
ML Case-study Interview Question: Accelerating Content Moderation Model Updates Using AutoML Pipelines


Browse all the ML Case-Studies here.
Case-Study question
You are hired as a Senior Data Scientist at a large social media platform. The platform faces evolving threats of deceptive content, misinformation, and fraudulent posts. They need a more automated and proactive content moderation pipeline that regularly retrains abuse detection models on fresh data. Data scientists currently spend months re-training models, often performing repetitive tasks like data preprocessing, feature transformation, hyperparameter tuning, and model evaluation. The leadership wants a framework to speed up the entire process, ensure accuracy, and free up data scientists’ time to focus on more innovative tasks. How would you design such a system? How would you address challenges related to continual learning, scaling, deployment, and governance so the system remains robust, fair, and effective?
Detailed solution
AutoML integrates repetitive machine learning workflows and orchestrates all steps of model development. It processes large-scale datasets, cleans and transforms them, searches across multiple algorithms and hyperparameters, evaluates candidate models, and selects the best one for deployment. In a content moderation scenario, AutoML aligns well with the need for continuous adaptation against changing threats.
Data Preparation and Feature Transformation
Engineers ingest raw content such as text, images, or video metadata from a data lake or distributed file system. AutoML workflows apply automated cleaning steps such as noise removal, dimensionality reduction, and text preprocessing. Automated feature engineering captures statistical signals that might be predictive of violations. AutoML tries different transformations like word embeddings, TF-IDF vectors, or advanced feature encodings for images. It stores the refined features in an offline environment for subsequent training.
Model Training and Hyperparameter Search
AutoML launches parallel experiments on different model architectures including boosted decision trees, logistic regression, and neural networks. It systematically tests hyperparameters like learning rates, regularization strengths, or tree depths. It checks performance metrics such as precision, recall, or F1 score on validation data. It saves data scientists from manual iteration.
A crucial loss function in content classification tasks is cross-entropy. For a given sample with class label in p_i (ground-truth) and predicted probability in q_i (model output):
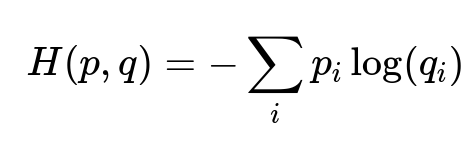
p_i represents the actual distribution over classes (1 for the true class, 0 otherwise). q_i represents the predicted distribution. This function penalizes wrong predictions heavily. AutoML monitors changes in H(p,q) during training to pick architectures that minimize classification error.
Threshold Tuning and Model Selection
AutoML systematically searches for an optimal classification threshold. It checks performance at each threshold by calculating metrics on a holdout set. It may optimize for specific operational constraints such as running at high precision (low false positives) to prevent blocking harmless content. It generates thorough reports comparing new models against baselines on metrics like area under the ROC curve or false positive rates. Data scientists examine these reports and decide whether to promote the new model.
Continual Learning
AutoML retrains models on recent data based on a schedule. This addresses data drift, shifting global events, and adversarial attacks. The pipeline automatically updates features and hyperparameters. Engineers retain older snapshots for rollback. The system ensures that new and old distribution shifts get incorporated into the next training round, minimizing the chance of outdated models.
Deployment
AutoML automates model packaging and publishes the artifacts to production storage. Production services call the deployed model with content samples, verifying inputs and outputs match the expected schema. This process integrates with the platform’s moderation infrastructure so decisions happen in near real-time. AutoML workflows track versioning to allow quick rollback if anything goes wrong.
Governance and Fairness
AutoML enforces robust checks for fairness by monitoring disproportionate error rates across user groups. The pipeline logs metrics related to discrimination and bias. In future iterations, generative AI may enrich training examples or filter noisy labels to improve data quality. The organization maintains a governance framework that includes fairness audits and transparency disclosures.
Scaling and Optimizations
The platform invests in distributed compute clusters with GPUs for parallel hyperparameter tuning. The pipeline caches partial results, ensures concurrency limits, and monitors memory usage. Developers control the granularity of configuration to balance ease-of-use with advanced tunability. AutoML orchestrates these optimizations so model training remains fast and reliable even when scaled.
