
ML Case-study Interview Question: Balancing Delivery Supply/Demand Using LightGBM Forecasting and Optimization.


Browse all the ML Case-Studies here.
Case-Study question
A major on-demand delivery platform faces the challenge of keeping delivery times low and driver earnings high without passing extra costs to customers. The platform wants a system to balance supply of drivers and demand for orders. The system will forecast driver availability and order volume in local regions at specific times. It will then allocate incentives to encourage drivers to join during peak times. The platform uses a machine learning model to predict both supply and demand and couples these predictions with an optimization engine to decide where and when to offer incentives. Design a solution that addresses forecast accuracy, optimization under constraints, and uncertainty management. Propose a system architecture, discuss your choice of model, and explain how you would handle variations in data quality and evolving business goals.
Detailed Solution
Forecasting Requirement and Model Choice
The team reformulated forecasting as a regression problem. They used gradient boosting via LightGBM to predict driver hours and order demand per region-time unit. They aimed for minimal dependencies and a thriving community ecosystem. They needed to scale to thousands of regions and do counterfactual analysis by altering input features during inference. They also wanted to handle new regions with zero historical data by leveraging embedding or well-engineered features like traffic, population, or climate.
Data Causality and Missing Covariates
A direct correlation between high incentive and low driver availability might appear in the raw data if an omitted variable like holiday or weather was absent. The system avoided blindly learning wrong causal links by adding relevant inputs (holidays, weather) or bounding relationships via domain knowledge and controlled experimentation.
Granularity of Forecasting
They matched the forecast unit to the decision unit. They avoided daily forecasts if actions were sub-daily. Aggregating data over large time windows can reduce variance but can also mask undersupply or oversupply in specific time segments.
Optimization Approach
They used a mixed-integer programming engine with an objective of minimizing undersupply across region-time units under budget constraints. They encoded constraints to ensure only one incentive is used per region-time unit and capped total spend. They created flexible objective functions to favor growth or profitability.
Managing Uncertainty
They performed resampling around the predicted supply-demand gaps and computed expected undersupply levels. They avoided over-allocation in uncertain and volatile regions by incorporating probability distributions rather than point estimates.
Pipeline Reliability and Maintainability
They decoupled domain data pipelines to reduce failures from large dependency chains. They used primary data sources and limited transformations. They structured everything to make iterative experimentation and new feature testing faster. They used continuous integration and strong version controls.
Example Code Snippet (Training LightGBM)
import lightgbm as lgb
import pandas as pd
import numpy as np
# Suppose df has columns: features (X) and target (Y).
X = df.drop('target', axis=1)
Y = df['target']
lgb_train = lgb.Dataset(X, Y)
params = {
'objective': 'regression',
'metric': 'rmse',
'learning_rate': 0.05,
'num_leaves': 31
}
model = lgb.train(params, lgb_train, num_boost_round=1000)
# For counterfactual, create a modified input
X_counterfactual = X.copy()
X_counterfactual['incentive_value'] = X_counterfactual['incentive_value'] * 1.5
prediction_cf = model.predict(X_counterfactual)
They swapped one feature and measured the model’s response. That guided decisions on how different incentive levels impacted driver hours, subject to the caution that correlation does not always imply causation.
Variance Reduction Example
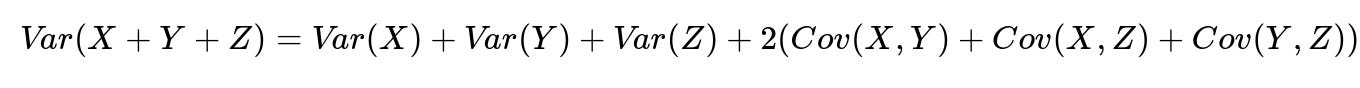
Var(X) is variance of X, Cov(X,Y) is covariance of X and Y. Aggregating random variables can reduce relative variance if they are not perfectly correlated. That can make a single aggregated forecast more accurate, but local imbalances may still appear.
Follow-up Questions
How would you separate the forecasting model from the optimization engine?
Decouple them. Produce unbiased predictions. Feed them into a solver that handles business constraints. Avoid hacking the model loss to fit budgets or cost minimization, because that can hide true demand patterns. Put logic about overshoot or undershoot tradeoffs inside the optimizer.
How do you ensure the model does not learn spurious correlations?
Include all relevant signals such as weather and major events. Constrain relationships through domain knowledge or rely on controlled experiments. Monitor predictions vs actual outcomes over holidays or storms and see if it consistently fails. Correct for these issues by reintroducing missing variables or adjusting the data pipeline.
How would you handle new regions with zero historical data?
Use city-level or region-level embeddings. Include features such as population, traffic patterns, merchant density, or climate. Transfer learned patterns from similar regions. Update with minimal historical data once the region goes live.
What techniques would you use to cope with changing data distributions?
Continuously retrain the model and monitor for concept drift. Retraining frequency depends on data shifts. Set up robust pipelines that update features daily or weekly. Run A/B tests to detect if model performance has dropped.
How do you validate correctness of optimization decisions in production?
Compare actual driver supply and order metrics with predicted outcomes. Run hold-out regions or times with alternative incentive strategies. Track resulting performance. Conduct small-scale experiments to measure if the optimization leads to the desired supply-demand balance.
How do you handle extremely volatile regions and low data volumes?
Group or cluster small regions into larger cohorts with similar traits. Use hierarchical approaches that borrow information across similar regions. Add uncertainty modeling in the optimizer to avoid large misallocations. Resample or bootstrap data to capture variance.
Would you consider any reinforcement learning approach here?
Yes. The system can learn a policy that reacts in real-time to new observations. However, building MIP-based solutions is often more transparent and easier to debug. RL can be explored for dynamic decision making if the system's state changes rapidly or if the reward function is complex.
How do you iterate on new features and ensure stable deployments?
Use version control and CI/CD pipelines. Test in a sandbox environment. Launch experiments that compare the new feature’s effect on real forecasts vs a baseline. Validate minimal distribution shifts. If stable, promote to production with real-time monitoring and alerts.
How would you handle a partial system failure in data pipelines?
Monitor data freshness. If data is stale or incomplete, switch to a failsafe baseline. That might default to a rule-based approach or a prior model. Maintain logs to quickly detect the root cause. Rapidly fix or roll back to known stable versions.