
ML Case-study Interview Question: Unsupervised Asian Product Title Segmentation Using Character Embeddings and GRUs.


Browse all the ML Case-Studies here.
Case-Study question
You are given a large e-commerce platform that needs an unsupervised method of segmenting product titles in languages like Korean, Chinese, or Japanese. Manual labeling is expensive and often inaccurate for these languages. The goal is to develop a character-level segmentation system that automatically learns where to split words in product titles or user-typed queries, boosting the quality of search and recommendation outcomes. How would you design, implement, and optimize such a system to handle these language-specific challenges without relying on labeled data?
Detailed Solution
Background
Modern language models often use supervised segmentation and white-space delimiters. This does not work well for Asian languages. Traditional labeled segmentation corpora are usually compiled from news or formal documents, which differ greatly from the informal product titles or user queries. A purely unsupervised system can automatically learn segmentation rules from raw product titles without human annotations.
Core Components
The approach has three parts:
Character Embedding Model
Forward and Backward Language Models
Word Segmentation Algorithm
All parts work in tandem and rely solely on unlabeled product titles.
Character Embedding Model
Each character in the dictionary is converted into a one-hot vector, whose dimension matches the total number of possible characters. These one-hot vectors then get projected into a lower-dimensional dense representation (embedding). This embedding model is trained in an unsupervised manner, learning to predict a target character from its context.
For a product title T = c_{q1}, c_{q2}, c_{q3}, …, c_{qn}, each character c_{qi} is surrounded by contexts such as c_{qi-2}, c_{qi-1}, c_{qi+1}, c_{qi+2}. Summing or concatenating those one-hot context vectors and projecting them yields a dense embedding that captures character co-occurrence patterns. This embedding significantly helps downstream language models.
Forward and Backward Language Models
Two Gated Recurrent Unit (GRU)-based language models process the character sequence from left-to-right (forward) and from right-to-left (backward). The forward model predicts how likely a given character is to appear after a preceding context. The backward model predicts how likely it is to appear before a following context.
Each language model outputs an embedding prediction c_{qi}', which is then compared to the actual embedding c_{qi}. Probability of the correct character can be computed using the reverse exponent of the Euclidean distance. One central formula is:
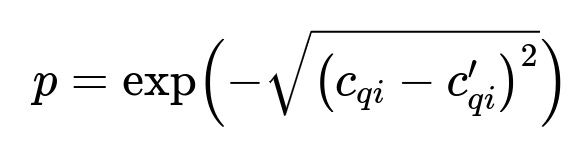
Here, c_{qi} is the true embedding of a character and c_{qi}' is the predicted embedding. A higher probability indicates a better match between predicted and actual embeddings.
Word Segmentation Algorithm
Characters “compete” to belong either to the preceding word or the following word based on the forward model probability versus the backward model probability. If the backward model’s probability is significantly higher for a character, you initiate a new word boundary to the right of that character.
Below is a compact pseudo-code:
Input: product title T = c_q0, c_q1, c_q2, …, c_q(n-1)
Output: a word boundary sequence S of T
0 forward_start_pos = 0
reverse_start_pos = n - 1
1 for i in range(1, n - 1):
2 seg_score = F(SUB_SEQ(forward_start_pos, i - 1))
- R(SUB_SEQ(i + 1, reverse_start_pos))
3 if seg_score > seg_score_threshold:
4 forward_start_pos = i
5 S ← i
6 return S
Here:
F is the probability from the forward model.
R is the probability from the backward model.
seg_score_threshold is a hyperparameter that prevents excessive splitting.
Example: Take “사생활보호필름” (meaning “privacy-protection-film”). The system checks middle characters, compares forward and backward probabilities, and splits into “사생활” and “보호필름” once it sees that “활” should join the first chunk and “보” is more probable to start a new chunk.
Practical Implementation Details
Data Collection: Gather raw product titles (potentially billions of them).
Preprocessing: Clean unusual symbols, unify repeated characters, remove extremely short titles.
Training:
Train the character embedding model using context windows (e.g. size 4).
Train forward and backward GRU-based language models on the same text.
