
ML Case-study Interview Question: Detecting Violating Marketplace Listings with Multimodal Embeddings and Focal Loss


Browse all the ML Case-Studies here.
Case-Study question
A large e-commerce marketplace hosts millions of unique items and sellers worldwide. The marketplace wants to enforce product listing policies at scale to ensure user trust and safety. The team needs a machine learning system to detect potentially violating listings based on text descriptions and product images. They have historical data of past violations (positive examples) and non-violating listings (negative examples). The violation types span several policies. The marketplace wants a robust approach that can generalize to new listings, handle extremely imbalanced data, and integrate smoothly into production with minimal latency. How would you design and implement such a system?
Detailed solution
Data Collection and Labeling
They log and annotate potential policy-violating listings. Positive examples include confirmed violations. Negative examples include listings confirmed as non-violating. Hard negatives mimic the appearance of positives but are not actually violating. Easy negatives come from random non-violating listings. This mixture helps the model learn better boundaries between violating and non-violating classes.
They split data by time to capture shifting trends and behavior. The training set contains older labeled examples, the validation set helps tune hyperparameters, and the test set measures unbiased performance.
Feature Extraction
Each listing has text content (titles, descriptions) and images. They extract text embeddings from a BERT-based encoder, using a lighter variant (ALBERT) to reduce parameters. They extract image embeddings from a CNN architecture like EfficientNet. Text and image vectors then feed into a combined multimodal representation.
Model Architecture
They frame this as a multi-class classification problem, where most listings are in a neutral (no violation) class, plus multiple violation classes. The text encoder outputs a vector, and the image encoder outputs another vector. The system concatenates these vectors to form a single multimodal embedding. A final softmax layer produces probabilities for each class.
They handle class imbalance with focal loss, which places more emphasis on hard misclassified examples.
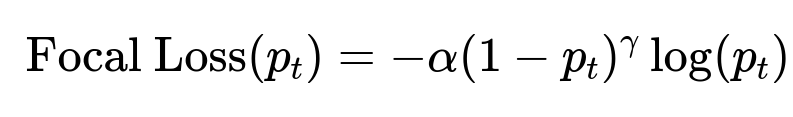
Here, p_t is the model’s estimated probability for the correct class. alpha is a weighting factor for class imbalance. gamma is the focusing parameter that increases the loss for hard-to-classify examples. This approach improves model performance on minority violation classes.
Offline Evaluation
They train offline models and measure precision for correctness of positive predictions and a proxy for recall based on annotated data. Actual recall is hard to measure given millions of daily new listings. They aim to minimize false positives to avoid impacting well-intentioned sellers and maximize correct detections to maintain a safe marketplace. Promising offline models move to production testing.
Production Deployment
They deploy the model as a live service. A canary release sends a small fraction of traffic to the new model. They check metrics and latency. If all is stable, they incrementally shift more traffic. A/B tests compare the new challenger model with the champion model in production. If metrics (precision, coverage) improve and resource usage is acceptable, they promote the challenger to champion.
They periodically retrain with fresh data to maintain performance and cover new violation patterns.
Example Code Snippet
import torch
import torch.nn as nn
import torchvision.models as models
from transformers import AlbertModel
class MultimodalModel(nn.Module):
def __init__(self, text_hidden=768, img_hidden=1280, num_classes=5):
super().__init__()
self.text_encoder = AlbertModel.from_pretrained("albert-base-v2")
self.img_encoder = models.efficientnet_b0(pretrained=True)
self.img_encoder.classifier = nn.Identity()
self.fc_text = nn.Linear(text_hidden, 256)
self.fc_img = nn.Linear(img_hidden, 256)
self.classifier = nn.Linear(512, num_classes)
def forward(self, input_ids, attention_mask, images):
text_features = self.text_encoder(input_ids=input_ids, attention_mask=attention_mask).pooler_output
text_features = self.fc_text(text_features)
img_features = self.img_encoder(images)
img_features = self.fc_img(img_features)
concat = torch.cat((text_features, img_features), dim=1)
logits = self.classifier(concat)
return logits
The text encoder block loads ALBERT. The image encoder uses EfficientNet with a replaced classifier for feature extraction. They produce two vectors. They apply linear layers on each vector, then concatenate them. They send the combined vector to a final linear layer for classification.
They adjust hyperparameters (learning rate, alpha, gamma) using the validation set. They measure loss and watch for overfitting.
Monitoring and Iteration
They track online precision, throughput, resource usage, and user feedback. If performance drifts, they collect new data and retrain. They add new violation classes as the policy scope expands.
Follow-up question 1
How would you address cases where text or images alone might be enough to classify a violation, but the other modality is missing or irrelevant?
Answer Explanation: They can use techniques to gracefully handle missing modalities. One approach is to apply a mechanism that selectively drops one modality and trains with partial inputs. They can set default zero vectors for any missing embeddings. They can also adopt a gating approach that fuses only the available embeddings. The key is to ensure the model can rely solely on text or image if that is all it has.
They might pre-train separate text and image models on large datasets for general representations. If an image is missing, the text encoder still produces a feature vector. The fusion layer or classification layer sees that the image vector is empty or masked. If text is missing, the model depends on the image features. This approach ensures robust performance in production.
Follow-up question 2
Why might focal loss be more effective than standard cross-entropy in this scenario?
Answer Explanation: Class imbalance skews the training process because non-violations dominate. Cross-entropy treats all misclassifications equally. Focal loss focuses training on the harder, more misclassified examples. If the model becomes overconfident in the dominant classes, focal loss amplifies the loss signal from underrepresented violation classes. This improves minority class performance by penalizing mistakes on rare violations more than mistakes on the dominant class.
Follow-up question 3
How would you handle the evolution of new violation categories?
Answer Explanation: They can expand the label space with the new classes. They collect labeled examples for these violations. They retrain or fine-tune the model on combined old and new data. A modular architecture helps to plug in new classes without retraining from scratch. A well-organized data pipeline ensures new categories are regularly annotated. A monitoring system flags novel patterns for manual review to accelerate data collection.
Follow-up question 4
How would you prevent sudden spikes in inference latency when scaling to millions of listings?
Answer Explanation: They can optimize each component. First, they use lighter encoders such as ALBERT for text to reduce compute. They can batch requests on the service side. They can leverage GPUs or specialized hardware. They can also pre-compute embeddings offline if feasible. As traffic grows, they can use autoscaling infrastructure to replicate the service instances. Keeping the model compact with shared parameters or smaller transformer blocks helps maintain predictable response times.
Follow-up question 5
How would you mitigate overfitting with large transformer-based models on a relatively small violation dataset?
Answer Explanation: They can apply regularization techniques like dropout and weight decay. They can freeze some encoder layers and only fine-tune upper layers. They can use data augmentation (synonyms for text, slight image transformations). They can perform early stopping based on validation metrics. They can incorporate more negative data or synthetic examples if needed. Proper hyperparameter tuning and progressive evaluation keep them aware of overfitting risks.