
ML Case-study Interview Question: Predicting Payment Card Declines with Gradient Boosting to Improve Authorization Rates.


Browse all the ML Case-Studies here.
Case-Study question
You have a global payment platform that processes transactions for users who add credit or debit cards to their digital wallets. Card-issuing banks sometimes decline requests. You want to improve the overall authorization rate, reduce declines, and ensure a smoother user experience. Design and implement a machine learning system that predicts which card is likely to be declined, then propose a strategy for how to handle those high-risk requests so valid purchases still go through. Provide details of feature engineering, model selection, evaluation, and how you would integrate the model into production.
Detailed Solution
A tree-based classification model is often suitable for predicting declines. Data scientists typically collect historical transaction details and issuer responses. Cards that have been used frequently, with known acceptance or decline patterns, can serve as training samples. For each card, we collect transaction context like day of the week, time of transaction, card type, card’s past decline ratio, and issuer-specific patterns.
Gradient Boosting Machine (sometimes known as GBM) is popular because it trains shallow decision trees iteratively and improves the model’s residual errors step by step. Hyperparameters like learning rate, number of trees, and tree depth are usually tuned using Grid Search or other optimization approaches. This model helps capture non-linear patterns in issuer behaviors more effectively than simpler linear models.
If the model predicts a likely decline for a specific card, the platform can prompt the user to choose a different payment method, re-verify their identity (for instance by requesting the Card Verification Value), or ask for another step-up authentication. This approach increases the chance of a successful payment and reduces friction by only prompting additional steps when necessary.
Imbalanced data is a common issue. True declines can be as low as 5 percent of all transactions. In such cases, standard area under the Receiver Operating Characteristic curve (ROC AUC) may overestimate model effectiveness. Precision and recall are more reliable.

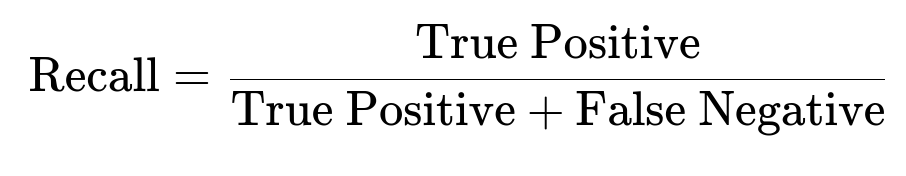
Precision highlights how many flagged declines are actually correct. Recall highlights how many of the true declines are being captured. Monitoring these metrics, along with real-world business metrics (for example additional conversions or acceptance rates), is important in production.
Regular retraining is also necessary. Issuer patterns can shift quickly, so refreshing the model with up-to-date information improves reliability. Live model inference can be done through a low-latency service that calls the model whenever a user initiates a new transaction.
Python example of a basic training flow:
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV
data = pd.read_csv("card_transactions.csv")
X = data.drop("will_decline", axis=1)
y = data["will_decline"]
model = GradientBoostingClassifier()
param_grid = {
"n_estimators": [100, 200],
"learning_rate": [0.01, 0.1],
"max_depth": [3, 5]
}
clf = GridSearchCV(model, param_grid, scoring="precision", cv=5)
clf.fit(X, y)
best_model = clf.best_estimator_
This code trains a Gradient Boosting classifier with a simple Grid Search to find optimal hyperparameters. After deployment, when the platform receives a transaction, it sends the relevant features to this model’s Application Programming Interface (API). The model responds with a probability that the transaction will be declined.
A final step might be to implement logic that routes high-risk requests to an additional flow, such as alternative payment methods or short user verification. This ensures valid purchases are not blocked.
If the model starts performing poorly due to shifting issuer patterns, what would you do?
Frequent data refresh is critical. Model drift happens if issuer rules or user behaviors change. Monitoring the average probability of decline and comparing it to real outcomes helps detect drift. Rapidly retraining the model with fresh data or updating features can restore accuracy. Feature importance tracking also helps identify if certain features lose relevance.
How would you handle highly imbalanced data beyond just using precision-recall metrics?
Downsampling the majority class or oversampling the minority class (for instance, Synthetic Minority Oversampling Technique) helps balance training. Adjusting class weights in the model’s training loss function also shifts the focus toward rare decline cases. Combining these approaches with thorough cross-validation ensures the final model is more robust.
How do you ensure the solution does not cause false positives that reject valid cards?
Setting a suitable decision threshold is critical. The raw output of the classifier can be adjusted so that only high-confidence decline predictions trigger the intervention. Business analysis on the acceptable trade-off between missed declines and unnecessary user prompts is also important. Testing threshold changes in a controlled experiment (often an A/B test) helps confirm the final threshold choice.
How can you provide fallback options if a card is deemed too high risk?
You can surface an alternative payment method that has a track record of success or prompt the user to provide additional validation. Both approaches reduce the chance of losing a purchase entirely. Making these options seamless keeps user satisfaction high while still reducing the risk of decline or fraud.
If system outages occur, can you use this model to minimize disruptions?
When certain issuers or networks have temporary failures, the model can identify good cards with high approval likelihood and auto-approve them in a short timeframe. This avoids blocking loyal customers. The model’s knowledge of historical card patterns helps keep transaction volume steady when external systems have technical issues.
How would you measure the success of the overall system after deployment?
Tracking authorization rate changes is the main gauge. This includes monitoring time periods before and after model deployment. Analyzing the net lift in approved transactions and total revenue helps quantify the impact. Watching user experience signals (for example how often a user is prompted for additional verification) is also vital to keep friction low.
What if a simpler model worked almost as well?
Model interpretability sometimes outweighs marginal performance gains. If a simpler classifier (for example a basic Random Forest) gives comparable results, maintainability and speed may be better. Business context decides which trade-off is acceptable. A smaller, simpler model can also be easier to deploy under strict latency requirements.
If your model processes transactions worldwide, how would you handle region-specific issuer differences?
Regional segmentation or multi-model architecture helps address varying issuer rules. Training separate models for each major region captures unique patterns. If region-specific data is limited, unify the base model but incorporate region-coded features to reflect local behaviors. Continual validation in each region ensures consistent performance.
How do you confirm that your system remains compliant with payment regulations?
Regular audits and secure data handling are necessary. Data encryption, access controls, and compliance with standards like Payment Card Industry Data Security Standard reduce legal or security risks. Working with compliance teams ensures the machine learning pipeline respects user consent and privacy requirements.
How would you maintain transparency for users when a transaction is declined by the model?
Displaying a brief explanation such as “Additional verification needed” or offering them a quick way to update card details increases trust. Exact reasons might be hidden to prevent fraudsters from reverse-engineering the system. Providing general guidance on addressing declines helps maintain good user relationships.
Implementation details for production
An end-to-end system might involve:
A streaming or real-time data pipeline that gathers transaction records.
A feature store that updates each card’s features (recent declines, day-of-week usage, etc.).
A model service that scores each transaction.
A post-processing layer that either attempts a second-chance routing or prompts the user when a high decline probability is found.
A metrics dashboard tracking key performance indicators like overall authorization rate, precision, recall, and user satisfaction metrics.
Frequent retraining and a robust release strategy keep the system performant in fast-changing conditions.