
ML Case-study Interview Question: Leveraging Text Embeddings to Improve Real Estate Listing Recommendations.


Browse all the ML Case-Studies here.
Case-Study question
You have a real estate portal with millions of property listings. Existing recommendation systems rely mostly on structured property data like price, bedroom count, and property type. The goal is to boost recommendation quality by incorporating textual listing descriptions. Your task is to design an end-to-end system that transforms raw listing descriptions into embedding vectors and integrates these vectors into multiple recommendation services, such as “Similar Homes,” “Global Relevance Sort,” “Home Recommendations,” and “Personalized Search Ranking.” The system must:
Generate text embeddings daily at large scale (over two million listings).
Store embeddings efficiently for easy retrieval and inference.
Integrate seamlessly into downstream recommendation pipelines.
Increase offline metrics (nDCG, MAP, MAR, MAF1) and eventually improve real user engagement in production.
Explain how you would build this system from data ingestion and model training to pipeline orchestration and integration with existing recommendation models.
Detailed solution
Text embeddings capture semantic features that structured columns may miss. Word2Vec, GloVe, BERT, Doc2Vec, or TF-IDF-based embeddings can highlight subtle aspects of the listing text, such as references to “golf course,” “waterfront,” or “downtown location.” Building such embeddings involves several steps.
Data ingestion loads textual listing descriptions alongside standard tabular features. Model training uses these text descriptions to learn vector representations. Word2Vec skip-gram or continuous bag of words approaches optimize for probabilities of surrounding context words given a target word. Large corpora are crucial to capture diverse semantics. An example objective function for the skip-gram model is shown here:
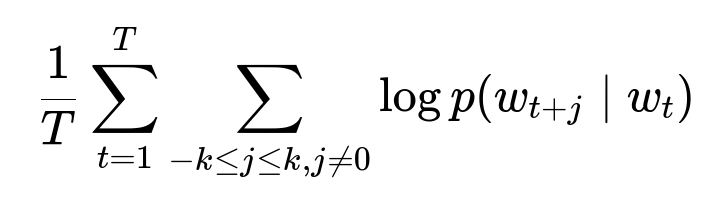
T is the total number of words. w_t is the target word at position t. k is the window size. p(w_{t+j} | w_t) is the probability of seeing context word w_{t+j} given w_t. Each embedding vector is learned by maximizing the likelihood of seeing actual context words around the target words.
Training proceeds offline on a large dataset (over ten million listing descriptions). Visualizing embeddings with t-SNE or UMAP checks that semantically related listings form clusters. Storing the trained model file in a cloud storage location (for instance S3) makes the model accessible to a production pipeline.
Daily embedding generation uses a scheduled workflow, often orchestrated with Airflow. The pipeline fetches the model and the latest listing descriptions, infers embeddings for each listing, and writes them back to cloud storage. Generating two million embeddings in under ten minutes typically requires distributed computing or GPUs for deep models like BERT. Building a flexible codebase means substituting Word2Vec with GloVe or BERT if needed, simply by specifying configuration parameters.
Integration with downstream recommendation systems enriches each model with text-based features. The “Similar Homes” pipeline can retrieve nearest neighbors in embedding space, capturing richer semantic similarity than price or location alone. “Global Relevance Sort” and “Personalized Search Ranking” can incorporate the embedding vectors into their scoring functions. Offline experiments compare new metrics (nDCG, MAP, MAR, MAF1) for models with vs. without text embeddings. Gains in these metrics indicate that text captures valuable signal, especially for sparse listings like vacant properties that have fewer structured attributes.
Running online A/B tests measures real user engagement. If the recommended homes with text embeddings lead to more clicks or more property saves, the approach is validated in production. Scaling the system for multiple embedding architectures involves abstracting model loading, inference, and data transformations so different teams can plug in their own text models if necessary. This approach fosters collaboration and uniformity while still allowing experimentation with new architectures or hyperparameters.
Below is a small Python snippet showing how the pipeline might process new listing text with a pre-trained Word2Vec model using the Gensim library. The snippet demonstrates inference of a simple average of word vectors for a given description:
import gensim
import numpy as np
model = gensim.models.Word2Vec.load("path_to_trained_model")
def compute_embedding(description):
words = description.split()
valid_words = [w for w in words if w in model.wv]
if not valid_words:
return np.zeros(model.vector_size)
vectors = [model.wv[w] for w in valid_words]
return np.mean(vectors, axis=0)
# Example usage:
description = "Beautiful home located near golf course and lake."
embedding_vector = compute_embedding(description)
In production, run such inference at scale using your data pipeline. Cache the final embeddings so multiple recommendation modules can fetch them quickly. Verify that each recommendation system integrates the new embeddings into its existing features, then measure gains in offline metrics and proceed to live experiments.