How to handle follow-up questions
Below are potential follow-up questions with detailed answers.
How do you detect and mitigate data drift in this pipeline?
Data drift appears when production data starts deviating from the training data distribution. The platform monitors input features such as word usage or image characteristics. AutoML logs summary statistics over time and compares them to the training distribution. If sharp differences arise, it triggers a retraining run. Engineers also examine model outputs for unexpected spikes in false positives or false negatives. If drift is detected, the pipeline re-collects data, updates feature encodings, and runs a new training cycle. This ensures the model stays aligned with current trends.
What if a newly deployed model shows worse performance than the baseline?
AutoML always keeps the last proven baseline model archived. If a newly deployed model degrades performance, the team reverts to the baseline. Engineers review the logs and the generated reports to understand if there was a certain hyperparameter or data-related cause. They adjust the training process, retrigger the AutoML pipeline, and confirm that the issue is resolved before redeployment. The system logs these events, allowing for better root cause analysis in future training runs.
How do you ensure the system scales to multimedia and multi-task scenarios?
Different classifiers for text, images, or video can share a common AutoML pipeline. The data ingestion step detects content type and chooses appropriate feature transformers. Multi-task models can be trained by modifying the architecture search to handle multiple output heads for classification. The pipeline ensures the correct data loader and preprocessing. Extra compute resources with specialized hardware accelerate large-scale experiments. Engineers add relevant modules into the pipeline for tasks like multimodal feature fusion, letting AutoML orchestrate them in parallel.
How do you integrate fairness checks into AutoML?
Fairness requires consistent metrics and sampling across demographic subgroups. AutoML includes optional modules that measure precision, recall, and false positive rate for each subgroup in a holdout set. It highlights any significant performance gap. If the pipeline observes large discrepancies, it flags them for review. Developers can correct the model, adjust data sampling or apply techniques like re-weighting examples. Teams document these results for compliance and public transparency, ensuring the final model aligns with fairness guidelines.
Why is threshold tuning so important in content moderation?
Content moderation often prioritizes high precision, since blocking legitimate content is a major concern. Some cases need higher recall to catch most of the abuse. Threshold tuning strikes a balance by picking the score cutoff that meets the platform’s goals. AutoML iterates over different thresholds, computing metrics for each. It selects the threshold that meets the specified operational metric, like maximizing recall above a certain precision. This ensures the classifier’s final decision boundary aligns with policy constraints.
How does generative AI improve data quality or help produce synthetic data?
Many model failures stem from missing or imbalanced training data. Generative AI can create synthetic samples for underrepresented categories or transform existing content to introduce new variations. Large language models can generate text variants or rewrite messages. Image generative models can simulate visuals for rarely seen abusive themes. These synthetic examples broaden the training distribution and help the model generalize. The AutoML pipeline then uses these new samples during its standard training cycle. Engineers confirm that synthetic data is labeled accurately and does not introduce unintended biases.
How would you handle new algorithms or hardware dependencies in the pipeline?
AutoML is modular. A new algorithm can be integrated by implementing a consistent interface for data ingestion, hyperparameter configuration, training, and evaluation. The pipeline orchestrator calls this interface just like it calls other algorithms. If hardware dependencies such as GPUs or specialized accelerators are required, the pipeline dynamically schedules resources. Engineers specify these requirements in the configuration. AutoML then routes tasks to compute nodes with the appropriate hardware. This approach keeps the system flexible and future-proof.
How can you keep development velocity high for new experiments?
AutoML automates repetitive tasks like hyperparameter tuning, model evaluation, threshold selection, and deployment packaging. Data scientists simply specify the training data location, the set of algorithms to try, and their optimization goals. The system schedules everything in parallel and tracks results. Detailed logs and dashboards let them see which models are promising. This instant feedback loop encourages faster iterations, letting them push new experiments without manually writing code for each.
AutoML in a content moderation context cuts down lead times from months to days, ensuring the platform remains safe, relevant, and capable of defending against evolving content threats.