
ML Case-study Interview Question: Fixing Data Job Failures: Cost-Optimized Auto-Remediation using ML & Bayesian Optimization.


Browse all the ML Case-Studies here.
Case-Study question
A major data platform processes millions of jobs each day across a large distributed system. Despite low failure rates, the volume of failed jobs is significant enough to impose operational burdens. Many errors stem from misconfigurations (especially memory) and unclassified failures. You are tasked with designing and implementing a Machine Learning powered Auto Remediation system to reduce repeated manual fixes, operational costs, and to improve the reliability of job scheduling.
Craft a detailed end-to-end solution. Propose how to:
Integrate an existing rule-based error-classification service with ML models.
Identify and remediate memory configuration issues.
Handle unclassified errors in a cost-efficient way.
Integrate with the scheduling and configuration services for automatic application of recommended settings.
Optimize for both success probability and compute cost.
Evaluate improvements in reliability and cost savings.
Show your recommended data pipelines, ML models, cost optimization approaches, system architecture design, and any platform considerations.
In-depth Solution
Architecture Overview
Auto Remediation has two primary components: a rule-based classifier and an ML service. The rule-based classifier assigns errors to known categories and indicates if a job can be restarted automatically. The ML service then determines specific parameter changes for memory configurations or decides whether the retry is likely to succeed.
Rule-based Classifier uses static rules and regex patterns to classify errors. If the error is:
A known memory configuration issue, the rule-based system marks it for possible reconfiguration.
An unclassified error, the ML model checks if it can fix it by mutating configuration parameters or disabling retries.
ML Service predicts the success probability of a retry and the likely compute cost. It performs a Bayesian Optimization search over configuration parameters to find a solution that minimizes a combined objective of failure probability and cost.
Scheduler calls the classifier upon each job failure. If the classifier or ML service recommends a retry with a new configuration, the scheduler fetches the suggested parameter changes from a configuration service and retries the job.
Key Mathematical Objective
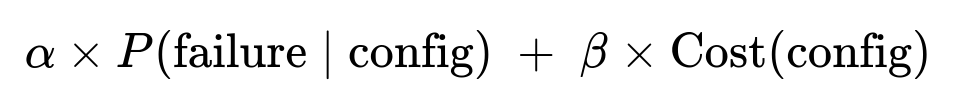
Above expression represents a linear combination of failure probability and compute cost, where:
P(failure | config)is the predicted chance of failure with the candidate configuration.Cost(config)is the predicted compute expense in dollars.alphaandbetaare coefficients reflecting trade-offs (e.g., a higher alpha places more emphasis on minimizing failures over saving cost).
Detailed Steps
Failed Job Detection Scheduler detects the job failure and queries the rule-based classifier with the job logs.
Rule-based Matching If the error matches a known rule for memory misconfiguration or is entirely unclassified, the classifier calls the ML service to gather a second-layer recommendation.
ML Model Inference The ML service (using a feedforward neural network) estimates:
Probability of success if the job is retried with certain parameter mutations.
Execution cost of that retry.
Bayesian Optimization The service uses iterative search to generate and evaluate candidate configurations. It queries the model for the predicted failure probability and cost under each candidate. Once it completes the search within a short time window, it picks the best solution.
Configuration Update If the ML service finds a feasible configuration, it sets the recommended memory and core parameters in the configuration service. If no feasible solution is found, it disables retries to avoid extra costs.
Job Retry Scheduler retrieves the updated configuration from the configuration service and retries the job with the new settings.
Observations If a job is frequently failing with unclassified errors, the ML service might disable retries to reduce wasted cost. If certain high-priority jobs must always retry, the rule-based classifier can override the ML service by applying a specific rule.
