
ML Case-study Interview Question: Real-Time Comment Moderation and Ranking with Multi-Task Transformers


Browse all the ML Case-Studies here.
Case-Study question
You are leading a data science team at a growing online platform that hosts user-generated content and comments. Management wants a system to detect policy-violating comments, reduce negative engagement, and rank positive high-quality comments at the top. They want the solution to work in near real time at scale and support multiple languages. How would you design and implement this solution end to end?
Detailed Solution
Start by defining the problem. A comment can be unsafe, spam, or safe based on your community policies. It can also have sentiment (positive, neutral, negative) and quality (low or high). Build a multi-task classification model that predicts these properties. Each classification head outputs a score distribution, and you set decision thresholds for action.
Use a Transformer-based model (such as DistilBERT) fine-tuned for multiple tasks. Concatenate additional contextual features (such as embeddings from the content and commenter) with the final hidden layer. Feed this merged representation into a Multi-Layer Perceptron. Have separate output heads for different tasks. Train them jointly so the model benefits from cross-task signals.
Apply transfer learning. Start from a multilingual DistilBERT to handle multiple languages with minimal labeled data in each language. Capture extra details from context (content embeddings, user profile signals, comment length, etc.). Train on a curated dataset of labeled comments, combining random sampling for safe comments with flagged or reported data for unsafe/spam comments. Use sentiment analyzers or heuristic rules to gather more negative samples when negative data is rare.
Use near-real-time inference. Ingest new comments into a streaming system (for example, using a pipeline with Kafka and Flink). Tokenize text with the DistilBERT tokenizer service. Fetch contextual data from feature stores. Send the features to an online model-serving platform. Return the predicted scores to your pipeline. Send the results to a storage service that your main application can query. Apply enforcement (hide or remove unsafe/spam comments) and ranking (boost high-quality, positive comments) in the user interface.
Use precision and recall metrics to gauge model performance. Calibrate thresholds to reduce false positives on legitimate comments, while blocking the majority of unsafe/spam. Monitor key metrics such as comment report rate and engagement rates. Retrain periodically with fresh data to adapt to new user behavior.
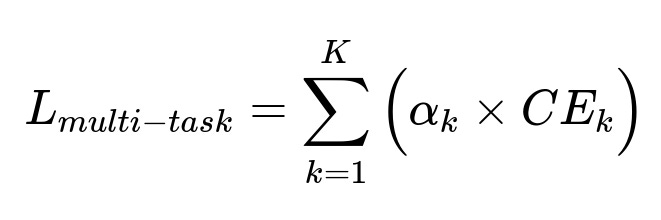
Where:
K is the number of classification tasks (unsafe vs. safe, spam vs. not spam, positive vs. negative sentiment, and so on).
CE_k is the cross-entropy loss for task k.
alpha_k is a weight controlling how much each task influences the overall loss.
Each loss term is the traditional cross-entropy over labeled samples for the respective class. The model learns a shared representation, then separate layers produce final outputs for each task.
Examples and code snippets
Load DistilBERT:
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-multilingual-cased')
base_model = TFDistilBertModel.from_pretrained('distilbert-base-multilingual-cased')
Concatenate context features:
import tensorflow as tf
class MultiTaskModel(tf.keras.Model):
def __init__(self, base_model, hidden_dim):
super(MultiTaskModel, self).__init__()
self.base_model = base_model
self.dense = tf.keras.layers.Dense(hidden_dim, activation='relu')
self.unsafe_head = tf.keras.layers.Dense(1, activation='sigmoid')
self.spam_head = tf.keras.layers.Dense(1, activation='sigmoid')
self.sentiment_head = tf.keras.layers.Dense(3, activation='softmax')
self.quality_head = tf.keras.layers.Dense(2, activation='softmax')
def call(self, inputs):
text_inputs, extra_features = inputs
bert_outputs = self.base_model(text_inputs).last_hidden_state
cls_output = bert_outputs[:, 0, :]
merged = tf.concat([cls_output, extra_features], axis=1)
x = self.dense(merged)
unsafe_out = self.unsafe_head(x)
spam_out = self.spam_head(x)
sentiment_out = self.sentiment_head(x)
quality_out = self.quality_head(x)
return unsafe_out, spam_out, sentiment_out, quality_out
End-to-end reasoning
Train on labeled data containing (comment text, label for unsafe/spam/sentiment/quality, and additional features). During inference, the streaming platform collects the incoming comment and extra features, tokenizes the text, queries the model, and writes the output to a central store. Apply logic for policy enforcement (block or remove if model says unsafe/spam) and comment ranking (sort by sentiment and quality).
Use A/B testing to validate the effectiveness. Track comment report rate, block rate, and user engagement. Retrain and refine thresholds based on real-world feedback. Expand to more languages by leveraging the multilingual backbone.
Possible Follow-up Questions
How would you handle extremely low prevalence of negative or unsafe comments?
Use data sampling strategies to increase representation of those classes. Incorporate active learning where the system surfaces uncertain comments for manual review. Apply class weighting or focal loss so the model focuses more on rare examples.
What if users write comments in code-like text or use obfuscated language?
Use character-level tokenization or subword embeddings. Process user-supplied text transformations or suspicious patterns. Update the model with new examples of obfuscated or coded speech. Consider regex or specialized features to catch disguised profanity/spam.
How do you scale this to very large traffic with minimal latency?
Use an efficient streaming framework (like Flink) with a distributed model-serving platform. Run inference in containers across multiple instances. Use GPU-based serving if needed. Cache repeated queries (if applicable). Optimize the tokenizer and model layers to ensure sub-second processing.
How do you mitigate biased predictions?
Ensure a diverse, representative dataset. Evaluate the model on different cohorts. Add fairness constraints or run fairness metrics in parallel. Adjust sampling or weighting to reduce bias. Conduct regular audits on flagged comments.
How do you manage domain-specific vocabulary?
Collect domain-specific text. Fine-tune the tokenizer or build a custom subword vocabulary if the domain language is specialized. Maintain a dynamic vocabulary or use a sentencepiece approach. Retrain periodically with updated domain data.