
ML Case-study Interview Question: Constrained Optimization for Personalized Promotion Assignment with Share of Voice Targets.


Browse all the ML Case-Studies here.
Case-Study question
You are given a commerce platform that displays multiple promotional messages to customers on its homepage. Each homepage has several placements where one message can appear. You have a broad set of possible promotional messages, each corresponding to a product category or service. Marketing leaders require specific minimum and maximum Share of Voice (SoV) targets for each category. They also want to ensure each customer sees only one message per placement, and certain messages are not repeated across placements for the same customer. You have machine learning scores indicating each customer's likelihood to respond to each message, plus a measure of how valuable each placement is. Formulate a solution that assigns exactly one message to each placement for each customer, maximizing overall relevance while satisfying SoV targets and business constraints. Propose an end-to-end strategy, including the mathematical formulation, algorithmic approach, and plan for production deployment and real-time assignment.
Detailed solution approach
Problem Definition
This scenario requires maximizing the total relevance of messages shown to customers while adhering to Share of Voice (SoV) targets. SoV targets specify how often (as a percentage of total impressions) certain categories or messages appear. The challenge is to assign messages to multiple homepage placements. Each assignment must observe constraints such as not duplicating a message for the same customer and respecting which messages can appear in which placements.
Mathematical Formulation
Define a binary decision variable X_{i,j,k} indicating whether customer i sees message j in placement k. Let relevance(i,j) be the predicted relevance score of message j for customer i, and let value(k) be a factor representing the importance of placement k.
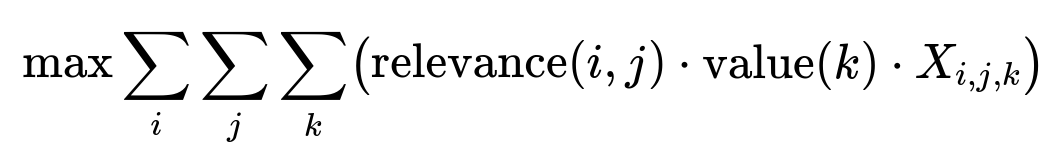
Each variable X_{i,j,k} can be 0 or 1. The objective function adds up the overall relevance across all customers, messages, and placements, weighted by the placement value.
Constraints include:
Each placement must be filled: for every customer i and placement k, exactly one message is assigned. In text form: sum of j over X_{i,j,k} = 1.
A message cannot appear multiple times for the same customer. For each i and j, sum of k over X_{i,j,k} <= 1.
Share of Voice constraints: for each message j, the proportion of total assigned impressions must fall within predefined lower and upper SoV bounds.
Placement applicability constraints: if message j is not allowed in placement k, then X_{i,j,k} = 0.
Model Inputs
A matrix of relevance(i,j) values is produced by product-specific or service-specific propensity models. Each row i is a customer, each column j is a message. A placement value matrix stores the relative worth of each homepage slot. The SoV constraints come from marketing.
Solver and Algorithmic Approach
Using a solver such as Gurobi, define X_{i,j,k} as binary decision variables. Include the SoV constraints as linear inequalities. The solver will then optimize the objective under these constraints. Because the dimension of (customers, messages, placements) can be large, batch customers into smaller groups in parallel. Randomly sample large sets of customers in batches and solve each batch separately. Collect batch outputs into a single final assignment. Store these results in a data repository or caching service.
When a recognized customer arrives, a lookup returns that customer's assigned messages for each placement. If the customer is unknown, show messages based on a random assignment that respects SoV bounds.
Engineering Implementation
Use Python code with Gurobi's Python API. For each batch:
Load the subset of customers and their propensity scores.
Define the decision variables X_{i,j,k}.
Add constraints for SoV, single-message-per-placement, and no message repetition.
Add the objective function.
Call the solver.
Write results to a table for consumption by the homepage service.
