
ML Case-study Interview Question: Abstractive Summarization of Enterprise Chats Using Distilled Transformers


Browse all the ML Case-Studies here.
Case-Study question
A large enterprise faced an overload of chat messages in its internal channels. Individuals often missed critical updates and had to spend significant time skimming through long threads. The enterprise wanted an automated way to generate concise summaries of multi-speaker conversations. They then wanted to display these summaries to users who were returning to a busy chat channel with many unread messages. The solution had to handle various challenges: frequent short messages, many different topics in a single channel, out-of-vocabulary words, and the need to preserve factual accuracy. The enterprise created a new dataset of real-world forum threads, trained a specialized abstractive summarization model, then deployed it in a production chat tool where it ran with strict latency constraints. The system also handled misattribution or misrepresentation errors by detecting and suppressing low-quality summaries. As a Senior Data Scientist, how would you build and deploy an abstractive conversation summarization pipeline under these constraints?
Detailed solution
The problem requires an abstractive text summarization system that can generate short and helpful overviews of multi-user, multi-topic conversations. The approach hinges on a few main components: building a suitable dataset, training a robust model that can handle multiple speakers, dealing with real-time updates, and detecting low-quality output.
The team built an internal dataset called ForumSum to capture real-world conversation styles. It consisted of multi-speaker threads from diverse online forums, filtered and cleaned to ensure safe and high-quality text. This dataset offered enough samples of varied speaking styles, lengths, and topic shifts to train a model that generalizes well to chat conversations. They instructed human annotators to write short and focused summaries of each thread, typically between one and three sentences.
They used a Transformer-based abstractive summarization model called Pegasus, which was pre-trained and then fine-tuned on ForumSum. After fine-tuning, they used knowledge distillation to reduce inference latency. A larger Pegasus model served as the teacher, and a smaller hybrid model (with a Transformer encoder and a Recurrent Neural Network decoder) served as the student. The smaller model produced similar-quality summaries but ran faster and used less memory.
They deployed it in a production environment where each channel’s content was summarized whenever new messages arrived or existing messages were edited or deleted. These summaries were cached, so that when a user opened a channel with unread messages, they saw the summary instantly. They also incorporated triggers that decided when to display a summary, such as checking if the channel was actually large enough or if the user had missed enough messages to justify an automated summary.
They tackled two main types of errors: misattribution (incorrectly assigning actions or statements to the wrong speaker) and misrepresentation (contradicting the actual meaning). They minimized these errors by reformatting data, adding more training samples for chat-like text patterns, and creating heuristics and classifiers to detect low-quality summaries and suppress them before showing them to users.
They used the Transformer model’s attention mechanism to handle different parts of the conversation effectively. A typical single-head scaled dot-product attention is computed by first multiplying a query Q by a key K transposed, then scaling by the dimensionality, then applying a softmax, and finally multiplying by a value V. The core formula for the attention coefficients is often written in pseudo-latex form.
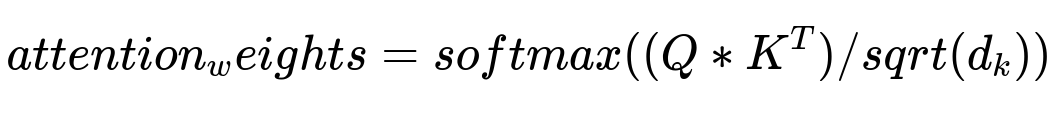
Q, K, and V are linear transformations of the input sequence hidden states, and d_k is the dimension of the key vectors. The model attends to different parts of the input conversation based on relevance. That attention distribution, combined with decoding steps, forms the foundation for how the summarization model extracts relevant information.
They also used knowledge distillation to compress the final system. A common objective for knowledge distillation is to minimize cross-entropy between the student’s predicted distribution and the teacher’s soft label distribution. A simplified text version of cross-entropy for knowledge distillation can be shown as:
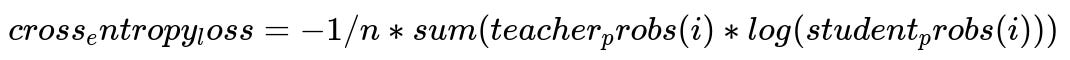
teacher_probs(i) are the teacher model's output probabilities for token i, and student_probs(i) are the student model's probabilities.
