
ML Case-study Interview Question: Content-Based Image Retrieval Using Classification and Semantic Word Embeddings


Browse all the ML Case-Studies here.
Case-Study question
A major cloud-based platform has an enormous dataset of user-uploaded images. The product team wants a system that allows users to type text queries (example: "picnic", "shore", or "beach ball") and instantly retrieve images that match the query's content. The images often do not have descriptive filenames, so traditional text matching is insufficient. The company needs a scalable solution that analyzes each image’s content for relevant objects, scenes, or attributes and returns the highest-matching images. How would you design and implement this end-to-end system, ensuring low-latency searches, multi-language support, and minimal storage overhead?
Detailed Solution
Core Idea
A function s = f(q, j) maps a text query q and an image j to a relevance score. A high score indicates the image matches the query’s content. The approach uses two key components: a multi-label image classifier to determine what each image contains, and word vectors to capture semantic meaning of query words.
Where:
q is the user’s text query.
j is the image under consideration.
s is the relevance score.
Mapping Queries and Images into a Common Space
A trained image classifier produces a vector j_c that represents how likely the image j is to contain each possible category. A word embedding system generates a vector for each word in the query. Transforming that query vector q_w into the same “category space” as j_c involves multiplying q_w by a projection matrix C whose columns are the category name embeddings. This yields q_c.
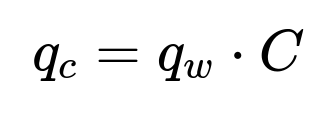
Where:
q_w is the query word vector in word-vector space.
C is the matrix of all category name word vectors (each column is a category name’s vector).
q_c is the resulting query representation in category space.
Then compute the final relevance score as the dot product of q_c and j_c.
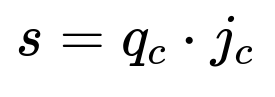
Where:
j_c is the image’s category-score vector from the classifier.
q_c is the query’s category-space vector.
s is the final score.
Model Architecture
An image classifier (such as EfficientNet) is trained on a large multi-label dataset (for example, Open Images). The classifier outputs a category-space vector j_c of size C (several thousand). Each position of j_c indicates how likely the image belongs to that category.
A word embedding model (such as ConceptNet Numberbatch) encodes each query word into a vector q_w of dimension d (hundreds of dimensions). Multiplying q_w by the matrix C transforms q_w into q_c.
Implementation Approach
Existing text-search infrastructure can be adapted to handle these large category vectors:
Each image’s top 50 nonzero classifier outputs are retained as a sparse vector (j_c). Values smaller than the 50th largest score are dropped. This shrinks a 10,000-dimensional vector to 50 nonzero entries.
Each user query q is similarly mapped to category space but only retains the top 10 nonzero entries of q_c.
A forward index stores each image’s sparse j_c. An inverted index maps each category to the images that have a nonzero score for that category.
At query time, the system reads posting lists for the query’s nonzero categories, aggregates matching images, and retrieves their j_c vectors for final score computation s = q_c j_c. This produces a ranked result list.
This design keeps storage feasible (a few hundred bytes per image) and query latency low (reading only a handful of posting lists instead of thousands).
Scalability and Optimization
Only a small subset of categories are stored for each image. This prevents excessive index size and ensures fast lookups. The matrix C is also held in memory, allowing quick multiplication for each query. Vector dot products are cheap, especially after limiting vectors to their top nonzero entries.
Multi-language Support
Word embeddings like ConceptNet Numberbatch capture similar vectors for semantically identical words across multiple languages. Queries in different languages map to similar q_w vectors. No separate translation step is required.
Future Extensions
A similar method can be explored for video search by segmenting video frames and applying the same classifier to each frame. In practice, the storage overhead and the need to index a potentially large number of frames per video remain open challenges. A sampling approach or more advanced video embedding methods may help.
How would you handle synonyms or hierarchical concepts?
Multilingual word vectors naturally handle many synonyms. For hierarchical concepts like “fruit” vs “apple,” the word vectors ensure that “apple” is close to “fruit” and also close to synonyms like “granny smith.” The dot product between “shore” and “beach” will be high, so images tagged as beach are also retrieved for “shore.”
What if a query contains multiple words, or phrases like “beach ball”?
Split the query into individual words. Parse them with an AND operation. For multi-word phrases like “beach ball,” treat that phrase as a single token if it appears in a known multi-word list. In that case, run the query as (beach AND ball) OR (beach ball). This ensures relevant images are not missed.
How do you maintain and update the index for millions of images?
Use a pipeline:
New or modified images are sent to the classifier in batches.
The classifier outputs the category space vector j_c.
Only the top 50 nonzero entries are kept. The forward and inverted indexes are updated accordingly. This batch-based approach scales to large volumes of updates.
What happens if many categories overlap for an image?
High overlap among categories (like “outdoors” and “forest”) is expected. The classifier model outputs multiple labels per image. Storing the top 50 categories captures the primary concepts, while minor categories remain truncated. This keeps indexing overhead manageable.
How do you ensure query latency is low?
Limit each query to the top 10 categories in q_c. Only those inverted lists are scanned. This is on par with text search, where a typical query has a handful of words. Then do a final dot product with each candidate image’s top 50 categories to compute the relevance score.
How do you evaluate the system’s accuracy?
Collect sets of images with known relevant descriptions. Compute metrics like precision, recall, or mean average precision. A/B test with real user queries. Track how often a user retypes or refines a query to measure satisfaction.
Could this approach be extended to video search?
Yes. Extract frames periodically from each video. Run the same classifier on each frame to build a video-level index. Large numbers of frames per video impact storage and indexing speed. A sampling or specialized video embedding approach can help manage overhead. The same word vector logic applies to text queries.
What is your strategy for handling completely unseen words?
If the embedding model has no vector for a rare query word, skip that word or fall back to standard textual metadata search (filenames, captions). In practice, large pre-trained embeddings cover most terms.
How do you handle user queries with no matching images?
Return no results if all dot products are below a threshold. Offer suggestions based on synonyms or partial matches. Show alternative queries or fallback results from textual metadata search to guide the user.
How would you approach expanding the model to new categories?
Retrain or fine-tune the classifier on an extended dataset. Rebuild or augment the index with vectors for newly added categories. Keep the same pipeline structure. The word embedding mapping remains unchanged because new categories also receive embedded names.
Final Thoughts
Combining a multi-label image classifier with word embeddings produces a robust image search engine. Sparse indexing strategies ensure storage and latency remain acceptable. This design generalizes well across languages and can be expanded to future applications like video indexing.