
ML Case-study Interview Question: Dynamic Node2Vec Embeddings for Scalable Blockchain Malicious Address Detection.


Browse all the ML Case-Studies here.
Case-Study question
A leading technology firm wants to implement a system that identifies potentially malicious blockchain addresses to protect users. They maintain a large blockchain transaction graph with billions of addresses and transactions flowing in real time. They seek a risk-scoring solution for each address, relying on address features, aggregate transactional behavior, and embeddings of the transaction graph. They also plan to update embeddings incrementally to handle newly added addresses. Design a method for computing a final risk score for each address, integrating both graph-based and behavioral features. Outline the end-to-end pipeline for data collection, feature engineering, model training, and inference. Propose ways to handle the massive scale of addresses and evolving nature of the blockchain, and explain key challenges and how you would address them.
Detailed Solution
The pipeline starts with gathering blockchain transaction data from trusted sources. The system ingests raw transactions and constructs a directed graph whose nodes are addresses and edges represent transactions from one address to another. Each node is enriched with behavior-based attributes: total incoming transactions, total outgoing transactions, average transaction amount, temporal patterns, and so on. A graph embedding approach augments these attributes with a structural representation, capturing relationships among nodes.
A dynamic Node2Vec approach handles the shifting blockchain graph, training embeddings incrementally as new addresses appear and existing addresses perform transactions. The training proceeds by generating random walks for each node, learning to predict context nodes within these walks through a skip-gram-like objective function. The key goal is to represent “neighbors” or addresses that frequently interact in similar ways with a comparable embedding.
How Node2Vec Learns Embeddings
Node2Vec modifies random walks to balance breadth-first and depth-first traversals through hyperparameters p (return parameter) and q (in-out parameter). The skip-gram setup maximizes the probability of seeing context nodes x in the random walk window around node u:
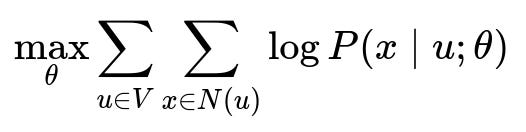
Here, V is the set of addresses (nodes), N(u) denotes the set of context nodes sampled from random walks around node u, and P(x | u; θ) is typically defined using a softmax over embeddings. θ represents the learned embedding parameters.
Each address gets an embedding vector learned from the walks. Once learned, these embeddings become part of the final feature set. They capture the address’s position in the transaction graph, revealing structural and transactional patterns often indicative of fraud rings or high-risk behaviors.
Handling Large-Scale Graphs
A distributed map-reduce process computes random walks in parallel. The system captures only delta nodes for each timestamp t. Each incremental training pass loads the previous model’s parameters and updates them with walks from the newly added transactions. This ensures scalability for massive networks with hundreds of millions or billions of addresses.
Risk Score Generation
A supervised model ingests two kinds of features: (1) Graph-based embeddings from Node2Vec. (2) Behavioral features derived from aggregated transaction histories. The model is trained on labeled data from confirmed fraudulent addresses or known safe addresses. Labels come from validated sources such as prior investigations. Various algorithms can be used, including gradient-boosted decision trees or neural network classifiers.
During inference, the model produces a numeric risk score (0 to 1). High-scoring addresses trigger alerts or hold transactions. This gating mechanism, combined with user-facing warnings, can shield users from suspicious counterparties.
Example Code Snippet for Incremental Embedding Training
# Assume spark or a similar framework for parallel jobs
import random
# A pseudo-routine showing how incremental walks might be generated
def generate_random_walks(delta_nodes, adjacency_list, p, q):
walks = []
for node in delta_nodes:
for _ in range(10): # random number of walks
walk = [node]
while len(walk) < 80: # walk length
current = walk[-1]
neighbors = adjacency_list[current]
if not neighbors:
break
next_node = random.choice(neighbors)
walk.append(next_node)
walks.append(walk)
return walks
# Next steps:
# 1. Load previous node2vec model weights
# 2. Use new random walks to continue training
# 3. Retrain/finetune skip-gram objective
The updated node embeddings are merged with behavioral features to train a risk prediction model. A hold-out set evaluates accuracy, precision, recall, and other metrics. The final model then provides the risk score for every address.
