
ML Case-study Interview Question: Boosting Email Engagement: Generative AI Subjects Validated by a Reward Model


Browse all the ML Case-Studies here.
Case-Study question
Your team sends emails containing a single user-generated post to drive engagement on a large-scale community platform. You are tasked with improving email subject lines to increase clicks and user sessions. The user-generated subject lines often contain greetings and redundant content at the start, leading to low click rates and minimal user interactions. You have access to a Generative AI model and want to leverage it to produce more engaging subject lines. However, you must prevent spammy or misleading phrases, avoid hallucinations, and maintain authenticity. You also want to measure real-world effectiveness with small user buckets, then expand to the entire user base if results are positive. How would you design, train, and deploy a system that uses Generative AI to create engaging, authentic subject lines at scale?
The system should:
Explain how you would gather training data from user clicks, structure the Generative AI prompt, incorporate a reward model that decides whether to use the AI-generated subject line, manage serving costs, and handle monitoring. Outline how you would address concerns around hallucinations, spam-like phrases, performance drift, and fallback when the AI system fails.
Detailed In-Depth Solution
Generative AI alone may not guarantee higher clicks. A mechanism to evaluate the AI outputs before sending them to large audiences is necessary. Two major components are vital: a subject line generator and a reward model to score its outputs. The goal is to outperform the original user-generated subject lines while preserving authenticity and correctness.
Subject Line Generator
Use an off-the-shelf Large Language Model without fine-tuning. Prompt it to extract the post’s most interesting words verbatim. Limit rewriting. This preserves the user’s voice, removes unnatural marketing language, and reduces hallucinations. In plain text Python:
import openai
def generate_subject_line(post_content):
prompt = (
"Extract the most interesting part of the following post. "
"Output only those exact words without adding or removing anything. "
"Limit to ten words. "
f"Post: {post_content}"
)
response = openai.Completion.create(
engine="YOUR-MODEL",
prompt=prompt,
max_tokens=20,
temperature=0.7
)
subject_line = response["choices"][0]["text"].strip()
# Enforce final length cutoff
words = subject_line.split()
subject_line = " ".join(words[:10])
return subject_line
Reward Model
Train a separate classifier predicting if an AI-generated subject line yields more clicks than the user-generated line. Collect training data by randomly sending a small slice of users either the AI-generated line or the original user line. Use clicks as labels. Fine-tune a small classification model to output “Yes” if the AI line is predicted to outperform the user line, or “No” otherwise.
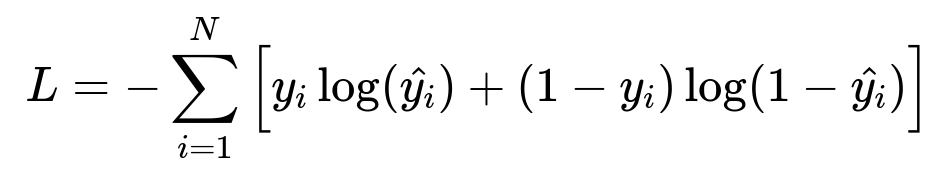
Where: y_i is 1 if the AI-generated line led to more clicks than the user-generated line, or 0 otherwise. hat{y_i} is the predicted probability from the reward model that the AI line will win.
After training, feed each post content and an AI-generated subject line into the reward model:
def reward_model_score(post_content, candidate_subject_line):
# Model takes post_content and candidate_subject_line
# Returns "Yes" or "No"
# Example (pseudo-code):
input_text = f"Post: {post_content}\nCandidate: {candidate_subject_line}"
response = openai.Completion.create(
engine="REWARD-MODEL",
prompt=input_text,
max_tokens=1,
temperature=0
)
return response["choices"][0]["text"].strip()
If the reward model says “Yes,” accept the AI-generated line. Otherwise, use the user-generated line.
Rejection Sampling
This process is a form of rejection sampling. Generate a single candidate from the generator. Evaluate its engagement potential. Reject the AI line if it lacks predicted lift. Accept it only if the reward model sees an advantage.
Cost Optimization
Cache the generated lines and their associated reward model outputs. Whenever a post reappears in future email sends, reuse the existing subject line. This avoids redundant OpenAI calls. The cost reduction can be huge if each post is shown to many recipients.
Monitoring and Retraining
Maintain a control group that always receives the user line, plus a small “always AI line” group. Compare real click data. If the reward model’s accuracy drops, retrain with newly gathered data. This catches preference shifts or unusual topics.
Fallback Mechanism
OpenAI calls may fail. Use retries with exponential backoff. If the generator or reward model is unavailable, revert to the user-generated line. This ensures system reliability.
Follow-Up Questions
How would you handle potential hallucinations in subject lines?
Hallucinations usually appear when the AI tries to invent content. Constrain the AI to extract exact phrases from the post. Avoid rewriting. If the post is short, there is less text to extract, so watch for empty or trivial lines. If the user content has many greetings, the extracted line may still be unhelpful. Consider fallback to the user’s own subject line in those edge cases.
Why might a reward model still produce wrong predictions?
Click behavior is complex. Preferences can vary by time, topic, or user demographics. A single global model might miss nuance. The training set may be imbalanced. Random noise in small-sample experiments could distort the model’s decisions. External factors like trending news or holidays can shift user engagement patterns. Regular monitoring and retraining mitigate these issues.
How would you personalize subject lines for different user segments?
Maintain a feature vector that includes user location, topic preferences, or past click data. Train a more advanced reward model that accounts for these features. Generate multiple candidate subject lines, then pick the best per user segment. Manage cost by caching frequently repeated content. Use a small fraction of traffic for exploration to learn more about user segment preferences.
How would you handle the cold-start problem for new posts with no historical data?
Use the generator to produce a subject line. Fall back to the user-generated line if uncertain. Gradually gather click data with a small user test group. As soon as enough feedback arrives, the reward model can decide which line to show. You can initialize the reward model with general text features, or incorporate external signals like content length or presence of images to guide early decisions.
What if the system inadvertently creates misleading or spam-like subject lines?
Introduce an additional filter that flags potential spam indicators (excessive punctuation, marketing keywords). Post-process the AI-generated line before the reward model step. If flagged, revert to the user’s line. Periodically review a sample of final subject lines to ensure authenticity. Include automated checks for policy violations if the platform has stricter spam rules.