
ML Case-study Interview Question: LLM-Based Internal Assistant: Secure Retrieval, Scaling, and Cross-Team Integration


Browse all the ML Case-Studies here.
Case-Study question
You are tasked with designing and scaling an internal Large Language Model-based AI assistant for a major e-commerce platform. The assistant must handle code reviews, debugging, summarization of internal documents and discussions, and help multiple teams across engineering, operations, recruiting, and marketing. The solution needs to support both a web interface and a chat interface within Slack. How would you build this system from end to end, ensure smooth adoption across teams, and address data privacy and scaling concerns?
Detailed Solution
Overview of the Approach
Start by integrating a reliable Large Language Model (LLM) with robust application programming interfaces. Use a proven provider for the model, ensuring it can handle extended context windows. Give the assistant capabilities to generate and debug code, summarize threads, and understand internal data and documents.
Initial Prototyping
Build a minimal web application for rapid testing. Allow text-based chats. Expose advanced features like keyboard shortcuts, code formatting, and model upgrades to adapt to long context windows. This initial phase focuses on developer needs.
Broadening to Non-Engineering Teams
Expand the user interface for recruiters, operations, and other departments. Provide prompt templates to lower the barrier for non-technical users. Let users share their conversation snippets. Add conversation search to help locate key insights.
Slack Integration
Enable the assistant to run within Slack channels and direct messages. Let users type commands like "@Assistant summarize" to produce a concise summary of lengthy discussions. Post the summary in the channel so everyone can see and validate it. Keep the assistant’s response format consistent with typical Slack threads.
Knowledge Retrieval and Code Execution
Implement retrieval mechanisms to give the assistant access to internal knowledge bases. Store documents and text references as embedding vectors. When the user queries data, compute vector similarities to find the most relevant chunks.
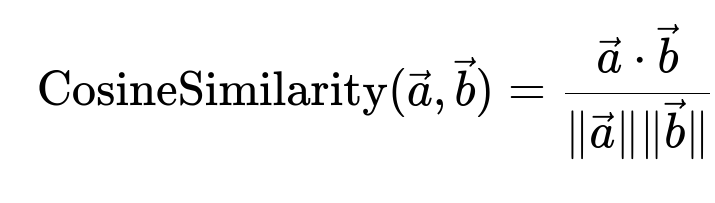
Here:
vec(a) and vec(b) are embedding vectors for a document and a query.
vec(a) · vec(b) is the dot product of these vectors.
||vec(a)|| is the magnitude of vec(a), ||vec(b)|| is the magnitude of vec(b).
Integrate code execution so the assistant can run internal scripts, check logs, or retrieve data from database systems if permissions are granted. This provides additional power to automate routine tasks.
Data Privacy and Security
Send user queries to the model with privacy safeguards. Strip sensitive information. Mask personal identifiers or proprietary details as needed. Enforce single sign-on authentication and role-based access control. Ensure the system logs queries for auditing.
Scaling the Infrastructure
Auto-scale the backend to handle traffic spikes. Cache certain AI responses if queries are repeated often. Adopt asynchronous job processing for large jobs, such as summarizing massive documents or codebases. Continuously monitor usage with dashboards.
Example Code Snippet
Below is a simple Python snippet illustrating a retrieval workflow. It takes a user query, transforms it into an embedding, looks up similar documents, and returns them for final summarization by the LLM:
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def retrieve_documents(query_embedding, document_embeddings, top_k=3):
similarities = []
for doc_id, doc_embedding in document_embeddings.items():
sim = cosine_similarity(query_embedding, doc_embedding)
similarities.append((doc_id, sim))
similarities.sort(key=lambda x: x[1], reverse=True)
return [doc_id for doc_id, _ in similarities[:top_k]]
# query_embedding would be generated by the LLM or an embeddings API
# document_embeddings is a pre-computed dict {doc_id: embedding_vector}
Future Expansion
Allow the assistant’s data retrieval layer to integrate with user-facing workflows. Expose more application programming interfaces. Let teams build specialized plug-ins to handle domain-specific tasks. Keep usage logs for improvements.
Follow-up Question 1
How would you handle prompt engineering so that different teams can easily tailor the assistant to their specific tasks without rewriting prompts every time?
Answer and Explanation Create a shared prompt template library. Let users store and share prompts within the organization. Implement a rating or starring system to rank prompt effectiveness. For each domain (engineering, marketing, operations), let domain experts contribute prompts and refine them. Encourage short instructions and examples within prompts. Provide an interface so users can pick from these templates quickly. Store them in a dedicated database to ensure discoverability.
Follow-up Question 2
What strategies do you recommend to integrate continuous feedback, so the assistant’s responses keep improving over time?
Answer and Explanation Incorporate a user feedback mechanism that allows employees to mark responses as helpful or not helpful. Let them annotate or correct results, especially for complex code or important summaries. Aggregate this feedback in a dedicated storage system. Periodically retrain or fine-tune with these annotated examples if the model or provider allows custom training. Monitor usage logs and refine prompt templates and embeddings accordingly.
Follow-up Question 3
How would you ensure that the assistant does not leak confidential information or reveal sensitive data when it summarizes Slack conversations and internal documents?
Answer and Explanation Implement content filters that intercept requests and responses before they leave the system. Use role-based access control checks to confirm user identity and permissions. Redact sensitive fields like email addresses or phone numbers. Consider a masked approach where the assistant replaces sensitive entities with placeholders. For logs, store only anonymized or minimal parts of the prompt. Work closely with security teams to maintain compliance with the organization’s standards.
Follow-up Question 4
If memory constraints become an issue, how would you scale the system’s context window and deal with large documents?
Answer and Explanation Break large documents into smaller embeddings chunks. Use chunk-based retrieval with vector similarity. Only deliver relevant chunks to the LLM at a time, ensuring the prompt does not exceed token limits. Automatically switch to a larger context model if needed, or compress content by summarizing each chunk before combining them. Keep an eye on response quality to confirm that minimal context is lost.
Follow-up Question 5
How do you see your approach evolving if the company wants the assistant to directly execute more automated tasks, like coding pipelines or database modifications, beyond just summarizing or generating text?
Answer and Explanation Create a controlled environment where the assistant runs approved scripts or interacts with a safe software development kit. Use an execution engine that enforces strict permission controls. For each command, confirm user authorization. Log all actions. Consider a staging environment that the assistant can operate on first, so any changes can be reviewed before production deployment.
Follow-up Question 6
What are the key metrics you would track to measure the success of this AI assistant across different teams?
Answer and Explanation Monitor daily active users, query volume, average response latency, and usage across each department. Track how often users copy generated code or text. Measure feedback ratings to see how often responses are marked as helpful or accurate. Watch adoption trends, such as weekly active users, to see if usage grows. Track average time saved per user. Assess if issues like security flags or user complaints emerge.