
ML Case-study Interview Question: Contextual Bandits with Predicted Delayed Rewards for Better Long-Term Recommender Satisfaction.


Browse all the ML Case-Studies here.
Case-Study question
A streaming service wants to improve its recommendation system for long-term user satisfaction instead of just short-term clicks or immediate engagement. They have extensive user interaction logs for plays, completions, and user ratings. They notice that users often discover new genres and engage heavily afterward, but the service only detects these interactions weeks later. Their goal is to capture these delayed signals while keeping the recommendation model updated frequently. They also observe that optimizing pure retention is noisy and slow to measure. The company asks for a solution to define a better reward function and handle delayed feedback prediction, then integrate it into a bandit-based recommender system.
Proposed Solution
Overview A contextual bandit model handles real-time recommendations. The main task is to define a proxy reward that tracks long-term satisfaction signals. Optimizing for clicks (or plays) alone can produce short-term gains but may fail on overall satisfaction. A multi-step approach addresses delayed feedback while still updating the recommendation policy quickly.
Defining the Proxy Reward
Instead of using retention or raw engagement, define a function that captures meaningful user signals:
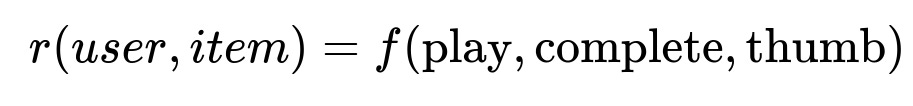
Here:
playmeans an immediate or short-term view.completetracks if the user finished a show or movie.thumbrepresents a positive or negative rating or reaction.
Combine these signals into a single value that aligns with enjoyment. High values come from quick completions and positive reactions. Low values come from negative reactions or abandoned viewings.
Handling Delayed Feedback
Many events (completions, ratings) happen well after the initial recommendation. The system needs these signals to evaluate the proxy reward. Waiting for them all introduces delays in model updates. Use a delayed feedback prediction model to guess eventual outcomes based on partial observations. This prediction model runs offline and produces the missing signals for training examples so the main policy can be updated regularly with approximate but timely labels.
Training Two Types of Models
Delayed Feedback Prediction This model predicts
p(final_feedback | observed_feedback)for each event. Training data includes any partial signals and user context. It outputs an estimate of future reactions.Bandit Policy The contextual bandit uses updated rewards (observed + predicted) to recommend items that maximize the proxy reward. This policy is deployed online to serve real-time recommendations.
Resolving Online-Offline Metric Disparities
Offline models may show better metrics (such as classification AUC) yet fail in real-world A/B tests that measure long-term satisfaction. The fix involves refining the proxy reward definition so that improvements in the offline metric correlate with genuine gains in real-world outcomes. When proxy and actual goals align, both offline and online metrics rise together.
Detailed Solution Steps
1. Data Collection
Pull interaction logs from user actions: brief plays, long plays, completions, and user ratings. Mark timestamps so you know how delayed each signal is.
2. Reward Engineering
Create a single label per recommendation event. Aggregate short-term signals (plays) with predicted long-term signals (completions, ratings). If actual feedback arrives late, use the delayed feedback prediction to fill gaps.
3. Model Architecture
Use large-scale neural networks or tree-based methods for the delayed feedback prediction model. For the bandit, maintain context vectors from user features, then predict expected reward. Rank items by this predicted reward for each user session.
4. Iteration and Refinement
Periodically retrain the delayed feedback model so that newly arrived data corrects any past mistakes. Regenerate rewards and retrain the bandit policy.
5. Online Deployment
Deploy the updated policy. Run A/B tests. Compare metrics such as user engagement over weeks and watch for improvements in long-term satisfaction metrics (thumbs-up rate after completions, time spent completing a series without skipping, potential diversity of content).
Follow-up Question 1
How would you handle uncertainty in predicted signals for incomplete user feedback?
Answer Compute a confidence interval or probability for each predicted signal. If a user’s final rating has high uncertainty, lower its weight in the combined reward. This approach avoids over-reliance on unreliable predictions. A method is to keep an estimated variance from the delayed feedback model. For a recommendation example with high variance, reduce that data’s contribution when calculating the final proxy reward.
