
ML Case-study Interview Question: Real-Time Outdated Browser Analysis & Update Prompt Prediction with Logistic Regression


Browse all the ML Case-Studies here.
Case-Study question
A large user-facing platform noticed that many visitors still use outdated browsers. They want a data-driven solution to identify these browsers in real time, classify user behavior patterns, predict the impact of prompting users to update their browsers on session length, and measure overall user engagement improvements. How would you approach designing and implementing such a solution?
Detailed Solution
Data Collection and Preprocessing
Collect user-agent data, browser versions, session times, pages visited, and device details. Store raw logs in a distributed system. Parse the user-agent strings and map them to browser family and version. Use a cleaning pipeline to remove inconsistent entries. Parse timestamps to derive time-based features.
Feature Engineering
Focus on session-based and user-based features. Track average session length, number of pages visited, bounce rate, and user update behavior patterns. Encode browser version as numeric or categorical. Standardize numerical features. Encode categorical variables with embeddings if necessary.
Model Design
Use a supervised classification model to predict whether a user will accept an update prompt. Train on past data with known outcomes for browser update acceptance. Split data chronologically to simulate the real environment.
Use the logistic regression function as the core model to handle large-scale data. Alternatively, try gradient-boosted trees for greater accuracy, especially if interactions between session features matter.
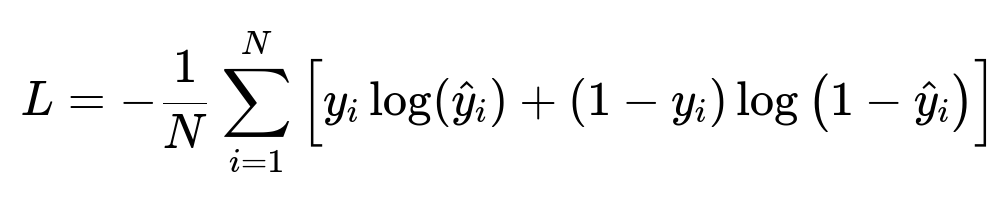
N is the number of examples. y_i is the true label (update accepted or not). hat{y}_i is the predicted probability of acceptance. This cost function is minimized during model training to optimize parameters.
Implementation Plan
Use a pipeline that runs daily or hourly. Pull fresh logs from the data store. Preprocess using Python with libraries such as Pandas for data cleaning. Train the model offline on historical data. Validate the model with a portion of unseen logs. Deploy the model as an inference service that tags users in real time. Serve the update prompt to those predicted to accept. Track acceptance rates and usage metrics. Continuously retrain as user behavior changes.
Monitoring and Evaluation
Track metrics such as accuracy, precision, and recall for update acceptance prediction. Monitor changes in session length and user retention post-update. Compare to a control group who did not receive the update prompt. Recalibrate thresholds if acceptance rates differ significantly from expectations.
Follow-Up Question 1
How would you evaluate whether prompting users to update their browsers truly increases session length?
Use an online controlled experiment with two groups: one receiving the prompt and one not receiving it. Randomly assign incoming users to each group. Track session length changes between groups. Run statistical tests (for example, a t-test on average session length). Confirm that no external factors differ between groups. Demonstrate causality by verifying a significant difference only in the prompted group.
Follow-Up Question 2
What challenges arise from using user-agent strings to classify browsers, and how do you handle them?
User-agent strings can be inconsistent and sometimes spoofed. Some older devices may not reveal correct version data. Use a robust parsing library to extract version information. Maintain a regularly updated mapping of known browser signatures. Cross-check the user-agent against other signals such as device hardware or site interaction patterns. Implement fallback rules for incomplete data and remove or impute extreme outliers.
Follow-Up Question 3
How do you handle data leakage when training a model to predict update acceptance?
Data leakage can occur if variables include future data or if the training set has signals from labels that are not yet known at prediction time. Split data chronologically to simulate real-time conditions. Restrict features to only what would be available before the user sees the prompt. Monitor any feature that might implicitly capture the acceptance decision. Remove or adjust those features. Validate with a time-based hold-out set to confirm generalization.
Follow-Up Question 4
Why choose logistic regression over more complex models, and how would you scale it?
Logistic regression is simple, interpretable, and fast to train and predict. It handles large-scale data well with distributed training implementations and parallelization. The coefficients are easy to understand. It is straightforward to deploy and update regularly. In practice, for very large datasets, use a parameter server architecture or libraries like Spark MLlib. For streaming inference, load the model in a lightweight service that responds quickly.
Follow-Up Question 5
If you see minimal improvement in session length, what adjustments would you make?
Revisit feature engineering by adding new session-based metrics or user segments. Check if the prompt timing is appropriate. Modify the user interface to highlight benefits of updating. Explore a different model or add interactions between features. Monitor whether repeated exposure to prompts causes prompt fatigue. Try personalized prompts for specific user groups.