
ML Case-study Interview Question: Boosting Marketplace Semantic Search with Two-Tower Embedding Models


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing and launching an advanced semantic search system for an online wholesale marketplace that has millions of products and thousands of daily queries. The existing setup relies heavily on keyword-based retrieval, but it struggles with query expansion, synonyms, misspellings, and limited understanding of nuanced queries. Propose a solution that integrates embedding-based retrieval into the current system to overcome these limitations. Explain how you would train a model for this task (including text-only and multimodal scenarios), how you would serve and deploy the model in production, and how you would evaluate its impact.
Proposed solution approach
A semantic search system must understand user queries and product data at a deeper level than keyword matching alone. A two-tower model architecture is useful. One tower encodes queries. The other tower encodes products. Each tower outputs a dense embedding. The model scores relevance by computing the dot product of the query and product embeddings. During training, positive query-product pairs come from user engagement signals such as clicks or add-to-cart actions. Negative sampling is used to differentiate truly relevant products from distractors.
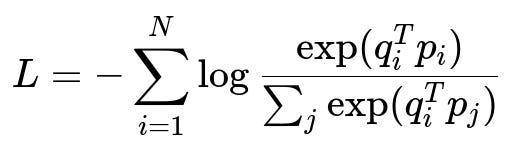
Here, q_i denotes the embedding of the i-th query, and p_i denotes the embedding of the positively paired product. The denominator sums over embeddings of all products in the current batch. The training goal is to maximize the similarity score of correct query-product pairs compared to irrelevant pairs.
Multimodal strategies incorporate both text and product images. A model such as CLIP can align image features with text features in the same embedding space. The query tower still encodes textual queries, while the product tower encodes textual descriptions and image embeddings. Fine-tuning on specific marketplace data improves alignment of domain text and images.
System integration first retains the keyword-based retrieval engine for stable coverage. Embedding-based retrieval provides semantic matches that keyword-based retrieval might miss. The final result merges both retrieval sets. A machine learning ranking layer then uses signals like click-through rates, product attributes, query metadata, and user profiles to generate the final ordering. Re-ranking ensures tasks like diversification and filtering happen before results are displayed.
Implementation can begin with an offline cache-based approach for embeddings to validate potential benefits. Precompute top product embeddings for frequent queries, store them in a key-value store, and blend them with keyword-based results in real time. Once validated through A/B tests, switch to a real-time solution with approximate nearest neighbor (ANN) indexing. Elasticsearch or Faiss can be used for vector indexing. Real-time embedding generation for unseen queries can be served by a model hosted on a managed platform (for example, SageMaker), returning query embeddings for immediate lookup.
Evaluation relies on offline and online metrics. Offline evaluation checks recall@k or similar retrieval metrics. Online A/B tests measure search conversion, clicks, orders, or other business-focused metrics to confirm that semantic search improves user satisfaction and revenue. Monitoring latency remains critical, so hardware resources, batch sizes, and indexing strategies must be tuned to ensure fast response times.
Example Python snippet for real-time inference
import numpy as np
import torch
from transformers import AutoModel, AutoTokenizer
model_name = "sentence-transformers/all-mpnet-base-v2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
model.eval()
def get_query_embedding(query_text):
inputs = tokenizer(query_text, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
last_hidden_state = outputs.last_hidden_state
# Simple mean pooling
embedding = torch.mean(last_hidden_state, dim=1).squeeze()
return embedding.numpy()
sample_query = "comfortable furniture"
query_vector = get_query_embedding(sample_query)
print("Query embedding shape:", query_vector.shape)
This code encodes a given query into a dense vector. The resulting vector is used for nearest neighbor lookups against product embeddings stored in an ANN index.
How do you decide on the model architecture and its size?
Larger transformer encoders often capture better representations. However, bigger models are slower and more expensive. There must be a balance between semantic representation quality and real-time latency constraints. Sampling product data, performing offline evaluations of multiple models, and validating performance using business metrics in smaller-scale tests can guide architecture size. A bigger model may initially run offline for batch precomputation of embeddings to prove value. Once proven, you can optimize or distill the model for faster online inference.
How would you handle edge cases like rare queries or zero-shot scenarios?
You can keep a fallback to the keyword-based engine for edge cases. A newly arrived query might lack prior embeddings if it is exceptionally rare. Real-time inference can encode it on the fly. Zero-shot queries with unique terms are often handled better by large language models pre-trained on diverse text, which can generalize from related phrases. If the query references a brand-new concept, the system might still need fallback strategies such as partial keyword matching and approximate text embeddings.
How do you ensure the system remains scalable as product volume and query volume grow?
Index sharding and vector compression techniques help handle increased scale. Elasticsearch or Faiss can run on clusters that distribute embeddings. Periodically retrain the model on the most recent user interactions to keep the semantic representations fresh. Caching popular queries in memory with a fast-access data store also helps maintain low latency. Real-time feature aggregation and re-ranking may require efficient distributed architecture so no single component becomes a bottleneck.
How do you evaluate the impact of embedding-based retrieval beyond standard ranking metrics?
Deeper business metrics such as order counts, long-term user retention, and cross-category exploration are good indicators of true semantic understanding. Queries often reflect complex preferences, so analyzing user behavior after the first click is helpful. If semantic retrieval surfaces products that users did not discover with strict keyword matching, but eventually purchase, that suggests a strong impact. Qualitative user feedback and error analysis also reveal patterns. If the semantic system frequently returns items that seem off-topic, investigate embedding failures or training data issues.
How might you personalize embeddings for different users?
Personalization can integrate user-specific attributes into the embedding towers or apply user-specific biases in a final re-ranking. One approach is adding a user-embedding vector that shifts the query tower output. Another approach is factoring in user preference signals to re-rank the candidate results. For large-scale marketplaces, graph-based models can connect users and products, allowing user embeddings to propagate relevant interests. Periodic retraining can incorporate new user actions. The privacy implications of storing user signals in embeddings must be addressed, possibly by anonymizing or aggregating user data.
What if the marketplace wants to incorporate advanced filters like country-of-origin or brand constraints?
Real-time retrieval must apply these filters in the approximate nearest neighbor lookups. Elasticsearch 8 can apply filters before vector similarity, eliminating candidates not meeting those constraints. This avoids retrieving irrelevant matches that must be dropped post-hoc, which might otherwise cause an empty set of results after filtering. If the underlying ANN library does not support such prefiltering, a multi-step pipeline or hybrid approach is necessary. For example, first narrow the index using a simpler filter, then apply vector similarity on the reduced candidate set.
Why might you keep keyword-based retrieval in the final pipeline after introducing embeddings?
Keyword-based retrieval is robust for exact matches. It helps with rare product names or official brand names. Users sometimes expect literal matches. Semantic embeddings can miss strictly lexical matches if the training data and model architecture do not emphasize them enough. Keeping both retrieval pathways and blending their results yields broader coverage. Gradually, as the embedding system improves, the ratio of results from the keyword-based engine might decrease. But fully removing the legacy approach might risk losing users who rely on precise keyword searches.