
ML Case-study Interview Question: Generating Niche E-commerce Pages Using BERT for Aspect Sentiment Analysis


Browse all the ML Case-Studies here.
Case-Study question
You are working at an e-commerce furniture retailer that wants to generate specialized product pages for niche customer segments. The catalog has millions of products. Manually curated pages are impossible for the long tail of the catalog. The company wants an automated system that uses aspect based sentiment analysis (ABSA) on customer reviews to identify positive sentiments about relevant aspects of a product. Based on this, they want to surface the most impactful reviews for each product. Propose a complete solution. Include how you would build the model, handle data labeling, evaluate performance, and plan for deployment.
Detailed Solution
Aspect based sentiment analysis focuses on identifying sentiment about specific product aspects in a piece of text. Traditional sentiment analysis only outputs a single sentiment label for the entire text. A fine-grained ABSA model examines multiple aspects in the same text and assigns sentiments to each aspect. This helps surface the most pertinent product attributes that users care about, such as comfort, design, or durability.
Combining Aspect Extraction and Sentiment Analysis
Models often implement ABSA in two steps: aspect extraction, then sentiment classification. A more advanced approach merges these two steps so that identifying relevant aspects and determining their sentiments happen simultaneously. This avoids extracting unimportant aspects. The model ignores aspects that do not carry meaningful sentiment and focuses on those that significantly affect user perception, such as “chair cushion comfort” or “paint finish quality.”
Transformer-Based Architecture (BERT)
A transformer-based architecture with Bidirectional Encoder Representations from Transformers (BERT) is effective. BERT learns contextual embeddings from large corpora. Then, additional layers learn to predict aspect boundaries and their sentiment. The model sees entire sentences simultaneously, capturing how context changes the meaning of words. This results in more accurate aspect identification and sentiment labeling.
Labeling Challenges
Defining precise rules for labeling aspects is tricky. People may disagree on whether certain terms constitute aspects or whether they have real significance for the user. Clear labeling guidelines are vital so the model can consistently learn which aspects to focus on. Labelers need instructions on:
Which noun phrases qualify as relevant aspects.
How to mark negations accurately (for instance, “don’t like the assembly process” is negative).
When to ignore trivial aspects (like “legs” if the user does not express a strong opinion about them).
Performance Evaluation
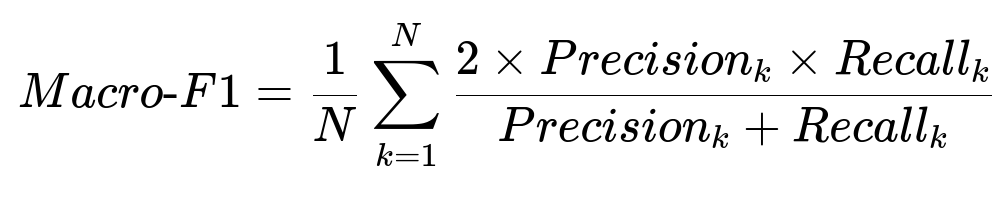
Macro-F1 measures performance across multiple classes or aspects. N is the number of classes (or aspects) in the model’s output. Precision_k and Recall_k are the precision and recall for aspect k. This metric balances how well the model identifies each aspect (recall) with how accurately it labels each aspect (precision).
Achieving a high macro-F1 means the model is not only good at picking common aspects but also handles less frequent ones correctly. The model’s training might require hyperparameter tuning, larger labeled datasets, or more advanced architectures until the macro-F1 is sufficiently high.
Deployment Considerations
A stable production workflow might:
Collect new product reviews in real time.
Run them through the ABSA pipeline to extract aspects and sentiments.
Update niche pages that highlight products with strongly positive sentiments around those aspects.
Allow advanced filters, such as “chairs easy to assemble,” by using the extracted aspect-sentiment data.
Possible Implementation Outline in Python
from transformers import BertTokenizer, BertForTokenClassification
import torch
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
model = BertForTokenClassification.from_pretrained("bert-base-uncased", num_labels=num_aspects)
sentence = "I love the comfort of this chair but the assembly was difficult"
inputs = tokenizer(sentence, return_tensors="pt")
outputs = model(**inputs)
# Next step: Convert logits to aspect-sentiment labels
# Then refine model to handle both extraction and sentiment classification simultaneously
The model could be a multitask network where one head extracts aspects, and another predicts sentiment for each extracted aspect. Training requires a well-labeled dataset specifying aspect spans plus associated sentiments.
What follow-up questions might the interviewer ask?
How would you handle insufficient labeled data for training the ABSA model?
In many cases, aspect-based data is scarce. One solution is transfer learning. Start with a pretrained transformer like BERT. Fine-tune it using a small labeled set of reviews, possibly applying data augmentation. Synthetic data approaches might create new review snippets by paraphrasing or merging short text segments. Active learning can also help. You identify data points with high model uncertainty and label them first to boost model performance more efficiently.
Would you separate domain-specific aspects from general aspects?
Yes. Domain-specific aspects (for example, “mattress firmness,” “futon thickness”) require more specialized tokens and definitions. General aspects (such as “delivery speed,” “price”) are common across domains. A layered approach might keep a general aspect dictionary in one component and domain-specific expansions in another. BERT’s contextual embeddings help unify both, but you might maintain two distinct sets of aspect labels to avoid confusion.
What if the model overfits to common aspects and misses rare ones?
This happens when the dataset skews toward frequent aspects. Possible solutions:
Class weighting or focal loss to emphasize minority aspects more.