How would you measure success in offline metrics vs. real-world impact?
Offline measurement uses nDCG, MAP, MAR, and MAF1. nDCG measures ranking quality based on relevance judgments. MAP focuses on precision across multiple queries. MAR tracks recall. MAF1 blends precision and recall at the query level. Higher metrics mean better ranking performance on historical data. Real-world impact appears in A/B tests. Higher click-through rates, longer session lengths, or improved user satisfaction confirm that these embeddings help. Offline gains must show improvements before devoting resources to online testing.
Explain that strong offline results do not always translate perfectly to online gains because user behavior can differ from historical data. This is why a robust A/B test is essential. The pipeline design must allow toggling embeddings on or off to isolate and measure their effect.
How can you ensure the pipeline handles new data or new models without high maintenance?
Flexible configurations define which model to load, which hyperparameters to set, and what embeddings size to compute. Storing each trained model under versioned file paths in S3 allows rollback or updates. Docker images standardize dependencies across environments. An Airflow DAG orchestrates tasks, so incremental updates occur without rewriting large parts of the code. Well-designed interfaces let teams add new model classes with minimal code changes.
Why do text embeddings help more with sparse listings, such as vacant properties?
Sparse listings lack abundant structured data. Embeddings capture signals from free-form text like references to unfinished basements or proximity to local landmarks, bridging gaps when numeric attributes are limited. A vacant property with minimal bed/bath data and no occupant details still has a descriptive blurb about location or potential usage. Text embeddings surface that information.
How do you handle computational cost if you switch to BERT or larger deep models?
Distributed inference or GPU-based acceleration keeps processing times within acceptable limits. Preprocessing the text (tokenization, truncation) reduces overhead. Monitoring pipeline performance ensures embeddings complete within daily batch windows. If BERT proves too slow or expensive, approximate methods like knowledge distillation or fine-tuning smaller Transformer variants might help.
Why would you keep multiple embedding strategies (Word2Vec, GLoVe, BERT, TF-IDF) instead of just one?
Different models excel at different nuances. BERT captures context-sensitive semantics but is heavier. Word2Vec is lightweight and easy to train at scale. TF-IDF can provide a simple baseline that works surprisingly well for certain tasks. Storing multiple embeddings leaves room for experimentation. Automated model selection or ensemble methods can pick the most effective representation per listing.
How do you handle out-of-vocabulary words or brand-new phrases in listing descriptions?
Word2Vec or GLoVe skip unknown words by default. BERT handles subwords with WordPiece. Rare tokens get broken into known subword units, preserving partial semantic meaning. A fallback embedding (e.g. zero vector or average of subwords) keeps the pipeline running. Regular model retraining helps incorporate new vocabulary appearing in fresh listings.
When ranking similar properties, how do you handle thresholding on text similarity?
A simple approach computes cosine similarity between embedding vectors. A threshold or top-K retrieval yields the final set of similar homes. Hyperparameters get tuned via offline metrics. If text similarity is too strict, relevant properties may be excluded. If too loose, irrelevant listings may appear. Balancing this threshold is crucial and can be tested with grid searches or Bayesian optimization on labeled data.
How can you guard against unintended biases in text embeddings?
Text data sometimes contains implicit biases. Certain words may cluster in ways that reflect stereotypes. Monitoring embeddings for sensitive terms or measuring fairness metrics helps detect issues. Techniques like debiasing word embeddings or controlling model usage for protected attributes can mitigate harm. Thorough data checks, bias detection tests, and domain-specific constraints prevent unethical outcomes.
How do you evaluate whether embeddings generalize beyond the “Similar Homes” recommendation?
Experiment with multiple pipelines (Global Relevance Sort, Personalized Search). Insert the text embedding vector into these ranking algorithms as an additional feature. Offline replays measure changes to user relevancy metrics. An A/B test per pipeline confirms real-world improvements. If the text-based features keep yielding lifts in different contexts, they generalize well.