Potential Follow-Up Questions
1. How would you manage feature drift in a highly dynamic blockchain?
The embeddings adjust by retraining on new transactions, capturing shift in address relationships. The behavioral attributes are aggregated for rolling time windows to prevent stale statistics from overshadowing recent transaction patterns. If an address that was once benign becomes malicious, its transaction behavior changes. Rolling updates ensure the features reflect the latest state. Some models can be retrained offline on newly labeled data at regular intervals. This approach maintains alignment with the constantly shifting data distribution.
2. How do you select hyperparameters (p, q, walk lengths, embedding dimensions) for Node2Vec?
Grid searches on smaller representative subsets can tune these parameters. p and q balance how “broad” or “deep” the random walks go, and must be tested on historical data to see which yields the best predictive performance on known fraud addresses. Embedding dimension is usually chosen based on model complexity constraints and memory limits. The skip-gram window size can also be cross-validated to maximize performance for a held-out set of addresses with known labels.
3. How do you handle cold-start for newly emerged addresses with few transactions?
New addresses initially have sparse transaction data. Basic global statistics (e.g., typical transaction amounts for the blockchain) and partial embeddings from short random walks can initialize the new address. The model might also rely more on network-level features if a new address immediately interacts with known malicious nodes. Online updating strategies can refine an address’s embedding as soon as new transactions appear.
4. How do you ensure that your model is explainable to compliance officers?
Post-hoc interpretation methods help. For example, SHAP values highlight which features (embedding distances or aggregate transaction amounts) strongly influenced the predicted risk. If an address is flagged high-risk, the system might show which neighbors in the random walk had known fraud connections. Compliance teams can use this to understand the model’s reasoning.
5. Why might you prefer incremental learning over a complete retraining?
A full retraining of Node2Vec on billions of addresses is expensive and time-consuming. Incremental training reuses old embeddings and updates them with new data, saving computational overhead. It also keeps the model up-to-date more frequently. In a real-time environment, addresses and transactions arrive constantly. Continuous incremental learning ensures the system stays relevant without massive downtime for retraining.
6. How do you mitigate false positives that block legitimate users?
Threshold tuning is key. The risk score cutoff might be tuned to prioritize low false positives for a better user experience. High-risk addresses can trigger a secondary review or user warning instead of outright rejection. A multi-tier approach can categorize addresses into high, medium, and low-risk tiers. The labeling pipeline should be monitored to identify patterns where valid transactions are flagged, and subsequent refinements can reduce such errors.
7. How would you measure model success beyond typical metrics?
Monitoring real-world outcomes is crucial. Metrics include reduction in fraudulent transaction volume, fewer user complaints about blocked transactions, and the amount of user funds protected. Ongoing feedback loops with anti-fraud teams can indicate where the risk score works or fails, leading to continuous improvements in the model.
8. How do you prevent malicious actors from reverse-engineering the score to evade detection?
Exact thresholding logic is never exposed publicly. Rate-limiting or delayed responses to suspicious activities prevent rapid trial-and-error. Continual updates to the model and random walk sampling scheme add unpredictability. The system might also blend multiple detection signals, not solely the embedding-based model. These combined measures make it harder for attackers to consistently bypass risk checks.
9. Why use graph embeddings instead of just raw features like address frequency and total transaction counts?
Raw features ignore the broader network structure. An address that interacts with clusters of known fraudulent addresses might also be risky, even if its absolute transaction counts are moderate. Node2Vec embeddings capture that structural context. Certain fraud rings operate in patterns, and embeddings help encode those patterns at scale, allowing the model to detect more subtle relationships than raw features alone.
10. How do you approach maintaining data pipelines when on-chain transactions come in at high volume?
Distributed streaming frameworks can ingest transaction data in real-time and batch them at intervals for random walk generation. Systems like Apache Spark or Flink handle the parallelism for large data volumes. Careful partitioning of the transaction graph ensures that each worker can generate random walks on its assigned nodes efficiently. The resulting embeddings and feature sets are updated in a controlled manner, aligning with new blocks and transactions arriving on-chain.