
ML Case-study Interview Question: Scalable In-Video Text Search Powered by Contrastive Learning Embeddings.


Browse all the ML Case-Studies here.
Case-Study question
A major streaming service needs an in-video search system that allows creatives to locate specific scenes, objects, or moments across a huge catalog of full-length video assets. Teams want to build a text-based query interface. They wish to embed content at scale for real-time lookups. Propose a system design and machine learning solution for solving this, focusing on how you would build and fine-tune a contrastive learning model on custom in-house video data, store embeddings, and ensure low-latency query performance. Outline your end-to-end approach and technical architecture.
Proposed Solution
Contrastive learning aligns video data with text. A video encoder processes visual frames, and a text encoder processes textual descriptions. Matching text-video pairs have high similarity in a shared embedding space. Unmatched pairs are forced apart.
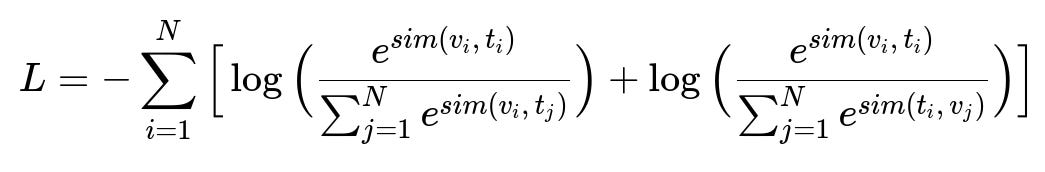
Here:
N is the batch size.
v_i is the embedding of the i-th video clip.
t_i is the embedding of the i-th text prompt.
sim(a, b) is the cosine similarity between embeddings a and b.
When training, in-batch negatives give strong gradient signals because each sample is contrasted against all others. Shot-level embeddings are computed by segmenting each video into smaller shots, then running the encoder on that shot. Simple averaging of per-frame embeddings often works. Aggregating these shot-level embeddings and then fine-tuning on real production data significantly improves performance.
Data Preparation and Training
Shots are obtained by segmenting videos on a CPU-based pipeline. Resulting clips are stored in an object store. A GPU-based system streams these clips for batch inference. Training runs on a distributed framework for efficiency. Using an internal set of video descriptions ensures the model learns domain-specific representations that generalize beyond standard image-text data. Fine-tuning employs textual data with carefully curated descriptions of specific scenes, objects, or actions.
Embedding Storage and Indexing
The final shot-level embeddings are stored in a feature store. A separate system indexes them for nearest neighbor lookups. Users submit text queries, which are embedded by the text encoder. The system then performs a similarity search over the precomputed shot embeddings. Elastic search or a vector database can be used. The user can limit searches to specific sets of shows or run a catalog-wide query.
Scaling the Pipeline
Shot segmentation is CPU-intensive. Video-to-embedding encoding is GPU-intensive. Parallelizing CPU tasks first ensures GPU usage remains high. Storing shots in mp4 format on an object store and streaming them to the GPU nodes with prefetching reduces idle GPU time. This approach maintains throughput. The system handles new video uploads by automatically triggering embedding generation. Training or inference jobs occur repeatedly to keep data fresh.
Practical Implementation Example
A minimal Python snippet for reading and embedding shots:
import torch
import cv2
model_video_encoder = ... # Loaded pretrained model
def generate_shot_embedding(mp4_path):
cap = cv2.VideoCapture(mp4_path)
frames = []
while True:
ret, frame = cap.read()
if not ret:
break
frames.append(process_frame(frame)) # Possibly resizing, normalization
cap.release()
# Mean-pool or pass into a temporal module
stacked_frames = torch.stack(frames).to(device)
embedding = model_video_encoder(stacked_frames)
shot_embedding = torch.mean(embedding, dim=0)
return shot_embedding
Explanations:
A shot is read frame-by-frame.
process_frame is a placeholder for model-specific transforms.
torch.mean pools frame embeddings into a single vector.
The final embedding is stored for search.
Query Mechanism
A user query is converted to an embedding using the text encoder. A cosine-similarity lookup finds the nearest shot embeddings. The system returns shot references or timecodes. This approach supports searching for specific objects, lines of dialogue, or high-level concepts like “dramatic closeup” or “car explosion.” Custom text encoders detect domain terms learned during training.
Value Added
Creators locate target clips faster. A single text prompt can retrieve all relevant shots across large catalogs. This saves time and enables richer promotional assets. The approach generalizes to various use-cases like building highlight reels, searching for recurring visual elements, or scanning entire catalogs for rare events.
How would you handle domain-specific elements not present in standard text-image datasets?
Models pretrained on general data often miss unique show features. Fine-tuning with in-house data is critical. Rare show-specific entities or fictional creatures need direct supervision. Collect text descriptions from script outlines or curated annotation tasks that reference domain-exclusive terms. Add these examples to training. The model then maps these new terms to correct visual embeddings. The shot encoder is updated, so it aligns each visual representation with the domain-specific text.
How do you improve retrieval quality if text queries are noisy or incomplete?
Augment the text encoder with synonyms or embeddings from a language model that can interpret partial or misspelled queries. Use lexical matching to refine ambiguous queries. Incorporate a re-ranking step that re-scores top results using cross-attention or second-stage language-image alignment. Continually monitor user feedback on retrieved shots to finetune the text encoder for actual search patterns. If a user frequently modifies certain queries, incorporate synonyms or expansions for those terms. This iterative feedback loop refines the system over time.
How do you measure the success of this system, and what metrics do you track?
Evaluate precision and recall of retrieved shots for a given query set. Use a validation dataset with known relevant shots. Track average precision at K, recall at K, and mean reciprocal rank. Observe user satisfaction metrics like search abandon rates or time spent verifying the results. A/B testing with video editors or end users helps quantify usability improvements. Monitor inference latency, GPU utilization, and indexing overhead. If queries become slow, optimize the vector database or use caching. If accuracy metrics lag, expand training data or incorporate multi-modal fine-tuning strategies.
Why might an unparameterized aggregation like mean-pooling outperform a specialized temporal model?
Short shots often contain consistent frames. A heavy temporal model may overfit or reduce generalizability. Mean-pooling can be robust for short, fairly homogeneous clips. For longer sequences with dynamic changes, temporal awareness might help. Testing both approaches on an internal dataset clarifies trade-offs. Sometimes a multi-scale approach, combining mean-pooling with limited temporal attention, offers the best of both worlds. Start simple, benchmark, and evolve as needed.
How do you adapt the system for multi-language support?
Train the text encoder on multilingual caption pairs. If certain languages are important, gather domain-specific text-video pairs in those languages. Use subword tokenization. The rest of the pipeline remains the same. The same shot embeddings are used, but text queries from different languages map into that shared space. Evaluate cross-lingual retrieval by checking whether text queries in language A match relevant scenes annotated in language B. If bridging multiple languages, ensure enough training data for each.
How does video-to-video search emerge from these embeddings?
Shot embeddings contain a robust visual signature. Query with another shot’s embedding instead of text. The system locates similar video segments. This is helpful for finding repeated scenes, references, or derivative content. This extension requires no extra training. Reuse the existing vector index, but treat the input shot as the “query.” Compare embeddings via cosine similarity. Adjust thresholds for more or less stringent matching. This allows direct video-based exploration without text queries.