
ML Case-study Interview Question: Unsupervised Multi-Label Text Classification Using Word Embedding Distance


Browse all the ML Case-Studies here.
Case-Study question
A large travel company processes thousands of customer feedback messages daily. They need to route each message to the relevant internal team. The messages can span multiple categories such as Flight issues, Hotel concerns, and other areas, but the company lacks any labeled training data. Design an unsupervised multi-label text classification solution that handles this complexity and scales efficiently.
Detailed Solution
The company cannot rely on a supervised model because they do not have labeled data. They also need robust categorization that understands semantic relationships, not just direct synonyms. Below is a proposed solution.
High-Level Approach Use a pre-trained word-embedding model to map words into a vector space. Measure distance between words in that space to understand semantic similarity. Combine these distances with a heuristic algorithm to make classification decisions.
Step 1: Data Preprocessing Clean and normalize the text. Convert to lowercase. Remove punctuation and special characters. Tokenize into words. Filter out stopwords if needed.
Step 2: Word Embeddings Download and load a GloVe embedding file. Each word is represented by a high-dimensional vector.
Step 3: Distance Measurement Compute how close (or far) each token in the incoming feedback is from candidate category vectors. A common choice is Euclidean distance between word vectors.
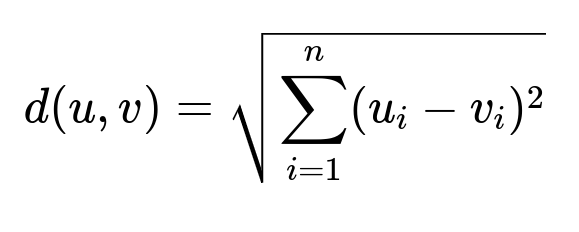
Where u and v are embedding vectors. The index i runs over vector dimensions. Larger distance means weaker similarity. Smaller distance means stronger similarity.
Step 4: Heuristic Classification Define thresholds (N) for each category. Compare each feedback token’s distance to each category word vector. If the distance is below a threshold, tag the feedback with that category. Adjust N to get better coverage or to reduce false positives.
Step 5: Multi-Label Handling Any feedback can map to multiple categories if more than one threshold condition is satisfied.
Step 6: Further Refinement Add simple rules to boost or suppress certain categories if domain knowledge applies. For example, certain keywords might force a label even if the distance is slightly higher.
Practical Implementation
Below is a sample Python code snippet illustrating the loading of GloVe embeddings, calculating distances, and assigning labels. Explanations follow.
import numpy as np
# Load GloVe embeddings (example file, actual path might differ)
# Each line in the GloVe file: word followed by space-separated values
def load_glove_embeddings(file_path):
embeddings = {}
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
values = line.strip().split()
word = values[0]
vector = np.asarray(values[1:], dtype='float32')
embeddings[word] = vector
return embeddings
def get_distance(vec1, vec2):
# Euclidean distance
return np.linalg.norm(vec1 - vec2)
def classify_feedback(feedback_tokens, categories, embeddings, thresholds):
# categories = { 'Flight': ['flight','plane'], 'Hotel': ['hotel'], ... }
# thresholds = { 'Flight': 4.0, 'Hotel': 4.0, ... }
assigned_categories = set()
for token in feedback_tokens:
if token in embeddings:
token_vec = embeddings[token]
for cat_name, cat_keywords in categories.items():
cat_min_dist = float('inf')
for kw in cat_keywords:
if kw in embeddings:
dist = get_distance(token_vec, embeddings[kw])
if dist < cat_min_dist:
cat_min_dist = dist
if cat_min_dist < thresholds[cat_name]:
assigned_categories.add(cat_name)
return list(assigned_categories)
# Example usage
glove_path = 'glove.6B.50d.txt'
glove_embeddings = load_glove_embeddings(glove_path)
categories_dict = {
'Flight': ['flight', 'plane', 'flew'],
'Hotel': ['hotel', 'motel'],
'Car': ['car', 'vehicle']
}
thresholds_dict = {
'Flight': 4.0,
'Hotel': 4.2,
'Car': 4.5
}
feedback_message = "We flew an hour late"
tokens = feedback_message.lower().split()
labels = classify_feedback(tokens, categories_dict, glove_embeddings, thresholds_dict)
print("Assigned labels:", labels)
Short explanation of the code:
load_glove_embeddings reads vectors from a GloVe file into a dictionary.
get_distance calculates the Euclidean distance.
classify_feedback iterates over tokens and finds their closest category. Thresholds are used to decide if a token is strongly related to a category.
