
ML Case-study Interview Question: Predicting & Reducing Churn with a Real-Time Gradient Boosting Pipeline


Browse all the ML Case-Studies here.
Case-Study question
A major online platform noticed significant customer churn. They collected extensive user-activity data from web logs, apps, and transaction records. They want a solution that predicts and reduces churn by implementing a machine learning pipeline, real-time scoring, and customized interventions for at-risk users. How would you design, build, and deploy this solution end-to-end?
Proposed Solution
Combining user activity signals with demographic and transactional data helps a predictive model learn churn patterns. Building a pipeline that captures new data continuously keeps your model updated and aligned with user behavior shifts. Splitting the solution into data ingestion, feature engineering, model training, validation, deployment, and performance monitoring ensures modularity.
Short overview of the pipeline:
Data ingestion: Raw data arrives from web logs, mobile apps, and user transactions. An extract-transform-load (ETL) job stores the data in a distributed storage system.
Feature engineering: Session counts, average usage time, recency of last login, purchase frequency, and total spend. Creating aggregated features helps the model capture user behavioral dynamics. Handling missing data, categorical encoding, and normalization or standardization of features fosters consistent model input.
Model architecture: Many teams use supervised learning with gradient boosting or logistic regression. Logistic regression provides interpretability and faster training, while gradient boosting often yields higher accuracy at scale. Including hyperparameter tuning avoids overfitting.
Training and validation: One approach splits data into training and validation sets to confirm generalization. K-fold cross-validation ensures robust performance estimation.
Deployment: A real-time prediction service classifies incoming user data. Observed churn outcomes feed into periodic model retraining to address data drift.
Monitoring: Tracking key metrics like AUC (Area Under Curve), recall, precision, coverage on fresh data. Alerting triggers if performance falls below thresholds, prompting investigation or model refresh.
Code snippet for training a basic gradient boosting model in Python:
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
data = pd.read_csv("user_activity.csv")
X = data.drop(["churn_label"], axis=1)
y = data["churn_label"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=5)
model.fit(X_train, y_train)
print("Training Accuracy:", model.score(X_train, y_train))
print("Test Accuracy:", model.score(X_test, y_test))
Explaining a core logistic regression formula:
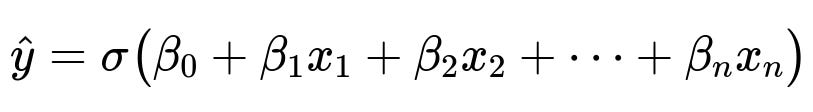
The variables in the sum are the input features x1, x2, ..., xn. The coefficients beta1, beta2, ..., betan measure each feature’s contribution to churn risk. The bias beta0 is the intercept term. The function sigma() is the sigmoid operation that converts the linear combination to a probability between 0 and 1.
Explanation Details
Collecting data at scale: Setting up batch and streaming ingestion so the model sees both historical trends and real-time signals. Ensuring data quality with a pipeline that cleans data and infers missing fields. Storing final data in a distributed file system or data warehouse.
Feature store usage: Maintaining a repository of features, ensuring consistent definitions across training and scoring processes. Minimizing data leakage by applying the same transformations to historical and live data. Documenting feature schemas for future reuse.
Model training: Tuning hyperparameters for gradient boosting. Adjusting the number of boosting stages, learning rate, maximum tree depth, and minimum samples per leaf. Balancing interpretability versus performance by occasionally examining logistic regression as a benchmark. Checking training logs for early stopping to prevent overfitting.
Deployment considerations: Containerizing the final model and hosting it behind a prediction API. Using a message queue for asynchronous scoring if needed. Logging predictions and actual churn outcomes for later analysis. Scheduling retraining jobs to combat data drift.
Monitoring: Tracking data drift by comparing statistical distributions of new data with training data. Noting changes in domain behavior. If drift is high, retraining the model with updated data. Using performance dashboards with charts for daily or weekly AUC, accuracy, or false-positive rates.
Real-world impact: Reducing churn by targeting at-risk groups with offers and better product experiences. Checking results with A/B testing. Confirming that the model-driven approach outperforms baseline heuristics.
Follow-up Question 1
How do you handle data drift when the underlying user behavior shifts?
Short Answer: Detecting drift through distribution comparison helps identify when features or relationships change. If changes are large, retraining with newer data and updating the pipeline addresses the drift.
Detailed Explanation: Sampling new user data and measuring distribution distance from the training set reveals drift. Techniques like Population Stability Index or Kolmogorov-Smirnov test highlight differences in feature distributions. Large divergences prompt collecting new labels and retraining the model with fresh examples. Scheduling periodic retraining or building an online learning mechanism ensures continuous adaptation.
