
ML Case-study Interview Question: Deep Learning Ranker for Multi-Factor Food Dish Search Relevance


Browse all the ML Case-Studies here.
Case-Study question
A major food-delivery platform wants to improve its dish search ranking system to show the most relevant dishes on top. The system needs to handle noisy user queries containing vague descriptions, spelling errors, multi-language usage, and implicit preferences for certain types of cuisine or restaurants. The platform also aims to incorporate popularity, distance-time considerations, and restaurant-specific nuances. How would you design a ranking model that understands a user query's intent and serves the most relevant dishes at the top of the list? Outline your approach, elaborate on the training objective, list important features, and propose how you would evaluate and iterate on the model.
Detailed Solution
A suitable approach is to build a Deep Learning model that uses multiple input components to produce a ranking score for each dish given a user query. The system retrieves candidate dishes from a large index and then applies a ranking model to sort them by relevance. The model learns from historical user click-through data, where frequently clicked dishes get a higher likelihood of relevance.
Key Inputs and Features
The model benefits from the following inputs for each dish-query pair:
Semantic Input: Includes query text, dish name, and dish family. Dishes with ambiguous or stylized names require extra information about the dish category (for example, "Green Grocer" might be a burger, so it belongs to the "Burger" family).
Restaurant Input: Captures attributes like restaurant embeddings, cuisine embeddings, ratings, cost, and preparation time. This information encodes differences between, say, a burger from a global chain vs. a local brand.
Popularity Input: Ingests data on how often a dish or restaurant is ordered daily or monthly. It captures general demand and user preference patterns for certain items or chains.
Distance-Time Input: Reflects how far the restaurant is from the user and the expected delivery time. Shorter distances or quicker delivery times can be more appealing and thus more relevant for a user query.
Model Architecture
The ranking is a weighted sum of four sub-scores: (1) Semantic, (2) Restaurant, (3) Popularity, and (4) Distance-Time. Each sub-score is produced by a neural module specialized in that feature set. The final model is trained end-to-end.
Semantic Model
Transforms the query, dish name, and dish family strings into embeddings, then computes similarities. If the dish name is descriptive, more weight goes to name-query similarity; otherwise, the model compensates using the dish family. A learned parameter (w) controls how much each component contributes to the final semantic score.
Restaurant, Popularity, and Distance-Time Models
Each sub-model processes its respective features. Restaurant embeddings and features can be combined with the query embedding or treated independently, depending on whether the restaurant features are query-sensitive. Popularity numbers (daily, monthly) and distance-time features (last-mile distance, delivery time) also feed into neural layers. Several functional forms can be tested: some take the dot product between query and feature vectors; others concatenate them in a deep network; or some ignore the query if that component is query-agnostic.
Weighted Sum for the Final Score
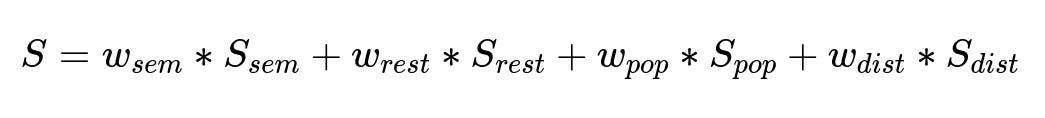
S is the final dish score. w_{sem}, w_{rest}, w_{pop}, and w_{dist} are learned parameters, and S_{sem}, S_{rest}, S_{pop}, S_{dist} are the sub-scores.
Training Objective
The model is trained on historical logs where each query has three dish types: clicked dish, shown-but-not-clicked dish, and random irrelevant dish. The model must rank clicked dishes above shown-but-not-clicked dishes, and shown-but-not-clicked dishes above irrelevant dishes. This is achieved with Margin Ranking Loss.
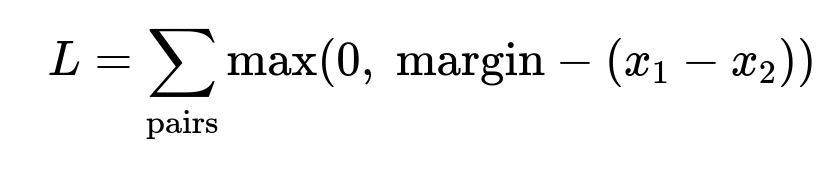
Here x1 and x2 are scores for two dishes. The margin enforces a required gap between relevant and irrelevant predictions. For three dish types (clicked, shown, random), the loss ensures: clicked_dish_score > shown_dish_score > random_dish_score by at least a chosen margin.
Model Evaluation
Offline metrics include Mean Reciprocal Rank (MRR), which captures ranking quality. An online A/B test can monitor real user clicks, conversions, and order rates. A consistent increase in these metrics indicates the model is returning more relevant dishes.