Follow-up Question 2
How do you mitigate the risk that the proxy reward might still be incomplete or misaligned with true satisfaction?
Answer Perform repeated reward engineering cycles. Start with a hypothesis on which signals matter, deploy the changes, observe if real user satisfaction (retention, sustained engagement) improves. If misalignment persists, refine the reward formula. Incorporate more signals like category discovery, session-level dwell time, or user-reported satisfaction. This iterative loop continues until the policy’s online performance and the proxy’s offline metrics converge.
Follow-up Question 3
What if the updated bandit policy starts exploiting popular items that yield quick engagement but lacks diversity in recommendations?
Answer Introduce diversity or novelty constraints in the bandit objective. Re-rank items by the expected reward but also track how often a user sees similar content. Penalize highly repeated categories. Enforce a minimum variety to avoid excessive exploitation of trending content. This can be included by adjusting the policy’s ranking function to trade off between predicted reward and diversity scores.
Follow-up Question 4
Could there be a reinforcement learning approach that outperforms a simple bandit with a single reward at each interaction?
Answer A full reinforcement learning approach can model multi-step user interactions. It can optimize a future cumulative reward, factoring in sequences of recommendations over multiple sessions. However, implementation complexity is higher. You need environment simulations or off-policy evaluation methods to handle large-scale real-world data. For many practical cases, contextual bandits with carefully engineered rewards are more straightforward to maintain and scale.
Follow-up Question 5
How would you monitor and test whether the delayed feedback predictions are hurting performance?
Answer Track a hold-out set of user data where you compare actual future feedback with predicted labels. Record metrics like precision, recall, calibration. If the delayed feedback model drifts, the bandit policy might degrade. You can run an A/B experiment where one branch uses only observed signals while the other uses predicted signals. Compare changes in real user satisfaction and see if the predicted approach still provides a net benefit.
Follow-up Question 6
How do you identify the optimal time window before making the feedback prediction?
Answer Experiment with different wait periods for data collection before labeling. Analyze the trade-off between having more accurate feedback (by waiting longer) and having fresher recommendations (shorter wait). Pick a window size that balances the model’s performance improvement against potential staleness in new items. Run offline experiments to see how predictive accuracy changes across different wait times, then confirm the best trade-off with an A/B test.
Follow-up Question 7
What potential biases might appear when using thumbs-up or thumbs-down signals in the reward definition?
Answer Not all users provide explicit ratings. Users who do might be more opinionated. This can skew the reward distribution toward those who engage with the rating feature. It also might overemphasize certain genres if some groups rate them more actively. Incorporate implicit feedback or predicted sentiment to mitigate such bias. If a segment rarely rates, use alternative signals such as re-watch patterns or partial watch patterns to fill the gap.
Follow-up Question 8
Explain how you handle brand-new items or shows with no engagement history.
Answer Rely on content-based features or side information for cold-start recommendations. Use item-level metadata (genre, cast) to estimate reward from similar items. As soon as user interactions appear, fold them into the bandit’s training. For extremely new content, keep an exploration mechanism so that the policy tries these items even with uncertain or zero historical data. A small randomization factor can uncover hidden gems.
Follow-up Question 9
How do you ensure your model remains stable when new user behavior trends or new content types emerge?
Answer Maintain a frequent retraining schedule and adopt incremental learning if needed. Track key distribution shifts in content, watch durations, and user ratings. If a new genre arises, make sure your feature store captures it. If the model’s performance on recent data declines, expedite retraining. Use robust data pipelines that handle new item attributes or changes in user behavior without crashing or producing invalid features.
Follow-up Question 10
How would you extend this system beyond recommendations for shows or movies to other product categories?
Answer Generalize the core idea of a proxy reward and delayed feedback prediction. In e-commerce, track purchase completion vs. returns or user reviews. In online learning platforms, track course completion vs. user ratings. The same bandit approach with a carefully chosen proxy reward and a delayed feedback model can adapt. You keep adjusting the signals that matter most in each domain (time spent, successful completion, satisfaction indices).