Threshold Tuning: Adjust seg_score_threshold so the final segmentation balances correctness with not over-splitting.
Expansion to Other Languages
The same system works for Chinese or Japanese if you feed the language-specific product titles into the embedding and language models. Because it does not rely on labeled data or a dictionary, it is portable with minimal changes.
Why This Works
It learns from raw data with zero labeling effort.
It captures context in both directions.
The “competing” probability approach yields meaningful word boundaries.
Potential Improvements
Use larger context windows or more advanced networks like Transformers if resources permit.
Add morphological clues or external lexical resources to refine segmentation.
Combine subword embeddings with character-level embeddings for complex languages.
Follow-up Questions and Detailed Answers
1) How do you handle out-of-vocabulary characters or those rarely seen in training?
This is tricky for character-based systems. If a rare character does not appear enough, its embedding might be less accurate. One practical remedy:
Substitute extremely rare characters with an “unknown” token.
Group some rarely seen characters if they share contextual patterns.
Incrementally retrain or fine-tune embeddings as new product titles emerge.
2) What if the forward and backward probabilities are often similar for certain sequences?
Use a hyperparameter margin when comparing the probabilities. If |F - R| is small, do not split. If you still need more granular control, incorporate a small penalty for each new boundary to avoid splitting too frequently. Calibration can be done by comparing segmentations to any partial ground truth or by using feedback from downstream tasks (search or recommendation accuracy).
3) How do you ensure the system scales to billions or trillions of product titles?
Distributed Training: Split data across worker nodes. Use frameworks that handle big data sets in parallel.
Mini-batching: Train language models in small batches to fit GPU memory.
Sharding: Break the dictionary of characters and product titles into manageable chunks.
Checkpointing: Regularly checkpoint so you do not lose progress in large-scale training.
4) Can you integrate subword or morphological rules for a language like Korean, which has intricate composition rules for characters?
Yes. You can incorporate morphological analyzers or consider sub-syllabic decomposition. Another idea is to feed Hangul Jamo (basic Korean letter units) into the embedding model. Combining morphological knowledge with data-driven embeddings often yields improved segmentation for highly agglutinative languages.
5) How do you measure the quality of segmentation without labeled ground truth?
Use proxy evaluations:
Downstream metrics: If segmentation improves search or recommendation metrics, it is likely better.
Pseudolabel approach: Weakly label a small random subset with manual or partial dictionary methods. Compare segmentation to these small references.
Statistical checks: Ensure average word length and segmentation frequency align with known language patterns.
6) What if your segmentation over-splits brand names or domain-specific terms?
In domains like e-commerce, brand names and domain-specific tokens often defy normal language rules. You can:
Whitelist known brand names or recognized domain-specific tokens.
Reassign those tokens as single units in post-processing.
Keep a growing dictionary of recognized tokens from user clicks or search logs.
7) How does the Euclidean distance approach differ from a standard classification approach?
A standard classification approach would demand a fixed vocabulary of characters or words with labeled next-token probabilities. Here, we compare embeddings in a continuous vector space. This bypasses the need for pre-labeled data, letting the system measure similarity purely based on learned embeddings. It is more flexible than classification-based next-token predictions.
8) Why use GRU over LSTM or Transformers?
GRU has fewer parameters and less memory usage. It is simpler to train at massive scale.
LSTM or Transformers might yield better performance, but require more resources.
Starting with GRU is common in large-scale unsupervised tasks, then you can iterate based on performance or capacity.
9) How would you adapt this for languages like Thai or Vietnamese that also have unique spacing conventions?
The same character-based approach works if the training data is large enough. Thai has no standard word delimiters, and Vietnamese has diacritical marks. The model learns from raw usage patterns. However, additional rules or dictionary-based heuristics may further refine segmentations for languages with more complex orthographies.
10) How do you handle drifting language usage or new product categories emerging over time?
Retrain or fine-tune the embeddings and language models periodically with recent data. Keep a rolling window of product titles so new characters or slang are included. Monitor segmentation drifts by comparing performance in downstream tasks or average word lengths over time.
That completes the in-depth solution and follow-up exploration for how to build an unsupervised segmentation system for Asian languages in an e-commerce setting.