Practical Implementation
A typical implementation in Python would use frameworks like TensorFlow or PyTorch. The code might create embedding tables for query tokens, dish names, and cuisines. Numeric features like distance, popularity, and rating would be normalized. The network would output sub-scores, which get combined in a final linear layer that sums them with learned weights. Margin Ranking Loss from the chosen deep-learning library would be applied to train. After deployment, real-time inference would process the input query, retrieve relevant dishes, compute sub-scores, sum the final scores, and return sorted dishes.
Follow-Up Question 1
How would you handle cold-start scenarios for dishes or restaurants that have limited historical data?
For new items or restaurants with little historical data, popularity features and click logs are sparse. Embedding-based features help, since a new dish of a known category still maps to an existing embedding space. A new "Paneer Tikka" item in a restaurant can partially inherit popularity signals if the restaurant itself is popular. You could also rely on dish-family information. Another strategy is to initialize new embeddings to average values of similar items or to rely on content-based signals like descriptions. Over time, the model refines these parameters from real clicks.
Follow-Up Question 2
What if user queries contain heavy spelling variations that your dish names do not capture?
Text normalization or spelling correction is crucial. A character-level or subword tokenizer can partially address variants. Phonetic mapping for local language words to English helps if queries like "murgh" or "murg" appear for "chicken." A user might type "chikn," so a trigram-based embedding approach can handle these partial matches. Noise-resistant token embeddings also help. If the domain heavily involves Indian languages, you can create a dictionary of popular transliterations.
Follow-Up Question 3
Why not just use a single large transformer-based model on the entire dish name, query, and numeric features?
A single large transformer can sometimes ignore numeric signals or poorly fuse them. The modular approach isolates each subset of features and ensures interpretability. It also simplifies experiments if you want to add or drop certain modules. But using a large transformer might still work if carefully fine-tuned with a stable representation for numeric data. The trade-off is computational cost vs. flexible modular control.
Follow-Up Question 4
How would you optimize delivery time predictions in your feature set, so it remains accurate under varying conditions?
You can train a specialized ETA (Estimated Time of Arrival) model that uses real-time restaurant load, traffic patterns, and rider availability. The distance-time sub-score would consume that predicted ETA instead of a static distance measure. Updating the ETA model frequently ensures accuracy when conditions change. The ranking model then gets an up-to-date feature for how long an order might take. This helps reorder items by prioritizing those that are faster to deliver if the user is time-conscious.
Follow-Up Question 5
How do you ensure this ranking system remains robust under large-scale data growth?
Proper sharding for embeddings, distributed training, and consistent retraining on fresh data are essential. Periodic offline evaluations and automated pipelines help monitor performance. Feature-store infrastructure can manage numeric and categorical features. Data versioning and robust logging ensure consistent input transformations. If the dish index grows, retrieval must remain efficient, possibly with partitioning by cuisine, region, or popularity.
Follow-Up Question 6
How do you handle user personalization if two users have different tastes but issue the same query?
You can augment the ranking model with user-level preference vectors. User embeddings capture prior orders, cuisine affinity, budget range, or dietary constraints. The final sub-scores incorporate user embedding interactions. If one user frequently orders spicy food, that user embedding can shift the relevant results for the query "chicken" to spicier items from certain restaurants. Maintaining user embeddings requires a user profile store that updates as users place orders or show new behaviors.
Follow-Up Question 7
What if the model starts drifting due to changing user preferences or new cuisines?
Continuous learning helps. A portion of logs from the latest time window can be sampled and used for incremental retraining. Seasonal changes or newly popular items are quickly learned. You can also maintain a fallback or ensemble approach that blends older stable parameters with newly updated parameters to prevent severe performance drops during rapid distribution shifts.
Follow-Up Question 8
How do you validate that your margin-based approach is giving a better user experience than classification-based approaches?
You can compare offline ranking metrics like MRR or Normalized Discounted Cumulative Gain (NDCG) with classification-based models. Look at the distribution of items ranked in top positions. Evaluate user engagement metrics like clicks-per-query or checkout rates in an A/B test. The margin-based approach enforces clear ordering constraints, which often produces stronger ranking signals than just predicting click probabilities. Empirical evidence from user tests or real traffic can confirm that margin-based training yields better outcomes.
Follow-Up Question 9
If queries sometimes refer to combos, how does your system deal with multi-dish items?
Combos can be tagged under a special dish family or subcategory in your taxonomy. The semantic module can learn that "combo" or "thali" references a set of items. If the user frequently engages with combos, the user embedding or popularity signals will boost combos. The final ranking integrates these signals, even if the dish name alone is ambiguous. If combos are missed in retrieval, you might add synonyms or expansions (e.g., "family meal," "value meal") to the index for robust coverage.
Follow-Up Question 10
What if you want to incorporate real-time user feedback signals such as dwell time on a dish description?
Dwell time can be appended as an immediate feedback loop for re-ranking. The user session can be updated if the user hovers or reads about certain dishes. A short-term re-ranker, possibly with a lightweight model, can reorder subsequent items mid-session. This approach complements the main ranking system and captures immediate user interest. The main model may use aggregated dwell-time patterns historically, but real-time feedback is best handled by an in-session re-ranker that updates results instantly.