
ML Case-study Interview Question: AI-Personalized Language Learning: Adaptive Paths using Spaced Repetition & Text Classification.


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing a language learning app that uses AI to personalize user learning paths. The goal is to improve user engagement, language mastery, and course content quality. Your system must handle:
Tracking individual user proficiency at the level of words, grammar concepts, and sentence structures.
Personalizing lesson content based on predicted mastery levels.
Guiding users on optimal practice schedules so they do not forget critical vocabulary or concepts.
Adapting notifications to each user’s behavior patterns.
Automating the identification and resolution of course content errors based on user feedback.
Classifying textual materials into different difficulty levels so that learners can consume materials appropriate to their stage.
Propose a high-level solution that solves these requirements. Outline the data you would collect, the models or algorithms you would use, and how you would integrate these components into a seamless user experience at scale. Also explain how you would measure learning outcomes to refine the system further.
Proposed detailed solution
Overview
This solution relies on personalized AI modules that observe every user interaction. Each module addresses a distinct challenge like spaced repetition, dynamic lesson generation, grammar error attribution, user feedback triaging, and text difficulty classification. The entire platform requires detailed user data logs, robust modeling pipelines, and well-structured code to ensure efficient experimentation and maintenance.
Spaced repetition
The system must maintain a dynamic profile for each user. It tracks vocabulary words, grammar constructs, sentence structures, and how often the user practices each. It also predicts how likely the user is to recall a concept at any given time.
A spaced repetition scheduler returns items to the user right before the model predicts they will forget them. It uses user logs of successes and failures and updates probabilities for each word or concept. This ensures that each practice session is highly relevant.
Custom lesson generation
The platform creates a lesson for each user by assembling a set of challenges or questions. A personalization model ranks potential exercises by how beneficial they will be for that user at that moment. Challenges that target known weaknesses appear more often. The system also balances difficulty so users are neither bored with repetition nor overwhelmed by complex tasks.
An internal engine, often called a session generator, interacts with a machine learning service that estimates the probability each user will answer a given challenge correctly. If the user is answering everything correctly, the system can inject more challenging items. If the user is getting many wrong, the system can simplify the lesson in real time.
Error attribution (“Blame”)
When the user makes a mistake, the platform tries to attribute that mistake to specific underlying knowledge gaps. For instance, if the user typed the correct words but placed adjectives in the wrong position, the system infers grammar structure problems rather than vocabulary gaps. This is done by comparing the user’s response (including incorrect parts) to the known correct sentence. The system assigns “blame” to the relevant concept (past tense conjugation, pronoun mismatch, gender agreement, etc.). This data updates the user’s profile for that concept, improving future recommendations.
Active learning for grammar tips
A pipeline compares correct vs. incorrect user responses and identifies error patterns that occur frequently. If a rule-based module can match the user’s mistake to a known pattern, the system immediately offers a short grammar tip. This tip clarifies what went wrong and how to fix it. Over time, the platform’s active learning approach proposes new rules to human linguists for confirmation, thus constantly expanding the grammar tips library.
Adaptive notifications with a bandit approach
A multi-armed bandit algorithm optimizes user notification timing and text. It initially defaults to sending notifications when the user historically completes lessons, then iteratively refines those estimates to find the best time. It also experiments with different reminder text to see which variant yields higher re-engagement. The algorithm quickly learns user-specific behaviors and converges on patterns that maximize daily lesson completion rates.
Triaging user reports with logistic regression
When users think the platform incorrectly marked an answer wrong, they can file a report. Many user reports are invalid, but some reveal legitimate course content errors or missing accepted answers. A logistic regression model ranks these reports by likelihood of being valid. Language experts review top-ranked reports first. This accelerates fix cycles and improves course quality fast.
Here is a standard logistic regression model for predicting the probability p that a user report is valid:
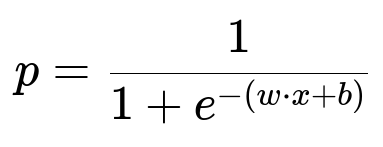
Where x represents the vector of features for the user’s report (submitted answer, context, frequency of the issue, etc.), w is the parameter vector learned from data, b is the bias term, and p is the predicted probability that a report will be accepted.
Text difficulty classification (CEFR-like tool)
A text classifier gauges how difficult each piece of text will be for a given user level. It assigns standard difficulty labels like A1 (beginner) to C2 (advanced). The pipeline trains on known labeled examples of text from multiple proficiency levels. It then generalizes to classify arbitrary text based on learned word embeddings and transfer learning across multiple languages.
Developers use this classifier when creating new reading comprehension stories or podcast transcripts. They ensure each item’s difficulty matches the desired level. If the text is too hard, the system suggests revisions. This consistency safeguards an appropriate progression curve for users.
Measuring outcomes
The platform monitors:
Retention rates (how consistently users return to practice).
Actual language proficiency gains (standardized mini-tests inside the app).
Time-to-mastery (how quickly a user can progress through key modules).
User feedback volume and acceptance rates.
