
ML Case-study Interview Question: Optimizing Email Sends: Predictive Net Value Models and Automated Retraining.


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a daily email sending decision system that optimizes the trade-off between customer engagement and unsubscribe risk. The goal is to determine which customers should receive a sales email, how frequently they should receive it, and to do so in a scalable, automated manner. You have historic data on customer behavior, including clicks, purchases, email unsubscribes, and other signals, plus an existing infrastructure to send daily promotional emails in multiple regions and brands. How would you build such a system, ensure it is well-integrated into a production pipeline, and continuously retrain and evaluate it over time?
Proposed Solution
Build a family of models that predict probabilities of key actions: customer purchase, customer unsubscribe, and inactivity. Combine those probabilities with estimated revenue and unsubscribe costs to form a net value. Translate that net value into an actionable decision, deciding which customers get daily emails and at what weekly frequency.
Use a robust retraining pipeline to handle data ingestion, feature engineering, model training, and validation. Automate frequent retraining to capture changing user behaviors. Implement a governance process to map model outputs into practical sending thresholds. Conduct A/B tests to validate performance improvements and ensure new models do not degrade key metrics.
Below is a detailed explanation, referencing each stage of the system.
Model Structure
Train three classifiers in parallel: Predict purchase probability if an email is sent. Predict unsubscribe probability if an email is sent. Predict the probability of no action.
Combine these probabilities with business-based gains and costs.
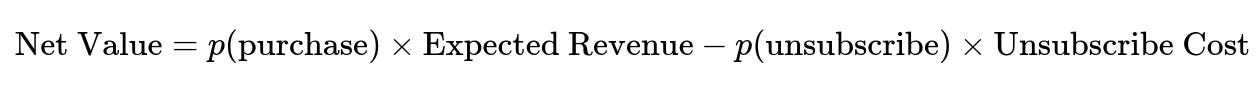
Where p(purchase) is the probability of a customer making a purchase after receiving a sales email, p(unsubscribe) is the probability of unsubscribing, and p(no action) = 1 - p(purchase) - p(unsubscribe).
Model Inputs
Select hundreds of customer features such as page views, add-to-cart rates, historical email clicks, orders, and preference signals. Include time-based features that capture recency of user engagement. Use correlation checks and feature importance to narrow the list.
Automated Retraining Pipeline
Set up a pipeline that monitors model performance and triggers retraining. Periodically gather fresh data by sending randomized email frequencies to a holdout set for unbiased samples. Recompute the features for each customer, retrain the models, compare performance metrics, and move the new model into production if performance passes validation checks. Store the final model in a scoring workflow that updates daily email decisions.
Send Decision Governance
Rank customers by net value. Bucket them into scored bins. Assign sending frequencies (7 emails/week, 3 emails/week, etc.) based on the net value bucket. Calibrate these thresholds through offline backtesting and confirm them with small-scale A/B tests before broad rollout.
A/B Testing
Compare your new system with existing strategies: Measure unsubscribe reduction. Measure revenue retention or any gain/loss in core engagement metrics. Roll out if you see significant unsubscribe reduction without revenue loss.
Future Enhancements
Use Reinforcement Learning to automate the selection of send thresholds. Incorporate deep embeddings from recommendation systems if performance gains justify the additional pipeline complexity.
Use object-oriented software design to make the system scalable for new models. Add new channels (such as push notifications) by introducing parallel model classes that share standard training interfaces. Maintain a single retraining pipeline to reduce operational overhead.
What if the model underestimates unsubscribe probability?
Calibrate the unsubscribe model more frequently. Increase training data from underrepresented segments that have higher unsubscribe risk. Use stricter thresholds for high-risk segments. Conduct targeted tests to see if unsubscribes spike for any particular bin.
How do you handle seasonality and shifting behavior over time?
Schedule frequent retraining to capture holiday-driven purchasing patterns or macro shifts. Incorporate rolling windows of recent data for training. Continuously monitor metrics on a dashboard and trigger retraining if you see unusual drops in AUC or rising unsubscribe rates.
How do you address data leakage and ensure unbiased training?
Segment a random holdout for final validation. Randomize email sends for that subset to avoid self-fulfilling behaviors, where you only see data for those who are already engaged. Avoid using real-time signals for features that would not be available at inference time. Keep a consistent time gap between feature extraction and outcome labeling.
How do you validate the model before launching it to production?
Backtest the model by simulating historical decisions. Compare the predicted net value to actual outcomes over a past window. Confirm that predicted high-value bins show higher conversions and lower unsubscribes. Then run an A/B test where a portion of your population is scored by the new model and the rest remains on the old system. Evaluate the difference in unsubscribe rates, revenue, and engagement metrics.
What is your approach for scaling across multiple regions and brands?
Parameterize the pipeline so it can process region-specific data sets. Reuse shared features but allow region-specific transformations. Maintain a flexible design that can incorporate brand differences in user behavior. Run separate retraining processes for each region while reusing the same pipeline code base to reduce operational costs.
How do you select sending thresholds?
Rank each customer by net value. Generate a sorted list of scores. Choose thresholds that create distinct frequency tiers. Conduct small-scale tests to confirm that each threshold effectively segments the population. Tweak threshold boundaries if you see suboptimal unsubscribe or engagement behavior in certain tiers.
How would you respond to changes in mailing infrastructure or new regulatory requirements?
Isolate the pipeline from lower-level systems via stable feature definitions. If new data sources become available, incorporate them into the feature store with consistent transformations. Maintain compliance with privacy requirements by restricting access to only those features allowed under regulations. Document all training data and ensure logs can be audited.
How do you detect and correct model decay?
Set daily or weekly performance monitors for conversions and unsubscribes in each bin. Track aggregate model performance (AUC, calibration, etc.). Retrain if performance dips below a preset threshold. Investigate data drift, changes in user preferences, or possible distribution shifts. Confirm with domain stakeholders whether the pipeline should be re-run immediately or if it is a temporary fluctuation.
How do you ensure your code base is maintainable?
Write modular Python classes for feature computation, model training, and evaluation. Abstract repeated logic for tasks like hyperparameter tuning or data cleaning. Adopt a standardized class hierarchy so new models inherit from base classes. Keep consistent logging and configuration styles. Use version control tags for each retraining cycle.
How do you mitigate the cost of testing model combinations?
Implement a carefully planned backtesting strategy that reuses historical data for stable comparisons. Limit the number of production A/B tests by validating in simulation first. Perform multi-armed bandit tests to select promising configurations with fewer resources. Monitor real-time logs to halt underperforming variants quickly.
How would you incorporate advanced methods like Contextual Bandits?
Define a reward signal that accounts for purchases and unsubscribes. Feed user features into a bandit algorithm to dynamically select email frequency. Update the bandit’s policy as new data arrives. Maintain a fallback (rule-based approach) if the bandit’s performance degrades. Ensure the pipeline can handle real-time or near real-time decisions with the new algorithm.
How do you add deeper product embeddings?
Collaborate with teams that build product recommendation or search embeddings. Join these embeddings to your training data, ensuring consistent user-product relationships. Evaluate offline if the embeddings raise AUC or reduce unsubscribe rates. Monitor model size and training time to keep your pipeline efficient.
How do you justify the complexity of a more advanced model?
Compare gains from new features or architectures against operational costs. Demonstrate net improvements in user engagement or unsubscribes. Factor in developer time to maintain the pipeline. Propose experiments to confirm if certain features add enough predictive lift to justify the overhead. Use incremental releases, enabling a phased approach to advanced modeling.