Follow-Up Question 1
How would you handle overlapping categories if a single token is close to multiple embeddings?
Answer Keep the model multi-label. If a token’s distance to more than one category is below their respective threshold, assign both. If an overlap leads to high false-positives, tune thresholds or apply extra rules. Example: if tokens “flew” and “delayed” appear, we might raise the Flight category’s score but keep open the possibility of Hotel if “room” or “lobby” also appears.
Follow-Up Question 2
How do you decide on the distance threshold for each category?
Answer Compute distances on a sample set of representative feedback. Plot or inspect the distribution of distances for true matches vs. false matches. Observe the gap and pick thresholds around the point that balances false-negatives and false-positives. Adjust per category if needed. Some categories might have narrower or broader semantic space.
Follow-Up Question 3
How do you reduce dimensionality for visualization or debugging?
Answer Use something like Principal Component Analysis (PCA). Project high-dimensional vectors onto fewer dimensions. Examine them in 2D or 3D plots to see how tokens cluster around category keywords. This is only for interpretability. Actual classification uses the full embedding dimension.
Follow-Up Question 4
What if a new domain or new product category emerges?
Answer Add new category keywords to the dictionary. Re-run the threshold tuning with a small set of examples if possible. No re-training of embedding is necessary if it is a general-purpose model like GloVe. If brand-new vocabulary appears, either retrain embeddings on a new corpus or try context-aware embeddings like BERT.
Follow-Up Question 5
How would you scale this approach to millions of messages?
Answer Cache embeddings in memory or use a fast vector database. Parallelize distance calculations. Consider approximate nearest-neighbor techniques if the category list grows large. Move non-critical tasks like threshold tuning offline. Use a distributed framework like Spark if needed.
Follow-Up Question 6
Could you use cosine similarity instead of Euclidean distance?
Answer Yes. Cosine similarity is often better for text embeddings because it focuses on direction over magnitude. Replace the distance function with a similarity measure. Then invert the threshold logic (look for similarity above a threshold). The rest of the pipeline remains the same.
Follow-Up Question 7
How do you handle synonyms or misspellings that are out of the pre-trained vocabulary?
Answer For synonyms, the embedding model should capture semantic closeness if they appeared in the training corpus. For out-of-vocabulary words or spelling errors, you might do subword embeddings, or apply a spell-checker to fix them before looking up vectors. Consider fallback rules if the token cannot be found in the embedding dictionary.
Follow-Up Question 8
How do you measure accuracy and quality when you have no labeled data?
Answer Use human-in-the-loop verification. Sample feedback and let domain experts check predicted categories. Collect enough feedback to approximate precision and recall. For detailed analysis, create a small labeled set. Compute confusion matrices. Iterate on thresholds and category lists accordingly.
Follow-Up Question 9
What if many feedback messages are extremely short or contain domain-specific jargon?
Answer Short feedback might have few tokens. Combine domain knowledge or incorporate synonyms. For jargon, either build custom embeddings from domain-specific corpora or augment a general model with domain text. Validate with SME (subject matter expert) feedback. Adjust thresholds to reduce edge-case errors.
Follow-Up Question 10
Would you consider a hybrid approach using partial labeling at scale?
Answer Yes. You could label a small set of feedback examples, then fine-tune a powerful transformer-based classifier. Use unsupervised embeddings to bootstrap an initial classification pipeline. Gradually grow the labeled set. Once you have enough labeled data, switch or integrate a supervised model that might be more accurate in the long run.