
ML Case-study Interview Question: Segmenting Multiple Products in Voice Orders Using Transformer-CRF


Browse all the ML Case-Studies here.
Case-Study question
A major e-commerce platform needs to handle multiple product reorders in a single voice command. The input is a voice utterance containing up to 10 product names. Automated Speech Recognition outputs text without punctuation. How would you build a system to segment this text into multiple product name entities and then add them to a shopping cart?
Detailed Solution
Overview
An Entity Transformer model can identify multiple product names in one user utterance. It uses a stack of transformer encoder layers combined with a Conditional Random Field (CRF) decoder. The system is trained on large-scale voice shopping data with synonym-based data augmentation, supporting up to 10 product entities per utterance.
Data Creation
Data augmentation involves randomly inserting synonyms for products. The training set can be large, such as 500k utterances, with each utterance containing 1 to 10 items. This helps the model handle varying phrase structures, product variety, and domain shifts.
Model Architecture
The model uses a transformer encoder plus a CRF decoder. Encoder input combines dense embeddings from a pre-trained language model (like BERT or another general-purpose transformer) with sparse features (one-hot encodings and character n-gram features).
Dense Features Extract them from a pre-trained model. Concatenate them with outputs from a small feed-forward network trained on token-level and character n-gram features.
Transformer Encoder Stacked transformer layers (up to 6) process the combined embeddings. Hidden dimension size can be 256, and the number of attention heads can be 4. Relative position attention ensures the model focuses on local dependencies better than absolute positions.
CRF Decoder The Conditional Random Field layer produces the final sequence labels (BILOU tagging scheme) for all tokens. The probability of a label sequence l given an input x is:
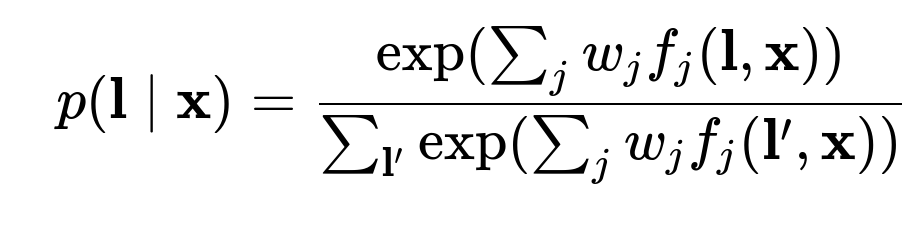
Here, p(l|x) is the probability of label sequence l given input x. The term w_j are trainable weights, and f_j(l, x) are feature functions capturing transitions and emissions in the CRF.
Model Training
Use standard minibatch training with cross-entropy loss integrated into the CRF layer. Combine masked language model embeddings with token-level features. Adam optimizer often works well. Early stopping or learning rate schedules can reduce overfitting.
Inference
Run a standard Viterbi or forward-backward decoding to find the best label sequence from the CRF layer. The model segments the input utterance text and returns multiple product name entities.
Example Python Snippet
import torch
import torch.nn as nn
from transformers import BertModel
from torchcrf import CRF
class EntityTransformer(nn.Module):
def __init__(self, hidden_dim=256, num_labels=10):
super(EntityTransformer, self).__init__()
self.bert = BertModel.from_pretrained("bert-base-uncased")
self.char_ngram_proj = nn.Linear(100, 64) # example dimension for ngram features
self.transformer_layer = nn.TransformerEncoderLayer(d_model=256, nhead=4)
self.transformer_encoder = nn.TransformerEncoder(self.transformer_layer, num_layers=6)
self.classifier = nn.Linear(256, num_labels)
self.crf = CRF(num_labels, batch_first=True)
def forward(self, input_ids, attention_mask, char_ngram_feats):
dense_feats = self.bert(input_ids=input_ids, attention_mask=attention_mask).last_hidden_state
proj_char_feats = self.char_ngram_proj(char_ngram_feats)
combined_feats = torch.cat([dense_feats, proj_char_feats], dim=-1)
# project to 256 for transformer
combined_feats = combined_feats.transpose(0,1) # (seq_len, batch, features)
encoded_output = self.transformer_encoder(combined_feats)
encoded_output = encoded_output.transpose(0,1) # back to (batch, seq_len, features)
emissions = self.classifier(encoded_output)
return emissions
def loss_fn(self, emissions, tags, mask):
loss = -self.crf(emissions, tags, mask=mask)
return loss
def predict(self, emissions, mask):
return self.crf.decode(emissions, mask=mask)
The bert module provides dense contextual embeddings. The char_ngram_proj layer handles one-hot or multi-hot token-level features. The transformer_encoder refines combined representations. The CRF layer handles final entity segmentation.
Results
This approach outperforms simpler baselines by a significant margin, especially when combined with pre-trained embeddings and character n-gram features. For example, it can yield around 12% higher accuracy on a test set with unseen products.
Why a Custom Transformer and CRF?
Transformers are good at learning deep contextual embeddings.
CRF ensures consistent labeling for adjacent tokens, preventing invalid label sequences.
Combining pre-trained embeddings with domain-specific features improves generalization.
How to Ensure Scalability?
Use a distributed data pipeline. Implement mini-batch gradient computation across multiple GPUs. Keep an efficient data loader to handle large sets of voice utterances.
How to Deal with New Products?
Retrain or fine-tune the model on data including synonyms for newly introduced products. Use a fallback approach to handle out-of-vocabulary words by either subword tokenization or approximate string matching.
How to Evaluate the Model?
Use metrics like F1 score, precision, and recall on a holdout set with unseen products. Evaluate system performance for up to 10 items per utterance. Collect manual annotations for final quality checks.
Would a Pure BERT Model Work?
It can work but often yields lower recall on rare product names. Adding char n-gram features handles subword information for unusual or brand-specific tokens. Using a CRF layer also improves sequence labeling accuracy.
Why Use Data Augmentation?
Voice utterances can be diverse. Augmentation with product synonyms increases coverage and prevents overfitting to specific phrasings. This is crucial in real-world deployment with thousands of product variations.