
ML Case-study Interview Question: Graph Databases and BFS Features for Real-Time Reservation Fraud Detection.


Case-Study question
You are tasked with building a secure, real-time fraud detection and prevention system for a large-scale online reservation platform. This platform faces threats like payment fraud, fake accounts and reviews, and other malicious activities. The existing data reveals strong interconnections among users, payment instruments, and suspicious signals. You must design a solution that leverages this graph-like data to identify and stop fraudulent activities in real time.
Propose how you would:
Represent and store the data so you can spot suspicious connections.
Engineer graph-based features (like node counts or proximity to prior fraud).
Operate under strict real-time constraints while handling huge volumes of new requests.
Integrate this graph-based approach with machine learning or heuristic rules for final risk decisions.
Explain your design choices in detail.
Detailed Solution
Data Representation and Storage
The system relies on the insight that fraudulent activity often emerges from groups of related identifiers. Linking these identifiers in a graph highlights patterns that might remain hidden in a flat table. Each node can represent an entity: user account, credit card, email address, or any other relevant identifier. Edges capture relationships between nodes when they appear together in transaction data. Storing these relationships in a graph database allows real-time queries on connected components and distances.
Graph Construction Process
The process starts each time a new request (for instance, a reservation) arrives. The identifiers associated with this request become nodes in the graph if they do not exist already. An edge is inserted between them. If some identifiers have prior fraudulent involvement, the graph has nodes or tags reflecting their status.
One of the simplest but most critical graph-based features is the shortest path from the new request’s node to any known fraud node. This distance can be captured by breadth-first search or other graph algorithms. This measure is sometimes called hops_to_fraud. The system needs this metric quickly, so it must traverse or fetch from the graph database in real time.
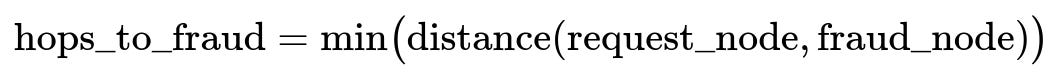
Here, request_node is the central node for the new transaction, and fraud_node indicates a node previously flagged as fraudulent. The distance function can be computed by breadth-first search. If the shortest path is small, it might signal a potential link to known fraud.
Real-Time Query and Feature Extraction
When a new transaction arrives, the system:
Inserts or updates the relevant nodes and edges in the graph database.
Executes a breadth-first search (or similar) to gather connected neighbors and find paths to flagged fraudulent nodes.
Builds features like number of connected accounts, number of connected cards, or shortest path length to fraud.
Returns these features to a risk-scoring system or a fraud model.
These queries must be sub-second. The combination of indexing techniques and efficient traversals is essential to keep latency low. A consistent data model ensures that edges and nodes stay updated with each new request, preserving the historical link structure without losing track of newly surfaced fraud signals.
Modeling and Risk Prediction
The risk model (for instance, a gradient boosting classifier or a neural network) consumes the graph-based features along with other signals like user behavior or device data. The model can learn patterns of graph connectivity that correlate with fraudulent behavior. In parallel, fraud domain experts can define heuristic rules (for example, if the graph shows a single account connected to hundreds of cards, flag for manual review).
Example Python Snippet
A simple breadth-first search in Python might look like this:
from collections import deque
def bfs_shortest_path(graph, start_node, target_node):
visited = set([start_node])
queue = deque([(start_node, 0)])
while queue:
current, depth = queue.popleft()
if current == target_node:
return depth
for neighbor in graph[current]:
if neighbor not in visited:
visited.add(neighbor)
queue.append((neighbor, depth + 1))
return None # No path found
This approach returns the number of edges in the shortest path from start_node to target_node. If the system or the graph database is massive, we rely on the database’s built-in query engine to do the same logic more efficiently.
Architecture
A real-time service called something like Graph Service handles graph queries and data updates. A separate Fraud Detection Service calls the Graph Service with the relevant transaction data. The Graph Service updates the database and runs breadth-first search or a specialized traversal to generate features. The Fraud Detection Service uses these features to produce a final fraud risk decision.
