
ML Case-study Interview Question: Uplift Modeling for Targeted In-App Messaging on Streaming Platforms.


Browse all the ML Case-Studies here.
Case-Study question
A large streaming platform wants to use Machine Learning to select which users should see certain in-app messages that drive subscription or engagement, while reducing intrusive interruptions. They have random holdout groups that never receive messages, allowing them to measure the average treatment effect. They suspect the effect of in-app messages differs across user segments, so they want to predict the conditional average treatment effect (CATE) of sending these messages. Design a system that uses uplift modeling or related causal inference approaches to decide which users should be eligible for in-app messages, then propose how you would train, evaluate, and deploy this system. Include details on data collection, model architecture, training methodology, feature engineering, offline policy evaluation, and how you would integrate the final model into production.
Proposed solution
The approach uses a causal inference technique known as uplift modeling (also called heterogeneous treatment effect modeling). The random holdout group forms the control. The model learns how the treatment (in-app message) impacts user behavior at the user level.
Key formula for CATE
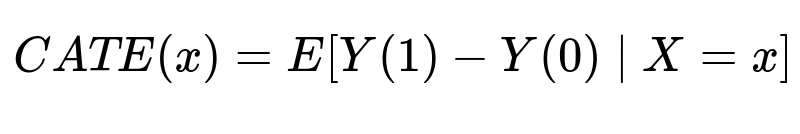
CATE(x) indicates the difference in expected outcome if a user with features x receives a message (treatment = 1) versus not receiving it (treatment = 0). Y(t) is the outcome for a user if assigned treatment t, and X is the feature vector describing that user. The model predicts this difference to identify users who will benefit from messages.
Model architecture
A single neural network can be used with a shared trunk for features, then separate “heads” for treatment and control predictions. For each user, the model outputs two predictions: y0(u) for no message and y1(u) for receiving a message. The difference y1(u) - y0(u) is the predicted uplift. If the uplift is greater than zero, the user is eligible for in-app messaging.
Model training
The network is trained using data where treatment assignment and outcome are known. Each training sample belongs to either treatment or control. Only the relevant prediction head is updated for that sample (treatment or control), along with the shared part of the network. The training objective typically optimizes a regression or classification loss against actual outcomes.
Model outputs for multiple metrics
When multiple business metrics matter, multiple heads can be assigned to each treatment and control, producing multiple predicted outcomes (for example, retention and subscription). The final uplift is a weighted average of each metric’s uplift.
Offline policy evaluation
A contextual bandit framework supports offline evaluation. The holdout data identifies which action was taken (send or not send) and the corresponding outcome. The model’s policy is replayed on the logged data to estimate reward. Compare the policy “send-to-all,” “send-to-none,” and the new uplift-based policy.
Deployment approach
Incoming users first pass through feature engineering modules that aggregate user attributes. The model produces the predicted outcomes for both message treatment and control. The system calculates the uplift. If the uplift is above a threshold, the user enters the messaging channel. This threshold is often tuned using offline validation and partial online A/B tests to maximize gains while limiting disruptions.
What if the platform also wants to optimize a secondary business metric?
A second metric might be short-term conversion. Multi-task learning can incorporate both short-term and long-term outcomes. Each user sample updates the shared trunk and the relevant heads. If the final decision must balance two metrics, a weighted combination of their respective uplift predictions can be applied.
How would you handle data sparsity in the holdout set?
Data augmentation or oversampling from holdout users with different distributions can mitigate sparsity. Feature engineering techniques, such as aggregating user-level historical data over larger periods, helps. The model’s regularization and shared trunk structure reduce overfitting.
Why not just assign in-app messages to everyone if they produce beneficial engagement?
Global average treatment effect might be positive, but some user segments could have negative reactions. Sending everyone messages could hurt retention or satisfaction. Uplift modeling focuses on maximizing positive impact while avoiding segments that respond poorly.
How would you validate this approach in a live environment?
An online A/B test is used to compare the model-based targeting policy with a baseline policy. Key performance indicators are tracked. Guardrail metrics like app usage and churn are monitored to ensure no user segment is negatively impacted.
Could you show a simple Python snippet for training a multiheaded uplift model?
import torch
import torch.nn as nn
import torch.optim as optim
class UpliftNetwork(nn.Module):
def __init__(self, input_dim):
super(UpliftNetwork, self).__init__()
self.shared = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU()
)
self.control_head = nn.Linear(32, 1)
self.treatment_head = nn.Linear(32, 1)
def forward(self, x, treatment=None):
shared_repr = self.shared(x)
control_pred = self.control_head(shared_repr)
treatment_pred = self.treatment_head(shared_repr)
if treatment is not None:
# Return only the relevant head for training
return control_pred if treatment == 0 else treatment_pred
# If no treatment is specified, return both
return control_pred, treatment_pred
model = UpliftNetwork(input_dim=20)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criterion = nn.MSELoss()
for epoch in range(num_epochs):
for features, label, treatment in dataloader:
optimizer.zero_grad()
pred = model(features, treatment)
loss = criterion(pred, label)
loss.backward()
optimizer.step()
Training uses a single pass through the network’s shared layers. The final loss is computed against the relevant head for the actual treatment. At inference, both predictions are obtained to compute uplift.
How do you handle multiple outcomes in the code?
Extend each head to output multiple values. For treatment and control, produce an outcome vector. Each training sample updates the correct outcome vector. The final uplift is the difference in predicted values. A weighting factor can combine multiple metrics when deciding eligibility.
What do you do if ground-truth outcomes change over time?
Periodic retraining is vital. Features may drift, user preferences evolve, and new product offerings appear. Frequent evaluation of the model’s accuracy, and a well-defined pipeline for incremental updates, ensures the model keeps up with shifts in user behavior.