
ML Case-study Interview Question: Discovering Support Ticket Themes with BERT Embeddings and HDBSCAN Clustering.


Browse all the ML Case-Studies here.
Case-Study question
A global tech provider has thousands of customer support tickets every month. They want to identify common themes and high-impact issues from those tickets. Their aim is to reduce support costs, improve the product based on user feedback, and track emerging issues. They need a scalable topic modeling system that groups similar tickets, flags the most pressing issues, and provides a way to measure the effect of product improvements over time. Design a complete solution explaining how you would approach the data pipeline, model selection, model evaluation, and final deployment.
Proposed Solution
Organizations often struggle with varied wording by users describing similar issues. Traditional bag-of-words approaches may fail to catch subtle differences. Latent Dirichlet Allocation (LDA) or transfer-based language models can help. Also, domain knowledge is crucial to ensure the model focuses on the relevant text segments.
Short textual fields in support tickets often include repeated clutter (metadata, boilerplate). Removing these uninformative elements before modeling is vital.
LDA Approach
With LDA, each document belongs to a latent topic distribution, and each topic is represented by its most frequent terms. Text preprocessing involves removing irrelevant artifacts, lemmatizing words, and tokenizing. LDA performance hinges on hyperparameter tuning for the number of topics k, as well as cleaning steps that ensure coherent topics.
Output typically includes top keywords for each topic, document-to-topic distributions, and monthly trends. This helps stakeholders see which issues recur often and the evolution of those issues over time.
Transformer-Based Approach with Clustering
Transfer-based models such as BERT encode text into high-dimensional vectors. Reducing these embeddings with a technique like Uniform Manifold Approximation and Projection (UMAP) preserves local structure and accelerates clustering.
HDBSCAN finds dense clusters without forcing every ticket into a cluster, labeling outliers as noise. Minimizing cluster size helps avoid merging unrelated tickets. After grouping tickets, class-based TF-IDF (c-TF-IDF) provides interpretable keywords for each cluster.
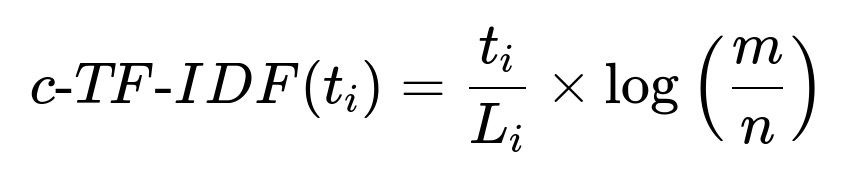
t_{i} is the frequency of a word t in class i.
L_{i} is the total number of words in class i.
m is the total number of unjoined documents.
n is the overall frequency of word t across all classes.
This formula creates a consolidated representation for each cluster to derive the top words that characterize it.
Implementation Example (Python)
import umap.umap_ as umap
import hdbscan
from transformers import AutoTokenizer, AutoModel
import torch
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
model = AutoModel.from_pretrained("distilbert-base-uncased")
def encode_texts(texts):
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
embeddings = outputs.last_hidden_state[:,0,:]
return embeddings.numpy()
cleaned_texts = [...] # Preprocessed ticket descriptions
embeddings = encode_texts(cleaned_texts)
reducer = umap.UMAP(n_neighbors=15, n_components=5, metric='cosine')
umap_embeddings = reducer.fit_transform(embeddings)
clusterer = hdbscan.HDBSCAN(min_cluster_size=15, metric='euclidean')
labels = clusterer.fit_predict(umap_embeddings)
All clustering and topic summaries feed into a reporting system. Stakeholders see which clusters have the most tickets. Actions can be taken, and subsequent ticket distributions are tracked to see if those improvements reduced user pain points.
How to Handle Follow-up Questions
1) How do you choose the number of LDA topics?
Start with measures like coherence and perplexity. Plot them across different k values using the elbow method. Validate output with domain experts to ensure semantic meaning in each topic.
2) How can you measure performance beyond coherence scores?
Assess real-world impacts. After implementing fixes suggested by the modeling, monitor metrics like reduced ticket volumes in targeted clusters, faster issue resolution, or improved user satisfaction scores.
3) Why might BERT embeddings outperform TF-IDF?
BERT captures semantic relationships between words. TF-IDF is strictly frequency-based. BERT recognizes that “learn Azure” and “get more familiar with Azure” share the same intent, while TF-IDF may not.
4) How do you deal with noisy or outlier texts?
HDBSCAN marks outliers. Those can be reviewed manually or placed in a separate process. For LDA, you might drop short or low-information tickets. Data cleaning also mitigates the impact of random user inputs.
5) How do you incorporate domain knowledge?
Strip irrelevant text like boilerplate disclaimers. Add domain-specific dictionaries to handle synonyms or product names. Work closely with product teams to tune the text preprocessing. This ensures that the final topic representations match the product’s terminology.
6) How would you evaluate results if different teams have different needs?
Set up separate pipelines or custom filtering. You can apply specialized domain dictionaries or custom embeddings for each team. You can measure success by how well each team can use the topics to reduce support overhead.
7) How do you keep the model updated as new issues appear?
Retrain on incremental data or adopt online learning techniques if feasible. Monitor changes in topic distributions. If new issues remain unclustered or grouped incorrectly, refine the model or retrain with new labeled data.