Balancing the training data. Oversampling or more targeted data collection for rarer aspects helps the model see enough examples to learn.
Periodic manual review of performance on rare aspects to detect drift or class imbalance.
How do you justify combining aspect extraction and sentiment detection in one model?
A single-step approach ties sentiment importance to the presence of an aspect. Some aspects only matter if sentiment is strong (positive or negative). Simultaneous modeling of extraction and sentiment can filter out trivial mentions. It reduces error propagation from one stage to the next. It also reduces duplication in the architecture, enabling the model to learn the correlation between aspect boundaries and sentiment cues more directly.
How would you handle ambiguous sentiments in a single sentence?
Ambiguous language or conflicting sentiments about the same aspect appear in real data. The model might assign a neutral or mixed sentiment label. Fine-tuning can include special tags for “mixed” if consistent labeling is available. If a single sentence expresses both love and frustration for one aspect, additional context or a multi-label approach can be tried. Labelers should have clear guidelines for these edge cases to ensure consistent training data.
Could this system support facet-based filtering for users?
Yes. The aspects can be indexed in a search engine. When a user selects a filter like “sturdy legs,” the system finds items with reviews expressing positive sentiment about “sturdiness” or “legs.” This can be integrated into a product discovery pipeline so that the user sees customized results that match the aspect preferences they care about most.
How do you maintain model performance over time?
Periodic retraining is required. Product designs, customer slang, and popular preferences shift. A pipeline may track:
New reviews with aspects or sentiments the model fails to capture.
Performance on a validation set over time.
Ongoing data labeling to handle new product categories or new language usage. When performance drops below a threshold, retrain or fine-tune on fresh data so the model stays accurate.
Why is macro-F1 more insightful than simple accuracy?
Simple accuracy might be dominated by the most frequent aspects or sentiment classes. A model could ignore rarer aspects and still get high accuracy by focusing on the major classes. Macro-F1 treats each class equally, averaging F1 scores across classes. This reveals if the model performs poorly on less frequent but important aspects. A balanced macro-F1 score indicates a more robust model.
When would you try a different architecture?
A different architecture might be necessary if:
You see plateauing performance with BERT-based models.
The text includes more complex, domain-specific grammar or specialized vocabulary that a domain-specific model could handle better.
Latency constraints demand a more lightweight architecture. If real-time responsiveness is essential, smaller or distillation-based models might be required to reduce inference time.
How do you handle real-time inference at scale?
Large models can be expensive to run. One approach is model distillation. You train a smaller network to mimic the larger BERT-based model. This smaller network is faster in production. A caching mechanism might store frequent inferences so repeated review texts do not require reprocessing. Horizontal scaling with container orchestration frameworks (Kubernetes or similar) can also maintain throughput under heavy workloads.
How would you improve labeling quality?
Revising instructions to be unambiguous is crucial. Conduct frequent inter-annotator agreement checks to see if multiple labelers assign the same labels. Provide example-based guidelines showing correct vs. incorrect aspect identification. Offer real-time feedback to labelers. Simplify labeling tasks if possible. Sometimes you can combine partial automation (like a preliminary model pass) with final human review. This ensures consistency and reduces labeler workload.
How do you mitigate bias in sentiment analysis?
Bias can arise if the training data overrepresents certain groups or viewpoint patterns. You might:
Use diverse data from various demographics and product segments.
Check for systematic skew in predicted sentiments for different subpopulations or product categories.
Regularly audit model outputs to ensure fairness and accuracy for all relevant segments.
What if a user wants domain adaptation for a new product category?
When you expand into a new product line, many aspects will differ. Revisit labeling guidelines to capture category-specific terms. Gather some labeled data from those new products. Fine-tune the model on that new dataset while preserving knowledge from earlier categories. If aspects overlap, the model can transfer that knowledge, but new aspects might need additional training epochs to converge.
How would you incorporate continuous feedback from users?
A feedback mechanism can let users flag inaccurate or irrelevant aspect mentions. This feedback can be integrated into a retraining loop. The model might weight flagged reviews more heavily during fine-tuning. Over time, this user-driven approach tailors the system to real-world usage patterns. It also helps the model adapt to changing slang or evolving product lines.
Would you consider other architectures beyond BERT?
Yes. You could try GPT-based or T5-based architectures for ABSA. Some approaches embed entire sentences and use a separate classification head for aspect extraction. Others do sequence-to-sequence transformations. BERT-based models remain popular due to broad tooling support and strong performance, but new architectures may outperform it on domain-specific data or offer faster inference.
How do you maintain interpretability?
Some interpretability tools can visualize attention weights in transformer layers. If you see that the model focuses on the phrase “table legs” when classifying sentiment about sturdiness, it helps confirm correctness. You can also highlight relevant words or phrases in user-facing review snippets. This fosters trust and allows internal teams to verify the model’s predictions align with actual sentiment.
How would you extend ABSA to multilingual reviews?
Collect labeled data in each target language or use cross-lingual models pretrained on multiple languages. If domain aspects are consistent, you might adopt zero-shot transfer from high-resource languages to lower-resource ones. Data augmentation or machine translation can help if direct multilingual labeled data is limited. Continual learning can keep the model updated for new languages or regional dialects.
How would you summarize the main takeaways for implementing ABSA in production?
Focus on refining data labeling guidelines, leveraging strong pretrained models like BERT, merging aspect extraction with sentiment classification, and continually monitoring performance with a robust metric like macro-F1. Keep the model updated with fresh data, involve feedback loops, and use advanced deployment strategies for efficiency and scalability.