versioned embeddings so you can revert if new embeddings reduce system performance.
Measuring Success
Use metrics that evaluate both response quality and operational efficiency. Common metrics:
Average handling time: measure how long it takes to resolve a user request.
User satisfaction: track feedback from customer agents on relevancy.
Containment rate: how often solutions are found without escalating to higher tiers.
Accuracy: measure correctness through manual audits or match rates with known solutions.
Proof of Concept Steps
Select representative subsets of support articles.
Convert them into embeddings and store in a small vector database.
Query with common support questions.
Evaluate the correctness of the retrieved passages.
Integrate with a seq-to-seq model (like GPT-4) via API calls.
Examine the final output for accuracy and helpfulness.
Conduct user acceptance testing with actual support agents.
Scalability and Optimization
Scale by distributing the vector index and using approximate nearest neighbor search. Compress embeddings or shard the index across multiple nodes for faster lookups. Fine-tune retrieval thresholds to reduce false positives. Use prompt engineering to keep LLM calls short and focused.
Preventing Misleading Outputs
Maintain guardrails in your prompts. Provide system instructions that forbid speculation and require citations from retrieved material. If no relevant data is found, instruct the LLM to convey uncertainty. Periodically refresh prompts to reflect new best practices or disclaimers as needed.
Example Python Pseudocode for Retrieval
import milvus
import openai
from transformers import AutoTokenizer, AutoModel
# Connect to vector store
client = milvus.Milvus("localhost", "19530")
# Step 1: Encode query
query_text = "How do I resolve the 1040 e-file error: IND-041Error?"
encoded_query = model.encode(query_text)
# Step 2: Search for top matches
search_params = {"nprobe":10}
status, results = client.search(collection_name="support_articles",
query_vectors=[encoded_query],
top_k=5,
params=search_params)
# Step 3: Compile context
context_chunks = [hit for hit in results[0]]
prompt_context = ""
for chunk in context_chunks:
prompt_context += chunk.text + "\n"
# Step 4: Call LLM with context
openai.api_key = "YOUR_API_KEY"
prompt = f"Context:\n{prompt_context}\n\nQuestion:\n{query_text}\nAnswer with references."
completion = openai.Completion.create(engine="gpt-4",
prompt=prompt,
max_tokens=300)
answer = completion.choices[0].text.strip()
print(answer)
This demonstrates how vector-based retrieval merges with an LLM API for a real-time domain-specific Q&A system.
How would you handle these follow-up questions?
1) How do you ensure minimal hallucinations when the LLM sees limited context?
Use a multi-step prompt structure. Provide the LLM with highly relevant chunks, possibly re-rank or filter them if they exceed token limits. Instruct the LLM to strictly cite the retrieved context. If it cannot find an answer there, it should say so. Monitor the ratio of final answers referencing the retrieved chunks. Post-process to flag any text that fails to match known references.
2) How do you keep this system efficient if your knowledge base grows to millions of articles?
Shard the vector embeddings across multiple servers or use specialized indexing techniques (for example, approximate nearest neighbor searches like HNSW). Partition the data by topics or product lines. Use indexing data structures that minimize memory usage (such as IVF-Flat or IVFPQ). Parallelize your embedding pipeline to handle large volumes. Perform periodic merges or re-indexing to keep the system agile.
3) How would you update the system with newly found solutions?
Whenever a new resolution or article is created, embed it using the same model. Insert it into the vector database. Tag it with timestamps or product categories for quick retrieval. Periodically prune outdated or duplicate entries. Maintain a pipeline that flags new content for embedding at ingestion time or on a daily schedule.
4) How do you handle user prompts that might be ambiguous?
Include clarifying steps in your prompt chain. When the LLM detects an ambiguous question, direct it to ask follow-up queries to refine the user’s intent. Alternatively, supply UI elements letting the agent pick from a set of clarifying questions. Only then finalize retrieval and produce an answer. This iterative approach reduces misinterpretation.
5) What if the vectors incorrectly rank some articles higher than more relevant ones?
Consider updating the embedding model to a more specialized domain model or try fine-tuning on your own data. Implement a re-ranking step with a cross-encoder that checks top results for direct question relevance. Re-evaluate your chunking strategy so more semantically coherent sections form each vector. Track precision and recall metrics to see if you need further adjustments.
6) Are there data security concerns when using a third-party LLM API?
Scrub sensitive data before sending requests. Anonymize or mask personal details. Use encryption for all network communications. Keep a secure gateway that monitors traffic to the LLM API. Some organizations might opt for on-premise or private cloud hosting of open-source LLMs. Conduct risk assessments regularly to comply with data protection regulations.
7) How do you handle training or inference costs at scale?
Optimize by using an effective dense retrieval system that lowers the total number of tokens passed to the LLM. Restrict LLM usage to complex queries. Cache frequent queries to reuse existing answers. Evaluate open-source LLMs with GPU or specialized hardware. Use dynamic batching or streaming to reduce overhead. Monitor usage to detect patterns of cost inefficiency.
8) Why choose dense retrieval over older keyword-based search?
Dense retrieval captures semantic meaning. Keyword searches rely on exact matches and can miss conceptually related passages. By embedding queries and documents in the same vector space, we identify context more effectively. The modern approach scales better for specialized or complex queries. It also pairs seamlessly with LLMs to produce accurate, natural-sounding explanations.
9) How would you prove the system truly helps reduce resolution time?
Gather baseline metrics from your existing support flow. Measure average handling time before RAG deployment. Then run a pilot with the new system. Capture metrics on resolution time, agent feedback, and user satisfaction. Compare these metrics to the baseline to quantify the gains. Validate that improvements are statistically significant over enough support cases.
10) Could you adapt this system for direct end-user self-service?
Yes. You can replace the agent-facing interface with a user-friendly chatbot interface that uses the same retrieval + LLM pipeline. Include disclaimers if the user’s question is beyond the system’s scope. For domain-sensitive fields like legal or financial advice, maintain prompts that remind the user this is not official counsel. Implement user session tracking to handle multi-turn user interactions.