Example Python snippet for setting up Gurobi:
import gurobipy as gp
from gurobipy import GRB
m = gp.Model("SoV_Optimization")
X = {}
for i in range(num_customers):
for j in range(num_messages):
for k in range(num_placements):
X[(i,j,k)] = m.addVar(vtype=GRB.BINARY, name=f"X_{i}_{j}_{k}")
# Objective
m.setObjective(
gp.quicksum(
relevance[i][j] * placement_value[k] * X[(i,j,k)]
for i in range(num_customers)
for j in range(num_messages)
for k in range(num_placements)
),
GRB.MAXIMIZE
)
# Constraints (single example shown)
# Each customer i and placement k must have exactly one message
for i in range(num_customers):
for k in range(num_placements):
m.addConstr(
gp.quicksum(X[(i,j,k)] for j in range(num_messages)) == 1
)
m.optimize()
Parallelize this process across multiple machines or in a distributed manner if needed to handle large datasets.
Follow-up question: Handling conflicting SoV bounds
How would you handle a scenario where the lower and upper SoV bounds for a certain message conflict with other messages' SoV bounds, making the solution infeasible?
Detailed Answer
Identify if the sum of lower bounds across all messages exceeds the total available placements or if the sum of upper bounds is less than the total placements to fill. Adjust or relax certain constraints based on business priorities. Another approach is to introduce a small slack variable in the SoV constraints. Penalize the slack in the objective to keep the solution close to feasible SoV requirements while allowing the solver to find a solution.
Follow-up question: Reducing computational complexity
What methods would you use to speed up or approximate the solver if the number of customers is extremely large?
Detailed Answer
Apply batching by randomly sampling subsets of customers. Optimize each subset independently. Merge results into a final assignment table. Use warm starts or partial solutions from previous runs to guide the solver for the next batch. Reduce message categories by grouping similar items under one label. Use heuristics or approximate algorithms like Lagrangian relaxation if an exact solver proves too slow. Cache stable assignments to avoid re-solving for the same customers.
Follow-up question: Ensuring fairness among different product categories
If you need to ensure that new or niche product categories also get enough representation without always losing to popular products, how do you modify your solution?
Detailed Answer
Add constraints or a custom weighting scheme favoring newer categories. Increase their predicted relevance via a prior or offset factor. Set mandatory minimum SoV constraints for these categories. In the optimization function, add higher placement_value multipliers for these categories or create a penalty term if certain categories fall below a threshold. These adjustments push the solver to assign them more impressions.
Follow-up question: Handling real-time or near real-time assignment changes
When you need to update messages dynamically (for instance, a flash sale for a certain product line), how do you adapt the solver approach?
Detailed Answer
Pre-run daily or hourly optimizations and store the solution. For sudden changes, run a smaller incremental solver pass focusing only on impacted messages or subsets of customers, reassigning only those cells. Maintain the existing assignment for unaffected segments. This keeps computations lower while still adapting quickly. If the system requires near-instant updates, switch to a streaming or approximate approach, such as a fast heuristic that respects updated SoV constraints until the next batch solver run.
Follow-up question: Model calibration
How do you address potential errors in the relevance predictions, ensuring the optimization still meets business goals?
Detailed Answer
Periodically evaluate predicted versus actual conversion or engagement metrics. Retrain or recalibrate propensity models. Adjust the solver's objective function weights if certain categories are being over- or under-promoted. Implement an online learning loop to refine model parameters. If some categories perform worse than predicted, reduce their assigned SoV or their relevance scores. Continually monitor Key Performance Indicators like click-through rates and orders to fine-tune.
Follow-up question: Implementation pitfalls
What are common pitfalls you must watch out for in production?
Detailed Answer
Inconsistent data feeds for customer scores lead to incorrect assignments. Overly strict SoV bounds can create infeasible solutions. Missing constraints cause messages to repeat or remain unfilled. Large-scale solver timeouts if batching is not configured efficiently. Inadequate monitoring of the final assignments can mask performance issues. Validation checks after solver output are critical before serving the assignments to users.