Handling Scale and Latency
Maintaining low latency requires:
Proper indexing of frequently queried properties.
Efficient data partitioning to allow parallel traversal.
Carefully limiting how deep the traversal goes in real time.
Caching repetitive lookups where possible.
If the graph is extremely large, careful design ensures BFS queries do not explode in size. One option is capping the maximum depth of the search or restricting the total number of traversed nodes for a single request.
Conclusion
Graph-based fraud detection systems capture hidden relationships in a way that flat data structures cannot. Real-time feature extraction, combined with a scalable graph storage solution, surfaces valuable insights about potential associations to known fraud. With domain expertise and machine learning models, this approach creates a robust and adaptive fraud prevention strategy.
What follows are possible follow-up questions an interviewer might ask, with detailed answers:
How would you handle exponential growth in the graph?
The graph can grow quickly when many entities interconnect. Limiting search depth and indexing important link types helps. A tiered storage approach can keep older data in cheaper storage if real-time searches do not need it. Regularly pruning or archiving nodes that have not appeared in any transaction for a long time can reduce graph size. Sharding the graph across multiple database servers can distribute storage and computation.
What if some features become too large and sparse?
Some features, like count of connected cards for a user, might get huge. The risk model can treat extremely large counts as outliers and clip them. Another approach is using logarithmic or other transformations so that extreme values do not dominate the training process. Using subgraphs or sub-sampling can also control dimensionality while retaining crucial signals.
Could graph embedding techniques help?
Techniques like node2vec or GraphSAGE can create vector representations of nodes based on their connectivity patterns. These embeddings can be used as features for a classifier. They might capture more nuanced graph structure than manually engineered features. The trade-off is added complexity and a potential need for frequent retraining if the graph changes quickly.
How do you maintain low latency during BFS on a large database?
One strategy is to store adjacency lists in a way that allows quick lookups of neighbor nodes. Another is caching partial traversals for frequently seen connections. Using a specialized graph database with built-in BFS or shortest-path algorithms can be faster than custom code. Parallelizing the search by partitioning the graph into smaller chunks is also possible.
How do you integrate domain experts and manual rules with machine learning?
Domain experts often identify patterns that are not easily captured by a model. Heuristic rules can run alongside the model, contributing immediate flags. If a rule triggers, the system may override the model’s output or mark the transaction for manual review. Over time, newly confirmed fraud incidents can be fed back into the training dataset, and the model can learn from them.
How do you adapt to changing fraud tactics?
Fraudsters change tactics often. An iterative data pipeline, with regular retraining of the model on recent data, is critical. The graph structure updates in real time, so newly exposed fraudulent entities become instantly available for BFS computations. Automated pipelines can retrain the model when shifts in fraud patterns appear in the data distribution.
If BFS results in too many connected nodes, how do you keep performance high?
Configuring a max depth or limiting branching can prevent runaway traversals. If the partial graph still gets too large, you can stop after some threshold and mark that node as “highly connected.” The model can interpret that as a risk factor. Proper indexing strategies let the database skip irrelevant subgraphs and focus on the local neighborhood of interest.
How do you ensure data consistency when updating the graph?
Atomic writes are key. Some graph databases or the underlying storage (like Cassandra) use lightweight transactions to ensure the newly added edge or node is immediately recognized by subsequent reads. In highly concurrent systems, eventually consistent writes might be enough if the fraud model can tolerate minor inconsistencies. A versioning approach can also help rollback partial updates if needed.
Any privacy and security concerns?
This solution stores personal identifiers. Compliance with regulations (like GDPR) is mandatory. Pseudonymizing sensitive fields can reduce data exposure risks. Clear access controls ensure only authorized systems can modify or read the graph. Periodic audits confirm that the stored data remains relevant and lawful.
The real-time graph-based system enables deep insight into suspicious link structures. This helps the platform respond quickly to evolving fraud patterns. The BFS-based features and proximity measures can be combined with modeling or rule-based logic to block malicious activities at scale.