Follow-up Question 2
How would you ensure model interpretability?
Short Answer: Combining interpretable models, or using post-hoc explainers on black-box models helps you see feature importance and reason about predictions.
Detailed Explanation: Logistic regression has direct coefficient interpretation. Gradient boosting explains outputs by post-hoc methods like SHAP (SHapley Additive exPlanations). Each feature's contribution to the final prediction is computed, clarifying which factors drive churn risk. Reviewing high-impact features helps refine data collection or confirm domain insights.
Follow-up Question 3
How do you handle imbalanced churn labels?
Short Answer: Sampling techniques or specialized loss functions address label imbalance, ensuring the minority class signals remain strong.
Detailed Explanation: Oversampling the positive churn class (for example Synthetic Minority Over-sampling Technique) or undersampling the majority class. Adjusting class weights or using focal loss in boosting. Monitoring recall or F1 score ensures the model captures churners without overwhelming false positives.
Follow-up Question 4
How do you confirm your model is production-ready?
Short Answer: Stable performance, consistent metrics across validation and real data, robust monitoring, and a well-structured deployment pipeline indicate readiness.
Detailed Explanation: Performing offline validation with multiple splits. Doing shadow deployments where the new model runs in parallel with the old model before fully replacing it. Tracking performance and identifying anomalies in prediction logs. Testing edge cases. Reviewing resource usage and scalability in production. Once validated, flipping traffic to the new model.
Follow-up Question 5
Why would you prefer gradient boosting over neural networks for this use case?
Short Answer: Gradient boosting is simpler to train on tabular data, often performs better with fewer data samples, and is more explainable for enterprise contexts.
Detailed Explanation: Tabular data with many features or missing values often suits decision tree ensembles. Neural networks can demand large data, careful architecture tuning, and more compute. Gradient boosting has proven performance and interpretability enhancements with tools like SHAP. Faster experimentation and simpler hyperparameter grids help accelerate iteration cycles.
Follow-up Question 6
How do you conduct A/B testing for the churn intervention strategy?
Short Answer: Splitting the at-risk user population into a control group and a treatment group, each receiving or not receiving interventions. Measuring churn metrics over time.
Detailed Explanation: Tracking both groups' churn rates, usage patterns, and revenue. Comparing differences in outcomes. Statistically significant improvements for the treatment group confirm the model’s effective identification of users at risk. Rotating treatments or personalizing interventions fine-tunes the strategy.
Follow-up Question 7
How would you handle real-time inference at scale?
Short Answer: Serving the model with a highly available service. Using an in-memory store for quick feature retrieval. Horizontally scaling with load balancers.
Detailed Explanation: Deploying the model in a container or microservice structure behind an endpoint. Caching features or computing them in streaming form. Ensuring minimal latency with a fast scoring engine. Autoscaling the service as user traffic grows. Writing usage logs to central storage to track errors and monitor throughput.
Follow-up Question 8
What are your main concerns for data privacy and compliance?
Short Answer: Securing user data and meeting regulatory needs by anonymizing data, removing personally identifiable information, and restricting sensitive data usage in model training.
Detailed Explanation: Encrypting data at rest and in transit. Following protocols like General Data Protection Regulation for any user data in the pipeline. Minimizing retention of sensitive fields or applying tokenization. Strict access control to production environments. Documenting compliance steps thoroughly.
Follow-up Question 9
How do you scale this pipeline to multiple regions worldwide?
Short Answer: Setting up a distributed data pipeline with regional data storage. Training region-specific models if user behavior is highly localized.
Detailed Explanation: Using cloud-based architectures that replicate data geographically. Building region-specific models ensures cultural or market differences are captured. Or training a global model if usage patterns are similar. Monitoring each region separately for churn metrics, model performance, and data drift. Deploying region-specific endpoints if necessary.
Follow-up Question 10
How do you approach feature selection to reduce model complexity?
Short Answer: Iteratively dropping less-informative features and using domain knowledge or feature importance scores to keep the top contributors.
Detailed Explanation: Training with all features, then examining feature importances from gradient boosting or logistic regression coefficients. Eliminating features with minimal contribution. Checking performance changes. Reducing the feature set can improve inference speed and reduce overfitting risks. Maintaining a core set of robust features ensures stable predictions.
Final Remarks
Building a churn prediction model involves data integration, feature engineering, algorithmic selection, model explainability, and real-time deployment. Addressing data quality, drift, and compliance ensures the solution remains accurate and responsible.