Continuously analyzing these metrics highlights bottlenecks in certain language concepts or text difficulty mismatches. The system re-tunes spacing intervals, bandit parameters, and recommended lesson paths. These tight feedback loops drive iterative improvement.
Example code snippet explanation
Below is a simple Python demonstration of how you might train a logistic regression model to triage user reports. This snippet uses a generic scikit-learn approach.
import numpy as np
from sklearn.linear_model import LogisticRegression
# Example feature vectors for 1M user reports (just placeholders here)
X = np.random.rand(1000000, 10) # 10-dimensional features
y = np.random.randint(2, size=1000000) # 0 or 1 indicating invalid vs valid
model = LogisticRegression()
model.fit(X, y)
# Predict probabilities for new reports
new_reports = np.random.rand(10, 10) # 10 new reports
prob_valid = model.predict_proba(new_reports)[:, 1]
print(prob_valid)
The code trains a model on synthetic data. In production, the system would feed real labeled data into this pipeline, with features representing the textual difference between the user’s answer and correct answers, frequency of a specific mistake, and so on. After training, the model’s top probabilities can be routed for immediate human inspection.
Further follow-up questions
1) How would you implement real-time personalization at scale?
High throughput is essential. The system must deliver lesson content with no noticeable latency. Store user state in a fast, low-latency database. Cache some frequently used exercises. Keep the model endpoints warm with a microservice architecture. For personalization in real time, your session generator queries the machine learning service, which uses fresh parameters updated daily or weekly. Stream-based updates ensure that as soon as there is enough new data, it triggers an offline retraining job or a mini-batch training approach. Real-time inference happens with minimal overhead thanks to optimized frameworks (e.g., TensorFlow Serving, TorchServe, or scikit-learn joblib).
2) How do you handle unstructured user responses?
Store user responses in a structured schema containing user ID, timestamps, lesson ID, exercises, and transcribed or typed answers. Use an NLP pipeline to parse these answers. Tag them for part-of-speech, grammar structure, or text similarity checks. Convert them into concept-level tokens for your error attribution system. Rely on partial matching or advanced string matching to map incorrect responses to likely intended correct answers. Maintain a large database of synonyms or accepted answer variations. Over time, crowdsource new synonyms from repeated user attempts.
3) How would you evaluate user language mastery beyond multiple-choice questions?
Use free-form text tasks, reading passages, and short answer tasks. For reading tasks, see if the user can correctly rephrase main ideas. For short answers, grade correctness using an NLP-based grammatical error detection engine. The system can match user responses against a semantic representation of the target. Another method is to embed user answers and reference answers into the same vector space and compare their distance. Supplement with structured fill-in-the-blank tasks or short speaking tasks if speech recognition is integrated. Show mastery by analyzing improvements in the user’s ability to handle open-ended queries.
4) How do you choose hyperparameters for spaced repetition?
The system must estimate forgetting curves for each user. Start with general intervals for items: immediate practice, 1 day, 3 days, 1 week, 2 weeks, and so on. As the system logs success or failure, it adjusts intervals on a per-item basis. A method is to learn a function that maps last interaction time and item difficulty to a recall probability. A typical baseline is the standard exponential decay formula. A Bayesian approach can incorporate user-specific parameters. Validate hyperparameters via A/B tests: one group sees intervals generated by a certain function, another sees intervals by a slightly changed approach. Compare test groups on retention metrics and short quizzes for final decisions.
5) How do you ensure that text classification remains accurate for multiple languages?
Train a multilingual model with a shared embedding space or with strong cross-lingual transfer. Start with a large base language that has abundant labeled data (e.g., English). Expand to smaller data languages by transferring the learned embeddings and fine-tuning on labeled examples from the target language. Confirm the assigned difficulty with staff who speak those languages. If you see systematic errors, correct them, then retrain. Periodically check the classifier with real user data or reading comprehension scores to confirm alignment with the correct difficulty levels.
6) Could you integrate voice input or speech recognition?
Yes. Transcribe user audio with a speech-to-text service. Pair the transcribed text with the tasks already in the system for grammar checks. This also helps measure speaking proficiency. The challenge is handling accent variations. A robust acoustic model is crucial. For feedback, you can highlight spoken errors or mispronunciations. Extend the spaced repetition logic to track user speaking proficiency levels in tandem with reading and writing levels.
7) What if your logistic regression approach mislabels many valid user reports?
Retrain often. Gather more examples of correct vs. incorrect reports. Refine features to capture differences in spelling, synonyms, or phrasing. Introduce a human-in-the-loop approach, where the system quickly flags borderline cases for staff to review. Once staff correct or accept them, feed this data back into training. Consider advanced models (like gradient boosting) if you notice logistic regression is plateauing. But logistic regression often works well if your features are well-crafted.
8) How do you measure success for this entire system?
Look at user engagement (daily or weekly active users), lesson completion, dropout rates, performance on optional quizzes, and aggregated accuracy on new items. Track how many users move from beginner to intermediate in a short time. Watch for user feedback on notifications (mute rates or time to open). Monitor average correctness over time. Also measure subjective feedback from user satisfaction surveys. If learning outcomes and user satisfaction both rise, and churn decreases, the system is working well.