
ML Case-study Interview Question: Confidence-Gated Encoder-Decoder for Real-Time On-Device Class-Agnostic Segmentation


Case-Study question
A major technology company needs a real-time on-device model that can segment and lift any prominent subject from a photo regardless of object category. The company wants a method to generate a single-channel mask indicating foreground vs. background pixels, while also using a confidence gating system to ensure the user only sees reliable extractions. How would you design, train, and deploy this model on resource-constrained devices, ensuring high accuracy and low latency?
Provide your step-by-step solution approach, including:
End-to-end architecture details and how it handles different-scale features.
Data sourcing and augmentation for handling arbitrary object classes.
Approaches to preserve tiny details at high resolutions.
Techniques for gating confidence to reduce erroneous results.
Methods to evaluate model quality, including any crowd evaluations.
In-depth Solution
A good approach starts with an encoder-decoder model that processes images at a fixed resolution (for example, 512x512), then upsamples the predicted mask. The encoder extracts features at multiple scales, and the decoder fuses these features to produce a segmentation mask. A separate branch predicts the confidence score used for gating. This gating prevents unlikely foregrounds from being presented.
Architecture
Use a convolutional encoder, such as an EfficientNet v2 variant, trained to compress input images into a rich feature representation. At the terminal layer of the encoder, branch out into:
A channel reweighting mechanism that modulates the decoder features.
A scalar confidence estimator that outputs how likely the image contains a valid subject.
The decoder fuses multi-scale feature maps and upsamples them to produce a single-channel alpha mask. This mask is resized back to the original image dimensions using a content-aware upsampling method. This avoids losing important edges, hair strands, or small object boundaries.
Latency Constraints
Keep the network architecture efficient. Use specialized accelerators such as machine learning–specific hardware or GPU-based kernels to run inference under tight latency budgets. Optimize memory usage and computation by performing in-place operations when possible.
Data Strategy
Synthesize training data by compositing randomly selected foregrounds over diverse backgrounds. Include real-world foreground data covering varied domains. This ensures the model learns general object boundaries rather than memorizing a handful of classes.
Balance the dataset carefully to avoid biases in gender, skin tone, or object type. Inspect misclassifications to discover whether certain subgroups or categories need more representative samples.
Confidence Gating
An extra branch predicts a single scalar confidence. During inference, discard or hide the segmentation result if the confidence is below a certain threshold. This prevents confusing or erroneous masks from showing up.
Detail-Preserving Upsampling
Predict at 512x512 for performance. Then do guided or content-aware upsampling to match the original image resolution (for example, 3024x4032). This preserves fine-grained details like hair or thin edges around a pet or small accessory.
Evaluation
Use mean Intersection-over-Union (IoU) and other standard segmentation metrics. Rely on crowd evaluations to catch subtle errors. Check for fairness and any failure modes (for example, incomplete bounding around curly hair).
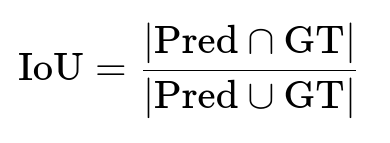
Where Pred is the set of predicted foreground pixels, and GT is the ground truth set of foreground pixels.
Relying solely on IoU may miss user experience nuances, so also conduct manual reviews, user feedback, and structured rating tasks.
Example Python Code Snippet
import torch
import torch.nn as nn
class ConfidenceGatedSegmenter(nn.Module):
def __init__(self, encoder, decoder, gating_head):
super(ConfidenceGatedSegmenter, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.gating_head = gating_head # outputs a single scalar confidence
def forward(self, x):
features = self.encoder(x)
gating_confidence = self.gating_head(features[-1])
segmentation_mask = self.decoder(features)
return segmentation_mask, gating_confidence
# During inference:
# 1. Resize input to 512x512
# 2. Forward pass through model
# 3. If gating_confidence < threshold, discard result
# 4. Else upsample segmentation_mask to full resolution
The encoder might be an EfficientNet v2 variant. The decoder would be a simple multi-scale upsampling branch. The gating_head is a small convolutional or fully connected layer.
Potential Follow-up Questions and Detailed Answers
How would you handle multiple distinct subjects in one photo?
Use connected-component analysis on the predicted mask. Each connected region corresponds to a different subject. Split them into separate masks. If the user wants to select a particular instance, store these individual segments for further tasks, like creating animated stickers.
A practical approach is to binarize the 512x512 mask, find connected pixels, then upsample each connected mask to the original resolution. Use morphological cleaning if needed to remove noise.
How would you ensure fair treatment across demographics?
Continuously review segmentation results over diverse test sets. Include a balanced set of people with different skin tones, ages, or clothing styles. Track performance with crowd evaluations. If any sub-population experiences higher segmentation errors, include more data from that group and retrain. Monitor performance in production logs or manual audits.
What are some hardware optimizations?
Fused kernel calls can accelerate operations like upsampling and matting. Use GPU or specialized neural engines to avoid overhead from CPU-bound loops. Convert your model to a hardware-friendly format (for example, by quantizing weights) to run efficiently on devices with limited memory or compute budgets.
How do you manage unexpected segmentation errors?
Use the confidence gating mechanism. Log misclassifications and near-threshold predictions for post-hoc analysis. Retrain the model with more varied backgrounds or tough examples. Provide an option for manual user correction if feasible.
Why not restrict the model to known object classes?
It would limit the user experience to a predefined set of categories (for example, only people or pets). This approach aims to handle arbitrary objects, so the system is more flexible. It supports unusual items like furniture or collectibles.
How do you measure real-world performance beyond IoU?
Use large-scale user studies with varied images. Ask raters to label the segmentation quality on a scale. Collect metrics such as “average user satisfaction.” Combine these with standard metrics (precision, recall, IoU) and investigate any mismatch. This helps capture fine-grained errors and user-centric issues that simple numeric scores might miss.
How would you integrate your system for live user interaction?
Deploy the model on-device. Trigger it upon user request, such as a touch-and-hold. The system scales the image to 512x512, performs segmentation, checks confidence, and then returns the mask. If confidence is high, upsample the mask and remove the background. If it’s low, display a fallback or no segmentation result.
How do you handle advanced matting for furry edges or transparent materials?
Use a content-aware approach like guided image filtering to refine fine details. The high-resolution upsampling step can incorporate edge guidance from the original RGB image. Evaluate hair edges carefully. Provide separate refinement modules if extremely fine transitions are needed, but keep real-time performance in mind.
These strategies build a robust class-agnostic segmentation system that runs in real time, uses gating for quality control, and works on various hardware platforms.