
ML Case-study Interview Question: LLM-Powered Real-Time Scam Detection for Livestream Marketplace Messaging


Browse all the ML Case-Studies here.
Case-Study question
A rapidly expanding livestream marketplace faces growing scam attempts where fraudsters target new or unsuspecting users via private messages. The existing rule engine relies on discrete indicators like shipping delays and refunds but struggles to handle nuanced conversational context. Propose a comprehensive solution that integrates Large Language Models to detect suspicious activity. Outline how you would architect the system for real-time scam detection, incorporate human oversight, and integrate enforcement policies. Specify how you handle data ingestion, model orchestration, LLM-based risk scoring, and automated actions against suspicious accounts.
Detailed Solution
The system maintains a rules-based core and augments it with advanced Large Language Models (LLMs) to detect malicious or manipulative message patterns. The rules engine alone cannot interpret context-rich conversations or subtle user signals, so the approach is to combine both.
Central Rule Engine
It collates structured data like message_frequency, account_age, and lifetime_orders, then applies static thresholds and flags. This engine is quick at enforcing well-defined violations, such as large shipping delays or repeat refund requests, but it lacks contextual awareness for more open-ended issues like off-platform scams.
LLM-Enhanced Detection
Incoming messages or conversations with suspicious signals (for example, large numbers of messages to new accounts) are routed into an LLM-based analyzer. The LLM processes the entire conversation, plus user metadata, to produce scam_likelihood, including an explanation. The system uses the following gating rule inside the engine:
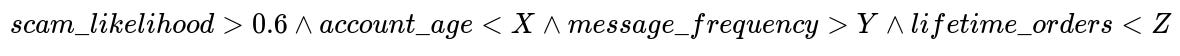
scam_likelihood is the numeric score from the LLM, from 0 to 1. account_age is how many days the account has existed. message_frequency is how quickly the user is sending messages. lifetime_orders is how many orders the user has ever completed. If these conditions are met, the account is flagged for immediate restricted features or suspension.
Data Flow
User data, chat messages, prior violations, and other signals feed a pipeline that checks if a conversation needs LLM evaluation. Once flagged, the entire conversation and relevant metadata are passed to an LLM prompt. The output is structured JSON with fields scam_likelihood and explanation. Those numeric scores feed back into the rule engine, which decides on actions (temporary hold, account suspension, or no action). When confidence is moderate, the system routes the case to the trust and safety team for manual review.
Implementation Details
Use message-based triggers (e.g., user sends large volumes of suspicious text, or newly created account tries to lure others off-platform). Feed those messages to an LLM prompt designed for scam detection. The LLM looks at conversation patterns (mentioning external payment links, repeated urgency, request for private info) that can often bypass naive filters. The outputs are combined with external signals in the rule engine to produce a final decision. Detected violations lead to automated feature revocations (like blocking further messaging), while borderline cases appear in a human moderation dashboard.
Model Behavior and Adaptation
Maintain a feedback loop where newly discovered threats (like messages hidden in image attachments) trigger updates. When malicious actors adapt by embedding text in images, optical character recognition (OCR) extracts textual content, which the LLM then evaluates. Over time, data from user actions (confirmed scams, false flags) refines thresholds or prompts, improving precision and recall.
Performance and Monitoring
Monitor detection metrics: the fraction of actual scams caught (recall) and how many legitimate users are falsely flagged (precision). Investigate flagged conversations frequently to update LLM prompts and refine rule thresholds. The system logs outputs, decisions, and final actions for audits and further model retraining.
How would you handle images containing scam text?
LLMs need textual input, so OCR can convert images to text. The extracted text is appended to the conversation. If the system sees frequent malicious messages embedded in images, it re-checks the conversation in context, calculating scam_likelihood with the newly extracted content. This process remains efficient because images are only analyzed if the message thread is suspicious, optimizing resource usage.
What zero-shot or few-shot techniques can be used with LLM-based classification here?
Use a carefully crafted prompt with concise instructions and examples of flagged scam attempts. If needed, few-shot examples demonstrate typical scam patterns. This approach helps the LLM identify suspicious language without a custom fine-tuned model. Provide short, representative conversation snippets showing recognized fraud attempts, and ask the LLM to map them to a scam_likelihood. For new patterns, the zero-shot component helps adapt with minimal overhead.
How do you measure and optimize precision and recall?
Compare flagged conversations against a manually verified set. If the system flags too many harmless messages, lower the scam_likelihood threshold or refine your conversation-level signals. If the system misses actual scams, integrate more context signals into the LLM prompt or reduce the threshold. Evaluate performance through confusion matrix analysis, focusing on minimizing false positives for genuine users, while maintaining high capture rates of real scams.
How do you handle user privacy in this pipeline?
Mask or tokenize personal data such as emails or card details before sending text to the LLM. Restrict logs to store only hashed user identifiers. Keep data encryption in transit and at rest. The LLM instance (internal or external) must be under strict data governance to avoid accidental leaks of sensitive user information.
How do you mitigate bias or potential overreach?
Regularly audit flagged conversations for false positives. If certain communities or user behaviors are disproportionately flagged, analyze the root cause. Retrain or adjust thresholds. Provide an appeals process for users who believe they were wrongly flagged. Involve human reviewers for ambiguous cases, and refine LLM prompts or instructions to prevent systematic bias.
Which steps ensure robust production deployment?
Monitor concurrency to handle high conversation throughput. Cache repeated prompts or partial inferences for performance gains. Implement fallback logic if the LLM or OCR service is unavailable. Log every step of the pipeline to facilitate debugging. Connect to a workflow system that triggers notifications when large spikes in flagged messages occur. Periodically retrain or adjust the system based on real-world outcomes.
How would you detect user harassment using a similar framework?
Use a specialized harassment_likelihood metric from the same LLM pipeline. Incorporate conversation context and user reports. Possibly define thresholds for toxic language or repeated targeted insults. Feed these signals to the rule engine to decide if immediate user blocking or content removal is warranted. Provide a path for human review when the system is uncertain or the language is ambiguous.
What if the system starts seeing new scam patterns it has never encountered before?
Continue human reviews of suspicious but uncertain cases. Feed newly confirmed patterns into few-shot prompts, updating the “known scam patterns” portion. If patterns diverge widely, consider domain-specific fine-tuning of the base LLM. Track evolving tactics like deepfake content or disguised payment requests, and systematically incorporate them into updated zero-shot or few-shot examples.
What main steps ensure this solution scales effectively?
Leverage streaming architectures (Kafka or similar) for event-driven message ingestion. Keep the rules engine fast by limiting the frequency of LLM calls. Periodically retrain or refine prompts so the LLM’s knowledge stays relevant. Employ microservices for modularization: one service for data gathering and orchestration, one for calling the LLM, and one for final enforcement.