Below is a simplified Python snippet that demonstrates how one might structure the training flow using a pseudo-libray:
import torch
import torch.nn as nn
import torch.optim as optim
class TransformerEncoder(nn.Module):
def __init__(self):
super().__init__()
# Define encoder layers
def forward(self, x):
# Encode input sequence
return encoded_x
class RNNDecoder(nn.Module):
def __init__(self):
super().__init__()
# Define RNN-based decoder layers
def forward(self, encoded_x, context):
# Decode to generate summary tokens
return predicted_output
class HybridSummarizer(nn.Module):
def __init__(self):
super().__init__()
self.encoder = TransformerEncoder()
self.decoder = RNNDecoder()
def forward(self, conversation_tokens):
encoded_output = self.encoder(conversation_tokens)
summary = self.decoder(encoded_output, context=None)
return summary
# Suppose we have teacher_model (large Pegasus) and student_model (HybridSummarizer)
teacher_model = ...
student_model = HybridSummarizer()
optimizer = optim.Adam(student_model.parameters(), lr=1e-4)
criterion = nn.CrossEntropyLoss()
for batch in training_data:
conversation_tokens, teacher_logits = batch
student_output = student_model(conversation_tokens)
student_logits = student_output["logits"]
# Distillation loss
loss = criterion(student_logits, teacher_logits.argmax(dim=-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
In a real system, teacher_logits would be soft distributions rather than just argmax labels, but the snippet illustrates the general process. After training, the smaller model is deployed and runs quickly at inference time.
Potential follow-up question: How can we handle user contexts where many topics overlap within a single conversation?
A multi-topic chat often has interleaving threads. A single user might reply to an older message while someone else starts a new sub-topic. One strategy is to segment the conversation into coherent blocks. The system can detect these blocks by analyzing reply structure or time gaps. Another approach is to run a hierarchical summarizer that processes each sub-thread individually and then combines those partial summaries. Handling multi-topic overlap often means the summarization model must identify context shifts, possibly by combining textual signals (keywords or topic embeddings) with structural signals (reply chains). If the conversation is deeply entangled, the model might benefit from referencing key sub-thread IDs or speaker mention patterns. In practice, the summarizer can produce multiple short summaries, each representing a distinct segment or sub-thread, rather than a single monolithic summary.
Potential follow-up question: Why is extractive summarization not as suitable for this scenario?
Extractive summarization simply picks out salient text spans from the conversation. It can sound repetitive or disjointed, and it might omit crucial bridging text or paraphrasing needed to capture the entire context. Multi-speaker chat also has incomplete sentences and user mentions or emojis. An extractive method might pull in fragments that lose clarity without paraphrasing. Abstractive summarization can rephrase and combine messages to form a coherent summary. It can introduce pronouns or references that clarify who did what, which is especially valuable when multiple speakers are discussing multiple topics.
Potential follow-up question: How can we detect misattribution or misrepresentation in the summarized output?
One way is a classification step that scores the summary on factual alignment with the conversation. The system can measure if the summary claims a speaker said something they never actually said, or it can measure semantic alignment by computing embeddings for summary sentences versus the conversation. If the similarity is below a threshold or if it mislabels a speaker, that summary may be flagged as risky. Another step is to force the model to keep track of speaker mentions explicitly. A separate mention-resolution module can detect if the summary is incorrectly attributing an action to a user. A set of heuristics might check for contradictory statements (for instance, the summary says “User A concluded project X,” but the conversation states “User B concluded project X”). If flagged, the summary is discarded or hidden from the user.
Potential follow-up question: Why use a separate teacher-student setup for knowledge distillation instead of training a small model from scratch?
A large teacher model typically learns richer representations and can generalize better. Training a small model directly may not reach the same performance. With distillation, the student model can mimic the teacher’s distribution over tokens, which helps capture the teacher’s nuanced understanding of the conversation. This yields higher performance than if the small model only had ground-truth human summaries as targets. The teacher’s soft probability distribution provides extra guidance for each token, leading to better results given the same model capacity.
Potential follow-up question: How did they manage low latency in production?
They preemptively generated or updated summaries whenever new messages arrived or whenever a message changed. The summarizer then stored those summaries in memory. When a user reopened the channel, the system displayed the cached summary instantly. This avoided on-the-fly inference delays. They also minimized model size using the hybrid encoder-decoder structure so that the summarization step itself was faster. They tuned trigger conditions to decide when summarization was actually worth running (for instance, if only a few short messages arrived, it might skip summarization altogether).
Potential follow-up question: How should we evaluate the quality of conversation summaries?
Automatic metrics like ROUGE or BERTScore provide a first pass, but they can be misleading because multi-speaker threads lack a single “gold” ground truth. Human evaluation is still critical. Humans can judge fluency, factual correctness, and how well the summary captures key points. A dedicated evaluation pipeline may ask multiple reviewers to rate completeness, accuracy, and readability. In production, collecting direct user feedback is also valuable. If users mark a summary as helpful or unhelpful, that can guide iterative improvements in the model.