
ML Case-study Interview Question: Real-Time Multi-Stage ML Ranking for Personalized Travel Search at Scale


Case-Study question
You are tasked with designing a high-scale, personalized search-ranking system for a global travel aggregator. Each search triggers queries across multiple shards of an availability engine, returns a large set of candidates, and must then rank these results with advanced machine learning models. The system must handle rapid lookups for slow-changing (batch) features and fast-changing (real-time) features. It must stay within sub-second response time at high percentiles. You must propose an end-to-end solution, including model serving, feature engineering, fallback mechanisms, and experimentation strategies. How would you design this? What core data pipelines, architecture components, and optimization approaches would you use?
Detailed Solution
An end-to-end ranking system must orchestrate several stages: data collection, model training, inference, caching, and experimentation. The goal is to deliver personalized results under tight latency constraints.
Data Ingestion and Feature Engineering
Incoming data sources can include transactional databases, event streams, and historical logs. You might store this data in a centralized warehouse and feed it into a feature store. Features that rarely change are precomputed in batch jobs. Features that need real-time freshness (prices, availability) are computed from event streams.
Model Training and Deployment
A data scientist would preprocess data, select features, and train a machine learning model. For illustration, a simple linear scoring model might be:
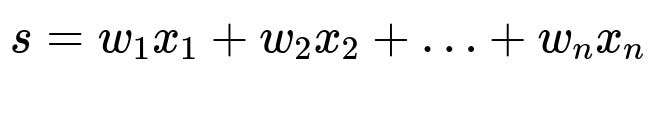
Here s is the predicted relevance score for a candidate item (e.g., a hotel). Each x_i is a feature such as user preference, distance, room price, or historical click-through data. Each w_i is a weight learned from training data. After training, the model is tested offline for accuracy, then deployed.
Serving Architecture
The request flow proceeds from a frontend aggregator to the availability search engine. Worker shards produce candidate sets and call the ranking service. The ranking service queries a distributed cache for static features and a feature store or real-time stream for dynamic features. It then sends requests to the model-serving platform for inference. Results are combined and returned.
The ranking service is deployed on Kubernetes clusters, each with many pods to handle concurrent traffic. There is a fallback to static scores if model inference times out.
Handling Large Payloads
The ranking service might split large payloads into smaller chunks before sending them for inference. This prevents timeouts and manages memory usage. A parallel request strategy helps maintain latency requirements.
Multi-Stage Ranking
A coarse stage might prune items with a simpler model to trim the candidate list. A more sophisticated second-stage model then refines the final ordering. This technique reduces computation while preserving accuracy.
Experimentation
A robust experimentation layer is crucial for continuous model improvement. Interleaving or A/B testing can compare different variants in real time. The ranking service tracks experiment assignments and merges results if needed.
Optimization
Latency is the main bottleneck. Strategies include caching static features, optimizing model inference (quantization, pruning), parallelizing calls, and employing fallback scores if requests exceed time budgets. Monitoring tools and mirrored environments help detect performance regressions.
Code Snippet Example (Python-style Pseudocode)
def rank_candidates(candidate_list, user_context, model, feature_cache):
features = []
for candidate in candidate_list:
static_feats = feature_cache.get_static_features(candidate.id)
dynamic_feats = get_realtime_features(candidate.id)
feats = merge_features(static_feats, dynamic_feats, user_context)
features.append(feats)
# Split into smaller chunks to avoid overload
chunked_features = chunk(features, size=1000)
scores = []
for chunk in chunked_features:
chunk_scores = model.infer(chunk)
scores.extend(chunk_scores)
# Combine candidates with scores and sort
ranked_list = sort_by_scores(candidate_list, scores)
return ranked_list
The example merges slow-changing and real-time features. Then it handles model inference in smaller batches. The final step is sorting by the predicted scores.
What if the search volume suddenly spikes and everything slows down?
The fallback approach handles this. You might serve precomputed static relevance scores. This ensures users still see meaningful results if the real-time path degrades. You would also monitor throughput, queue sizes, and inference latency. Horizontal scaling or parallelization might mitigate resource constraints.
How do you track if your personalization models are truly boosting business metrics?
You would use an A/B test or interleaving strategy. One subset of traffic uses the new model, while a control uses the baseline. You track metrics like click-through rate, booking rate, or revenue. Statistical significance tests reveal if the new model genuinely improves outcomes.
How would you maintain accuracy while optimizing for inference speed?
Quantization might be applied to reduce model size and leverage hardware accelerators. Knowledge distillation could simplify a large teacher model into a smaller student model. Multi-stage ranking can handle a large set with a lighter model first, then refine a smaller subset with a heavier model.
How do you update features for items changing their attributes often?
Real-time or near real-time streams feed new values to the feature store. You configure a low-latency pipeline for such volatile features. This might involve Apache Kafka, Redis, or a specialized streaming solution. The ranking service must retrieve updated values quickly to reflect the current state.
How would you manage experiments that roll back?
You would version each model deployment and keep older versions active in case of quick rollback. Model metadata would track hyperparameters, pipeline stages, and reference data versions. You might rely on feature toggles to revert the application flow to the baseline. Logging and monitoring help detect when a model causes regressions.
This system ensures accurate personalization at scale. It coordinates feature engineering, model serving, caching, and fallback pathways. It handles unpredictable payload sizes, parallelization, and experiments. It merges offline model training with near real-time inference to deliver relevant items for each user query.