
ML Case-study Interview Question: Accurate PDF Paragraph Extraction Using Graphs and Random Forest


Browse all the ML Case-Studies here.
Case-Study question
A healthcare enterprise processes thousands of PDF documents with varied layouts. Some PDFs only contain images and require Optical Character Recognition (OCR), while others provide extractable text. The team wants an automated pipeline to convert PDF content into a coherent 1D text sequence, preserving paragraph or column structures. They have found that blindly trusting PDF-encoded layout or using simplistic XY-based segmentations often yields incorrect merges of text blocks. They need a scalable, fine-tunable approach that can handle new client document formats. As a Senior Data Scientist, describe how you would architect a layout detection solution, ensure high accuracy, integrate a supervised model to classify edges between words, and implement threshold-based merging of text blocks. Outline your reasoning, algorithms, data structures, and performance considerations. Suggest how you would continuously improve this system when onboarding new clients with unexpected document formats.
Detailed solution
Data ingestion starts by applying a PDF parser. When the PDF has native text, parse the words and their positions. When the PDF is image-based, use an OCR service to produce text tokens and their bounding boxes. Store these tokens in a 2D grid structure with x, y coordinates, font size, and similar metadata.
Graph construction
Build an undirected graph where each word is a node. Create edges only between words considered potential neighbors. Sort these neighbors along four directions (left, right, above, below) to keep edge creation efficient. This graph captures which words are close enough to belong in the same paragraph.
Random Forest scoring
Train a Random Forest classifier to estimate whether two words should be in the same paragraph. The classifier sees features like relative distance (normalized by font size), alignment, font properties, and partial PDF ordering hints.
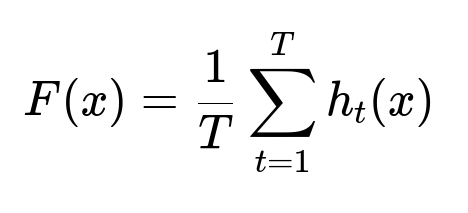
F(x) is the aggregated prediction for words x from T decision trees h_t. Each tree h_t outputs a class (merge or not merge). The final prediction is the majority vote or average. The goal is to learn a consistent boundary between valid merges vs. invalid merges.
Features include plain text distances, difference in font style or size, alignment in the x dimension, and adjacency relations extracted from the PDF’s internal ordering. The model returns a probability. This probability serves as the should_merge score for that edge.
Threshold-based merging
Sort edges by should_merge score. Confident edges (high probability) get merged first. Retain them if they do not create erroneous paragraph structures. Edges below a lower threshold are removed. Mid-range “possible” edges are evaluated in the context of currently merged clusters. When two clusters share consistent alignment or belong in the same column, increase that edge’s score. This dynamic, stateful re-scoring handles uncertain merges.
Integration strategy
Build a pipeline that:
Extracts text tokens with bounding boxes from PDFs or OCR.
Constructs a graph of adjacency.
Scores edges with the trained model.
Merges words into paragraphs based on thresholds and context checks.
Outputs paragraphs in correct reading order.
Maintenance and continuous improvement
Collect new documents regularly. Tag or validate merges. Retrain the Random Forest with added features if new layouts show up frequently. Maintain a staging environment where the updated model is tested on a broad range of PDF formats.
How would you handle an initial dataset with minimal labeling?
Manual annotation is time-consuming. Start with a small, representative sample of documents from various sources. Tag edges as merge or not merge. Generate synthetic examples by slicing or blending documents. Use these to enlarge training data. Pre-label more data with your current model. Then correct predictions and add them as training samples. This semi-supervised approach helps bootstrap a better model without an enormous initial labeled set.
Why rely on a graph-based approach instead of purely rule-based XY cuts?
XY cuts rely on strict splitting along x or y coordinates. Complex layouts with multiple columns, overlapping sections, or varied font sizes can break such heuristics. A graph-based approach captures local neighborhood relationships, ignoring large empty areas. It merges words more flexibly, especially when subtle alignment or spacing differences exist.
How would you handle edge cases where the text is misaligned or overlapping in the PDF?
Store bounding boxes with enough precision to distinguish partial overlaps. Train the model with examples of misaligned text. Add robust features like approximate row alignment or relative spacing. For severe overlap, check PDF metadata or ordering. If these still fail, consider fallback heuristics or manual review flags. In production, push any problematic cases to a queue for further inspection.
How would you embed this solution in a real-time pipeline for thousands of PDFs daily?
Create a microservice for layout detection. Pass PDFs to this service through a message queue. Parse the text tokens. Build and score the graph in memory. Merge paragraphs efficiently in near real-time. Log success or errors. For distributed processing, shard requests across multiple worker instances of this service. Monitor throughput and scale horizontally as needed. Use a caching layer if repeated document structures appear often.
What if the company wants to reduce cost and only OCR selected pages?
Check if the PDF page has extractable text. If it does, skip OCR for that page. For pages that yield no text or have partial text, OCR those pages only. Merge the partial text parse with OCR tokens in the final step. This hybrid approach saves time and reduces costs, because large portions of the PDF might already have extractable text.
How would you evaluate your solution’s correctness?
Create a test set of labeled paragraphs. Compare predicted merges vs. ground truth merges. Use metrics like precision, recall, and F1 to capture how well paragraphs are reconstructed. Precision matters for avoiding incorrect merges. Recall matters for not splitting the same paragraph into multiple blocks. Additionally, do a final check on the string output to see if columns or sections have been intertwined incorrectly.
Here is a code snippet showing a skeletal structure in Python:
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# Suppose we have a dataset of edges: X_features, y_labels
X_features = np.load('training_features.npy')
y_labels = np.load('training_labels.npy')
model = RandomForestClassifier(n_estimators=100, max_depth=10)
model.fit(X_features, y_labels)
def layout_detect(words):
graph = build_graph(words) # custom function to create adjacency
edges = list(graph.edges)
# Compute model scores
edge_features = [extract_edge_features(e, words) for e in edges]
scores = model.predict_proba(edge_features)[:,1]
# Merge logic
edges_sorted = sorted(zip(edges, scores), key=lambda x: x[1], reverse=True)
paragraphs = disjoint_sets(words) # initially each word is its own set
for (u,v), score in edges_sorted:
if score > 0.9:
merge(paragraphs, u, v)
elif 0.5 < score <= 0.9:
if cluster_is_consistent(u, v, paragraphs):
merge(paragraphs, u, v)
else:
pass
return paragraphs
Train carefully with representative data. Update or refine extract_edge_features as new layouts appear. Use test pages to measure how well your merges line up with ground truth.