
ML Case-study Interview Question: Random Forest for Effective AML Risk Scoring and Alert Prioritization


Case-Study question
A global financial institution noticed an increasing number of suspicious transactions across its customer base. They had an existing rule-based system to flag potential money laundering, but it generated too many false positives and was slow to adapt to evolving criminal strategies. They want to implement a scalable Machine Learning system that can ingest large volumes of transaction data, generate meaningful risk scores for each suspicious alert and prioritize investigative reviews. Propose how you would design, build, and productionize such a system that supports Anti-Money Laundering goals, reduces false positives, and remains explainable to both internal stakeholders and regulators.
Detailed Solution
The system requires ingesting extensive transaction data and combining it with relevant customer attributes. A rules-based approach generates alerts in a binary manner (alert or no alert). To optimize, integrate a Machine Learning (ML) model that assigns risk scores to alerts and helps investigators focus on the highest-risk transactions first.
Design Considerations
Short sentences:
Use a random forest or similarly robust algorithm. Keep the model explainable by design. The system must handle large, dynamic data with minimal overfitting. Investigators and regulators must trust how it scores alerts.
Random Forest was a good choice in an actual production scenario for balancing performance, interpretability, and ease of tuning. It outperformed simpler methods (like logistic regression) and had comparable accuracy to more complex methods (XGBoost, RNN) without sacrificing clarity.
Model Formulation
To classify an alert as suspicious or not, random forest combines many decision trees and aggregates their outputs. One key formula for the predicted probability in a random forest classifier is:
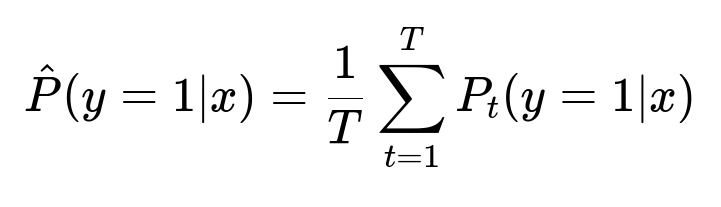
Where:
T is the number of decision trees in the forest.
P_t(y=1|x) is the probability estimate of class "1" (suspicious) by tree t.
x represents the input feature vector, such as a customer's transaction attributes.
Each tree is trained on a bootstrapped sample of the data, and the final output is the average of the individual trees’ outputs.
Building Features
The model uses transaction volume, frequency of certain payment types, customer profile data, high-risk destination countries, and historical investigation results. If a past investigation labeled certain patterns suspicious, the model learns to assign higher risk scores to similar patterns in the future.
To keep the feature set reliable:
Continuously track performance shifts.
Prune features that add little value or create confusion.
Re-train or tune as customer behaviors change (for instance, surges in peer-to-peer transfers).
Scoring and Prioritization
Instead of producing a binary alert, each detected event receives a numeric risk score. Investigators focus on high-scoring alerts first, while low-scoring alerts can be subject to minimal screening or automated secondary checks.
Transparency and Explainability
Because Anti-Money Laundering is heavily regulated, maintain full documentation of:
The data sources and transformations.
The model architecture.
Model performance metrics and thresholds.
Validation procedures for each production release.
Subject matter experts within the compliance team review and validate the scoring logic. They also help interpret any outliers or false positives.
Operational Flow
Data ingestion: Transaction logs flow in near real-time or at fixed intervals.
Rule-based trigger: Initial screening flags potential suspicious activity.
ML scoring: The random forest model processes each alert and assigns a risk score.
Investigative workflow: High-risk alerts go to immediate human review. Low-risk alerts may get auto-documented or queued for later.
Monitoring: Regular checks for feedback loops or performance drifts.
Results
In practice, random forest scores enabled faster reviews and fewer false positives. The compliance team focused on the highest-risk alerts. Low-scoring alerts still got reviewed, but in a more automated manner. The outcome was an overall reduction in manual workloads and improved detection of true suspicious behavior.
Possible Follow-Up Questions and Answers
What if regulators demand proof that the model is trustworthy?
Explain that you implemented:
Regular model audits using historical, labeled investigations.
Clear version control for feature sets and model parameters.
Reproducible training pipelines, so a regulator can train the same model and validate outputs.
Monthly accuracy reports, confusion matrices, and threshold adjustments for risk scoring.
Describe how you also keep robust documentation of the data lineage and transformations so regulators see exactly how raw transactions become input features.
How do you prevent overfitting, given that laundering patterns change over time?
Describe that you:
Split data into training, validation, and test sets across different time frames.
Regularly measure out-of-time performance for each new data batch.
Keep the feature set from becoming too large by removing features that are too specific to one period.
Retrain or fine-tune the model on recent data to account for evolving tactics.
Use techniques like cross-validation and model drift detection to watch for performance drops.
Why not simply use a deep learning approach?
State that while deep learning can detect complex patterns, it can also:
Be harder to interpret.
Require more data and might be slower to train.
In certain cases, random forest or XGBoost can achieve similar predictive performance with better explainability.
Mention that you can still test a deep learning solution in a separate pipeline but emphasize your choice is guided by the need for a straightforward, justifiable model.
How do you ensure investigators trust the system?
Show them that:
The model’s risk scores align well with actual outcomes (confirmed suspicious vs. not).
Detailed explanations exist for each alert (key features that influenced the score).
There is ongoing collaboration with compliance officers who validate outputs.
Confirmed suspicious activity or false positives feed back into model re-training.
Could criminals adapt to the model and bypass detection?
Discuss that:
You regularly monitor for unusual patterns that become common.
A robust, retrained model can adapt to new tactics quickly.
You incorporate feedback loops so investigators flag new suspicious behaviors.
You cross-check with known red-flag typologies, ensuring you keep proven rules as a safety net.
How do you handle large data volume and real-time needs?
Explain:
You can use distributed processing frameworks (such as Spark) for feature engineering and training.
You batch process alerts at intervals that match the risk tolerance of the system (e.g. hourly or daily).
For critical high-value transactions, you can run the scoring engine in near real-time, using streaming technology if needed.
This solution combines traditional detection methods with a modern Machine Learning workflow. It prioritizes the highest-risk cases, reduces manual workloads, and adjusts to changing money laundering tactics.