
ML Case-study Interview Question: LLM & Vision Driven Product Attribute Extraction and Catalog Matching from PDFs


Browse all the ML Case-Studies here.
Case-Study question
A large E-commerce platform receives PDF documents describing upcoming apparel trends. Each PDF has product descriptions, images, and potential attributes like color, sleeve style, material, etc. They want a scalable system to extract these attributes from both text and images, unify duplicate values, then match extracted attributes to an existing catalog for better assortment planning. Propose a detailed plan, with technical methods, for building and deploying such an automated Product Attribute Extraction engine. Include how you would tackle data cleanup, text extraction, image extraction, text processing, computer vision approaches, attribute merging, and catalog matching. Describe the framework’s design, performance metrics, and how you would ensure robustness and accuracy.
Detailed Solution
Text Extraction
Process PDF pages as images. Convert PDFs into images (e.g. via pdf2image). Use grayscale conversion and morphological transformations to highlight text regions. Apply OCR to extract text. Fix common spelling errors with a spell corrector. Segregate noise like footers or headers.
Image Extraction
Extract image objects directly from the PDF. Convert these image objects to a standard format like jpg. Organize them page by page. Remove duplicates and invalid images. Convert the final images to base64 encoding before sending them to a large language model for attribute extraction.
Attribute Extraction from Text
Send extracted text to a large language model prompt specifying the target attributes: color, sleeve style, product type, material, features, categories, age, neck, and so on. Parse the model’s response into a structured dictionary. Handle partial synonyms using a post-processing layer that normalizes repeated terms.
Attribute Extraction from Images
Send the base64-encoded images, along with a prompt to a vision-based large language model. Generate the same set of attributes. Parse them into a dictionary. Consolidate them with text-based extractions so each page has a merged list of attributes. Remove duplicates like “v-neck” and “VNeck” by normalizing text.
Catalog Matching
Represent each extracted attribute using embeddings from a bidirectional transformer. Represent catalog attributes similarly. Compare these embeddings via cosine similarity to find the best match.
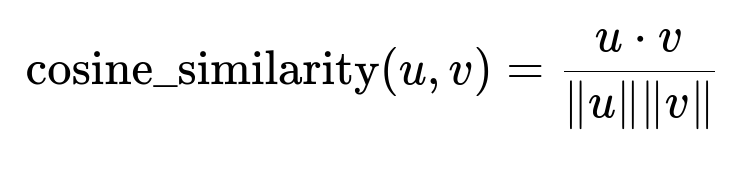
u dot v is the dot product of u and v. |u| and |v| are their magnitudes. High similarity indicates a close match. Use threshold tuning to finalize attribute mappings.
Evaluation
Compare predicted and ground-truth attributes with Accuracy, Recall, and F1. Evaluate speed and resource consumption for large PDF sets. Consider:

Precision is predicted positives over total predicted positives. Recall is predicted positives over actual positives.
Follow-up question 1
How do you handle PDFs containing multiple columns, tables, and custom fonts?
Answer: Split pages into images. Apply morphological transformations to isolate text lines in each region. OCR each segment independently. Reconstruct text flow by analyzing bounding boxes. Sort extracted text blocks logically. Use robust OCR engines that adapt to unusual fonts and table structures. If text is still scrambled, apply advanced table-parsing or partial manual labeling for tricky sections.
Follow-up question 2
How do you ensure the large language model extracts attributes consistently and handles synonyms?
Answer: Use a standardized prompt that explicitly lists the target attributes. Apply a post-processing script to unify synonyms (“Vneck” to “V-Neck”). Maintain a dictionary of known synonyms. Repeatedly sample check the output, refine the prompt, and do partial fine-tuning or few-shot examples if needed.
Follow-up question 3
What if the image-based extraction fails when multiple items appear in a single image?
Answer: Segment the image into regions of interest if multiple products are present. Use object detection or instance segmentation to split each product. Pass each segmented region to the vision model. Concatenate all results. Filter out irrelevant items if extraneous objects appear.
Follow-up question 4
How do you handle misaligned text and image attributes?
Answer: Keep a page-level aggregator that merges results from text and images belonging to the same page. If text mentions one color but the image shows multiple, store both possibilities until final consolidation. Use confidence scores or references in the PDF layout to correlate text phrases to specific images.
Follow-up question 5
How do you scale this approach for thousands of PDFs daily?
Answer: Deploy the image extraction and OCR pipeline in a distributed system. Use parallel processing of pages. Deploy the large language model via a server or API that batches requests. Cache repeated font or layout patterns. Distribute the embedding computation for catalog matching. Use a queue-based system to handle bursts of new PDFs and throttle LLM calls when needed.
Follow-up question 6
How do you validate that your attribute mappings to the catalog are correct?
Answer: Check the top-n matches from cosine similarity. Verify them manually for a subset. Track mismatch rates. Adjust thresholds if you see false positives. Store matched records with confidence scores. Periodically review them. Apply active learning, where uncertain matches get additional checks from domain experts.
Follow-up question 7
How do you handle partial or missing labels in training or evaluation data?
Answer: Label as many samples as possible. Use data augmentation to improve coverage. Use a flexible evaluation strategy that can handle missing attributes. Train or fine-tune the system with partial labels for robust performance. Mark attributes as “unknown” if insufficient context is found in text or images.
Follow-up question 8
How do you deal with confidential information or personally identifiable data in PDFs?
Answer: Apply a pre-processing sanitizer that detects and redacts sensitive data. Restrict LLM inputs to only the content necessary for attribute extraction. Keep logs anonymized. Enforce strict role-based access to stored PDFs and intermediate outputs. Configure data retention policies to delete or encrypt them after extraction.
Follow-up question 9
How do you ensure minimal system downtime?
Answer: Containerize the pipeline components. Use blue-green deployments for updates. Keep a fallback instance of the OCR and attribute-extraction service. Monitor memory and GPU usage with alerts. Employ auto-scaling for times of high PDF volume.
Follow-up question 10
How would you integrate user feedback into future improvements?
Answer: Collect user confirmations or corrections on extracted attributes. Store them in a labeled dataset. Retrain or fine-tune the LLM and similarity model periodically. Monitor changes in style or terminology to update the synonym dictionary. Introduce incremental learning for new product types and attributes.