
ML Case-study Interview Question: Geofencing-Powered Machine Learning for Accurate Delivery Service Time Prediction


Browse all the ML Case-Studies here.
Case-Study question
You are leading a Senior Data Scientist interview for a large e-commerce grocery delivery business. The company used a fixed seven-minute service time for each delivery stop and noticed inefficiencies. They had limited actual data on real service duration. They decided to collect accurate service time data using a geofencing solution integrated into drivers’ handheld devices, while ensuring driver privacy. They wanted to use this new data to build a predictive model to improve delivery scheduling, reduce driver stress, and optimize costs. How would you approach this problem from start to finish?
Provide a detailed plan for collecting relevant data, validating data quality, addressing privacy concerns, building a robust predictive model, and integrating it into the existing logistics platform. Consider potential edge cases, explain how you would iterate on the solution over time, and discuss how you would measure success.
Detailed solution
Data collection and privacy protection relied on a geofencing strategy. Engineers placed a virtual boundary around each delivery location to record timestamps whenever drivers entered or exited that location. Drivers initially had concerns about constant tracking, so the team clarified that they would only store durations in the analytical database for modeling. This approach secured driver trust.
Early tests used an off-the-shelf geofencing application on a standard handheld device. This let the company confirm the technology’s accuracy by comparing geofence timestamps with manual stopwatch measurements. Consistency across many test deliveries demonstrated strong correlation between geofence-derived durations and actual service times.
Organizing the final geofencing implementation involved careful calibration of boundary sizes to avoid premature triggers when drivers passed by closely located addresses. Engineers also handled situations where multiple customers might share a large apartment building, which could complicate geofence timing. Drivers helped identify those edge cases so the final implementation would capture reliable timestamps.
After data collection, the analytics team explored patterns. Floor level, elevator presence, number of boxes, total weight, and other factors appeared relevant. A manual adjustment method used these features to update the service time estimate. That manual method already showed improvements, but they wanted a robust machine learning approach to predict times more precisely.
Modeling approach
Data scientists selected relevant features such as order volume, building characteristics, time of day, and driver attributes. The final target variable was the duration measured by geofencing. They divided data into training, validation, and test sets. They considered gradient-boosted trees for capturing non-linear interactions between features. They also tried a linear regression benchmark for quick insights.
They tuned hyperparameters to avoid overfitting. They applied cross-validation to ensure stable performance estimates. They monitored model metrics such as mean absolute error, because exact second-level predictions were less important than being in a small error range that would prevent schedule overruns.
They deployed the model to the route-planning system. Predictions were combined with driving time estimates to generate daily schedules. They tracked performance by comparing predicted vs. actual durations from new geofence data. That feedback loop helped refine the model’s feature set and re-tune hyperparameters.
Core mathematical representation
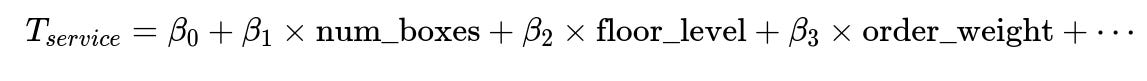
Where T_service is the predicted service time for each stop. beta_0 is the intercept, beta_1 through beta_n are model coefficients capturing the effect of num_boxes, floor_level, order_weight, and other key factors. These parameters are learned by minimizing prediction error on labeled service time data.
Example implementation details
Engineers created a pipeline with the following steps: They ingested raw geofence timestamps from the driver devices, computed each stop’s duration, merged that with existing order and customer data, and stored the combined records in a feature store. The training script used Python, along with a library such as scikit-learn or XGBoost, to fit the model. They used an internal continuous integration process to test each iteration and automatically retrain when new data arrived.
They validated that changes in driver behavior or new route designs would not break the model. They also measured how well the model generalized by checking results on recently delivered orders from new addresses. They found that model performance improved with each iteration of feature engineering and data enrichment.
They updated the route scheduler using the model predictions. They implemented a fallback scenario if the model encountered missing data or large outliers. They set up automated alerts for sudden changes in average predicted vs. actual service time. That real-time monitoring detected data drifts, such as changes caused by seasonal demand shifts.
They defined success by comparing on-time delivery rates, driver satisfaction scores, route-efficiency metrics, and distribution costs before and after the model’s deployment. Reductions in late deliveries, fewer missed time windows, and stable or decreased driver stress levels validated the approach.
What if the data is noisy or missing?
Engineers handled noisy or partial geofence data by examining device logs for connectivity issues. Intermittent location tracking created incomplete timestamps. The final pipeline flagged stops missing enter or exit events. The route scheduler applied fallback estimates for those records. Once engineers identified the cause of missing data, they refined hardware, network coverage, or the code capturing geofence events.
What if multiple deliveries happen within the same geofence?
Sub-sampling logic determined if a geofence radius should be smaller or if the deliveries should share a compound geofence with more advanced location checks. If more than one customer lived in the same building, the system either segmented the building by floor if possible or shrank the radius to only capture the correct entrance area. The system used order IDs or driver scanning events as secondary data sources. Data scientists excluded or specially handled those overlapping stops to ensure accurate durations.
How to handle driver acceptance and privacy concerns?
Driver buy-in was essential. The team explained that the purpose was operational improvement, not driver surveillance. They set a fixed retention period for raw timestamps and stored only durations in the analytical system. The privacy team confirmed legal compliance. Company leadership and driver representatives participated in the design discussions, ensuring open communication and trust.
How to handle model updates over time?
Data distributions can shift, so they scheduled periodic retraining. They implemented a monitoring system that compared new predictions with observed times. Large deviations triggered an investigation. Regular retraining allowed the model to adapt to changing conditions, such as new geographic regions, changes in driver routines, or seasonal trends in grocery orders.
How to ensure the model’s outputs are used in production decisions?
They integrated the final model’s predictions directly into the routing software. If the software had historically used a static service time, they replaced that logic with the model output. The changes were deployed through a controlled release process, starting with a small region or set of routes for A/B testing. Positive results led to broader rollout. Operations teams received dashboards to see real-time predicted vs. actual differences. That visibility fostered organizational trust in the model’s recommendations.