Python Example
Below code shows a simplified way to do Bayesian Optimization with a feedforward neural network for predicted cost and failure probability. This is just conceptual. Actual service integrations would be more complex.
import numpy as np
from some_ml_library import MyMLModel
from ax.service.ax_client import AxClient
# Pretrained model
model = MyMLModel.load("path_to_production_model")
def evaluate_config(params):
# Construct feature vector with candidate config
features = build_feature_vector(params)
# Predict failure probability and cost
p_fail, cost = model.predict(features)
# Weighted objective
alpha = 0.5
beta = 0.5
return alpha * p_fail + beta * cost
ax_client = AxClient()
ax_client.create_experiment(
name="auto_remediation_experiment",
parameters=[
{"name": "executor_memory", "type": "range", "bounds": [1024, 8192]},
{"name": "executor_cores", "type": "range", "bounds": [1, 16]}
# Additional parameters
],
objective_name="combined_loss",
minimize=True
)
for _ in range(10):
params, trial_index = ax_client.get_next_trial()
outcome = evaluate_config(params)
ax_client.complete_trial(trial_index=trial_index, raw_data=(outcome, 0.0))
best_params = ax_client.get_best_parameters()[0]
Explanation:
build_feature_vector(params)merges job metadata and mutated config values.model.predict()returns(p_fail, cost)from the neural network.evaluate_config(params)computes a combined metric to reflect overall cost-effectiveness.Ax’s
get_best_parameters()fetches the optimum within the iteration limit.
Production Impact
The system reduces manual troubleshooting of memory issues by automatically reconfiguring Spark parameters. It also eliminates wasted retries for repeated non-transient errors. Actual rollout results in:
56% remediation rate of memory failures.
Around 50% cost reduction on the failed-job pool.
Future Extension
Right Sizing. Beyond fixing failed jobs, a next step is proactively adjusting job configurations (e.g., memory, cores, container sizes) for all jobs, even successful ones, to reduce resource overprovisioning.
Possible Follow-up Questions
How do you handle frequent new error types that are not recognized by the rule-based classifier?
Rule-based classifiers cannot easily keep pace with new error patterns. The system must rely on the ML model to extract signals from logs and job metadata. A robust approach includes:
Automatic label creation using heuristics or active learning.
Monitoring jobs that fail frequently with no classification match to refine feature-engineering pipelines.
Periodically reviewing misclassification cases to introduce new rules for high-priority or business-critical failures.
How do you ensure user confidence that your ML-based retry decisions will not disable important workflows?
Use a conservative disabling policy, especially for unclassified errors. If the user strongly prefers to always retry, create a specialized rule. Over time, calibrate your risk tolerance by comparing actual outcomes with predicted outcomes. Introduce a fallback rule in the classifier for certain pipelines or mission-critical jobs.
Why use Bayesian Optimization instead of a simple grid search for recommended configurations?
Bayesian Optimization is sample efficient when searching over complex parameter spaces. It uses a surrogate model that guides the search toward promising regions with fewer expensive evaluations. A grid search might require a large combinatorial exploration leading to timeouts or suboptimal results in a limited evaluation budget.
What if the ML model times out or fails to find a feasible solution?
If the model times out:
Fallback to the default rule-based approach or a safe baseline configuration known to work in many cases. If no feasible solution is found:
Disable retries to avoid unnecessary cost. These scenarios require careful logging and monitoring. Over time, refine the model or add new rules if repeated timeouts are observed for the same error patterns.
How would you extend the solution to non-Spark workloads?
Generalize the pipeline. Instead of focusing on Spark-specific parameters, define an interface for retrieving relevant features from any runtime environment. Replace Spark’s config parameters with those relevant to the new framework, then retrain or adapt the model. The same approach (predict success probability and cost, optimize with Bayesian search, mutate config) still applies.
How do you handle large-scale online inference and ensure minimal latency?
Host the model with a lightweight serving layer. Use compact MLP architectures with minimal hidden layers to keep inference fast. Apply caching for repeated queries on identical jobs. If feasible, batch inference requests when multiple job failures occur simultaneously to reduce overhead. Always set strict timeouts in the scheduler and degrade gracefully to a known fallback if the ML service is slow or unreachable.